青海城乡和住房建设厅网站南京百度
Westwood算法控制的是在从快速恢复阶段退出时的拥塞窗口的值。原理上讲,这时的窗口值应该是一个不包括队列缓存在内的BDP,即最大带宽与最小RTT的乘积。
问题是如何求最大带宽。
标准的Westwood算法做的非常粗糙,它将一个TCP连接的生命周期分解为一段一段的采样周期,每一个采样周期内采集被ACK的字节数,然后除以采样周期的间隔,结果做低通滤波(其实就是移动指数平均),就是带宽。
我们来看一下Westwood是如何在采样周期内采集ACK字节数的。
然而,4.9版本之前的内核对于Linux的TCP实现,在开放给拥塞控制回调的接口中,只能通过当前的snd_una与上次记录的snd_una之间的差值来估算被ACK的字节数,说“估算”这个词的意思是,在拥塞控制回调中,关于SACK的信息会丢失。
比如说收到一个ACK,如果它是重复的ACK,那么在拥塞控制回调中将无法取到任何其携带的SACK信息。虽然说一个重复的ACK可能携带了一大段SACK,然而对于拥塞控制回调而言,它看到的只是一个没有推进snd_una的ACK。本来,携带SACK的ACK段是想告诉拥塞模块对端其实收到了N个字节的数据,只不过没有按序,按照BDP的观点,这些乱序的数据也应该计入BDP的,然而却由于拥塞模块听不到这个信息而被忽略。我们来看一下这个逻辑:
可见,上述针对ACK数据的计数是极其粗糙的!
然而这不是Westwood的错,这是Linux TCP实现的错!
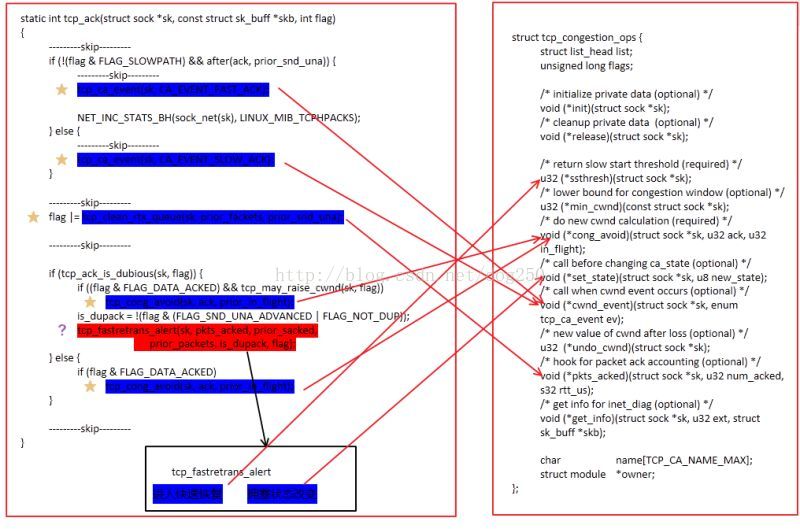
可以看到,只有在特定的点,才会进入外挂的拥塞控制模块的回调函数,对于在非Open的拥塞控制状态中,系统会调用私有的tcp_fastretrans_alert函数,该函数中就是例行的PRR降窗过程和重传逻辑了,无法被拥塞控制模块控制。
我认为,抛开BBR算法本身不谈,以上逻辑的引入是BBR为Linux TCP实现带来的最有价值礼物。这个大礼包中最重要的也许要算struct rate_sample参数了。我们看下这个参数包含什么:
已经携带了足够的注释,我就不解释了。对于Westwood而言,最重要的或许是acked_sacked参数了。
好了,现在开始修改Westwood的实现:
1.去掉既有的带宽统计逻辑:
2.1.加入一个新的回调
添加一个新回调的用意在于不改变原有的BBR以及我修改过的CDG等算法的调用逻辑,因此在tcp_cong_control中需要增加对该回调的调用:
2.2.实现新增的回调
以上就是对Westwood的修改,使它对带宽的统计更加精确。
问题是如何求最大带宽。
标准的Westwood算法做的非常粗糙,它将一个TCP连接的生命周期分解为一段一段的采样周期,每一个采样周期内采集被ACK的字节数,然后除以采样周期的间隔,结果做低通滤波(其实就是移动指数平均),就是带宽。
我们来看一下Westwood是如何在采样周期内采集ACK字节数的。
然而,4.9版本之前的内核对于Linux的TCP实现,在开放给拥塞控制回调的接口中,只能通过当前的snd_una与上次记录的snd_una之间的差值来估算被ACK的字节数,说“估算”这个词的意思是,在拥塞控制回调中,关于SACK的信息会丢失。
比如说收到一个ACK,如果它是重复的ACK,那么在拥塞控制回调中将无法取到任何其携带的SACK信息。虽然说一个重复的ACK可能携带了一大段SACK,然而对于拥塞控制回调而言,它看到的只是一个没有推进snd_una的ACK。本来,携带SACK的ACK段是想告诉拥塞模块对端其实收到了N个字节的数据,只不过没有按序,按照BDP的观点,这些乱序的数据也应该计入BDP的,然而却由于拥塞模块听不到这个信息而被忽略。我们来看一下这个逻辑:
static inline u32 westwood_acked_count(struct sock *sk)
{const struct tcp_sock *tp = tcp_sk(sk);struct westwood *w = inet_csk_ca(sk);w->cumul_ack = tp->snd_una - w->snd_una;/* If cumul_ack is 0 this is a dupack since it's not moving* tp->snd_una.*/if (!w->cumul_ack) {// 如果当前ACK是没有推进snd_una的重复ACK,仅计入一个段,忽略SACK带来的BDP排空。w->accounted += tp->mss_cache;w->cumul_ack = tp->mss_cache;}if (w->cumul_ack > tp->mss_cache) {/* Partial or delayed ack */if (w->accounted >= w->cumul_ack) {w->accounted -= w->cumul_ack;w->cumul_ack = tp->mss_cache;} else {w->cumul_ack -= w->accounted;w->accounted = 0;}}w->snd_una = tp->snd_una;return w->cumul_ack;
}可见,上述针对ACK数据的计数是极其粗糙的!
然而这不是Westwood的错,这是Linux TCP实现的错!
后来在Linux内核升级时,将重传逻辑从tcp_fastretrans_alert中剥离了出来,但是那只是代码结构的调整,整个非Open状态依然是拥塞控制模块所不能干预的。
也许你会说,可以在tcp_ca_event回调中进行非Open状态的拥塞控制,事实上Westwood等算法也是这么做的,但是即便如此,tcp_ca_event回调的传入参数依然无法满足Westwood的真实所需。但是BBR算法的引入,改变了这一切:
static void tcp_cong_control(struct sock *sk, u32 ack, u32 prior_in_flight, u32 acked_sacked,int flag, const struct rate_sample *rs)
{const struct inet_connection_sock *icsk = inet_csk(sk);// 新增了一个cong_control回调函数。在拥塞状态无关的情况下无条件接管所有的逻辑。if (icsk->icsk_ca_ops->cong_control) {icsk->icsk_ca_ops->cong_control(sk, rs);// 然后直接返回。return;}// 常规的逻辑。类似CUBIC等算法均会调用常规逻辑。if (tcp_in_cwnd_reduction(sk)) {/* Reduce cwnd if state mandates */tcp_cwnd_reduction(sk, acked_sacked, 1);} else if (tcp_may_raise_cwnd(sk, flag)) {/* Advance cwnd if state allows */tcp_cong_avoid(sk, ack, prior_in_flight);}tcp_update_pacing_rate(sk);
}我认为,抛开BBR算法本身不谈,以上逻辑的引入是BBR为Linux TCP实现带来的最有价值礼物。这个大礼包中最重要的也许要算struct rate_sample参数了。我们看下这个参数包含什么:
/* A rate sample measures the number of (original/retransmitted) data* packets delivered "delivered" over an interval of time "interval_us".* The tcp_rate.c code fills in the rate sample, and congestion* control modules that define a cong_control function to run at the end* of ACK processing can optionally chose to consult this sample when* setting cwnd and pacing rate.* A sample is invalid if "delivered" or "interval_us" is negative.*/
struct rate_sample {struct skb_mstamp prior_mstamp; /* starting timestamp for interval */u32 prior_delivered; /* tp->delivered at "prior_mstamp" */s32 delivered; /* number of packets delivered over interval */long interval_us; /* time for tp->delivered to incr "delivered" */long rtt_us; /* RTT of last (S)ACKed packet (or -1) */int losses; /* number of packets marked lost upon ACK */u32 acked_sacked; /* number of packets newly (S)ACKed upon ACK */u32 prior_in_flight; /* in flight before this ACK */bool is_app_limited; /* is sample from packet with bubble in pipe? */bool is_retrans; /* is sample from retransmission? */
};已经携带了足够的注释,我就不解释了。对于Westwood而言,最重要的或许是acked_sacked参数了。
好了,现在开始修改Westwood的实现:
1.去掉既有的带宽统计逻辑:
static void tcp_westwood_event(struct sock *sk, enum tcp_ca_event event)
{struct tcp_sock *tp = tcp_sk(sk);struct westwood *w = inet_csk_ca(sk);switch (event) {/** 不再需要*//*case CA_EVENT_FAST_ACK:westwood_fast_bw(sk);break;*/case CA_EVENT_COMPLETE_CWR:tp->snd_cwnd = tp->snd_ssthresh = tcp_westwood_bw_rttmin(sk);break;case CA_EVENT_LOSS:tp->snd_ssthresh = tcp_westwood_bw_rttmin(sk);/* Update RTT_min when next ack arrives */w->reset_rtt_min = 1;break;/** 不再需要*//*case CA_EVENT_SLOW_ACK:westwood_update_window(sk);w->bk += westwood_acked_count(sk);update_rtt_min(w);break;*/default:/* don't care */break;}
}2.1.加入一个新的回调
static struct tcp_congestion_ops tcp_westwood __read_mostly = {.init = tcp_westwood_init,.ssthresh = tcp_reno_ssthresh,.cong_collect = westwood_collect,.cong_avoid = tcp_reno_cong_avoid,...添加一个新回调的用意在于不改变原有的BBR以及我修改过的CDG等算法的调用逻辑,因此在tcp_cong_control中需要增加对该回调的调用:
static void tcp_cong_control(struct sock *sk, u32 ack, u32 prior_in_flight, u32 acked_sacked,int flag, const struct rate_sample *rs)
{const struct inet_connection_sock *icsk = inet_csk(sk);// 新增了一个cong_control回调函数。在拥塞状态无关的情况下无条件接管所有的逻辑。if (icsk->icsk_ca_ops->cong_control) {icsk->icsk_ca_ops->cong_control(sk, rs);// 然后直接返回。return;}if (icsk->icsk_ca_ops->cong_collect) {icsk->icsk_ca_ops->cong_collect(sk, rs);// 并不返回。fall through!}// 常规的逻辑。类似CUBIC等算法均会调用常规逻辑。...
}2.2.实现新增的回调
void westwood_collect(struct sock *sk, struct rate_sample *rs)
{struct tcp_sock *tp = tcp_sk(sk);struct westwood *w = inet_csk_ca(sk);westwood_update_window(sk);// 使用实实在在的acked_sacked计数,而不是估计计数w->bk += rs->acked_sacked * tp->mss_cache;update_rtt_min(w);}以上就是对Westwood的修改,使它对带宽的统计更加精确。