菏泽网站建设网站优化关键词排名
作者:João Duarte
Grok(动词)直觉地或同理心地理解(某事)。
解析日志数据时最常见的任务之一是将原始文本行分解为一组其他工具可以操作的结构化字段。 如果你使用的是 Elastic Stack,则可以利用 Elasticsearch 的聚合和 Kibana 的可视化,从日志中提取的信息(如 IP 地址、时间戳和域特定数据)中回答业务和运营问题。
对于 Logstash,此解构工作由 logstash-filter-grok 执行,这是一个过滤器插件,可帮助你描述日志格式的结构。
有超过 200 种可用的 grok 模式,它们抽象了诸如 IPv6 地址、UNIX 路径和月份名称等概念。 为了匹配具有以下格式的行:
2016-09-19T18:19:00 [8.8.8.8:prd] DEBUG this is an example log message使用 grok 库,只需组合一些模式即可:
%{TIMESTAMP_ISO8601:timestamp} \[%{IPV4:ip}:%{WORD:environment}\] %{LOGLEVEL:log_level} %{GREEDYDATA:message}
如上所示,解析的结果为:
{"log_level": "DEBUG","environment": "prd","message": "this is an example log message","ip": "8.8.8.8","timestamp": "2016-09-19T18:19:00"
}简单吧?
是的!
太棒了! 我们在这里完成了吗? 不! 因为...
“我正在使用 grok,它超级慢!!”
这是一个很常见的说法! 性能是社区经常提出的一个话题,因为用户或客户通常会创建一个 grok 表达式,这将大大减少 Logstash 管道每秒处理的事件数。
如前所述,grok 模式是正则表达式,因此该插件的性能会受到正则表达式引擎行为的严重影响。 在接下来的章节中,我们将提供一些关于在创建 grok 表达式以匹配你的日志行时该做什么和不该做什么的指南。
测量,测量,测量
为了在 grok 表达式设计期间验证决策和实验,我们需要一种方法来快速测量两个或多个表达式之间的性能。 为此,我创建了一个小的 jruby 脚本,它直接使用 logstash-filter-grok 插件,绕过 Logstash 管道。
您可以在此处获取此脚本。 我们将使用它来收集性能数据来验证(或颠覆!)我们的假设。
当心 grok 匹配失败时的性能影响
尽管了解你的 grok 模式与日志条目匹配的速度有多快非常重要,但了解不匹配时会发生什么也很重要。 成功的比赛可能与不成功的比赛表现截然不同。
当 grok 无法匹配事件时,它会为事件添加标签。 默认情况下,此标记为 _grokparsefailure。
然后,Logstash 允许你将这些事件路由到可以对其进行计数和审查的地方。 例如,你可以将所有失败的匹配项写入一个文件:
input { # ... }
filter {grok {match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{IPV4:ip};%{WORD:environment}\] %{LOGLEVEL:log_level} %{GREEDYDATA:message}" }}
}
output {if "_grokparsefailure" in [tags] {# write events that didn't match to a filefile { "path" => "/tmp/grok_failures.txt" }} else {elasticsearch { }}
}如果你发现有多个模式匹配失败,你可以对这些行进行基准测试并找出它们对管道吞吐量的影响。
我们现在将使用 grok 表达式来解析 Apache 日志行并研究其行为。 首先,我们从一个示例日志条目开始:
220.181.108.96 - - [13/Jun/2015:21:14:28 +0000] "GET /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
并使用下面的 grok 模式来匹配它:
%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}
现在,我们将成功匹配的匹配速度与其他三个不符合格式的日志条目进行比较,无论是在行的开头、中间还是结尾:
# beginning mismatch - doesn't start with an IPORHOST
'tash-scale11x/css/fonts/Roboto-Regular.ttf HTTP/1.1" 200 41820 "http://semicomplete.com/presentations/logs'
# middle mismatch - instead of an HTTP verb like GET or PUT there's the number 111
'220.181.108.96 - - [13/Jun/2015:21:14:28 +0000] "111 /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'
# end mismatch - the last element isn't a quoted string, but a number
'220.181.108.96 - - [13/Jun/2015:21:14:28 +0000] "GET /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" 1'
这些日志行使用开头描述的脚本进行了基准测试,结果如下所示:
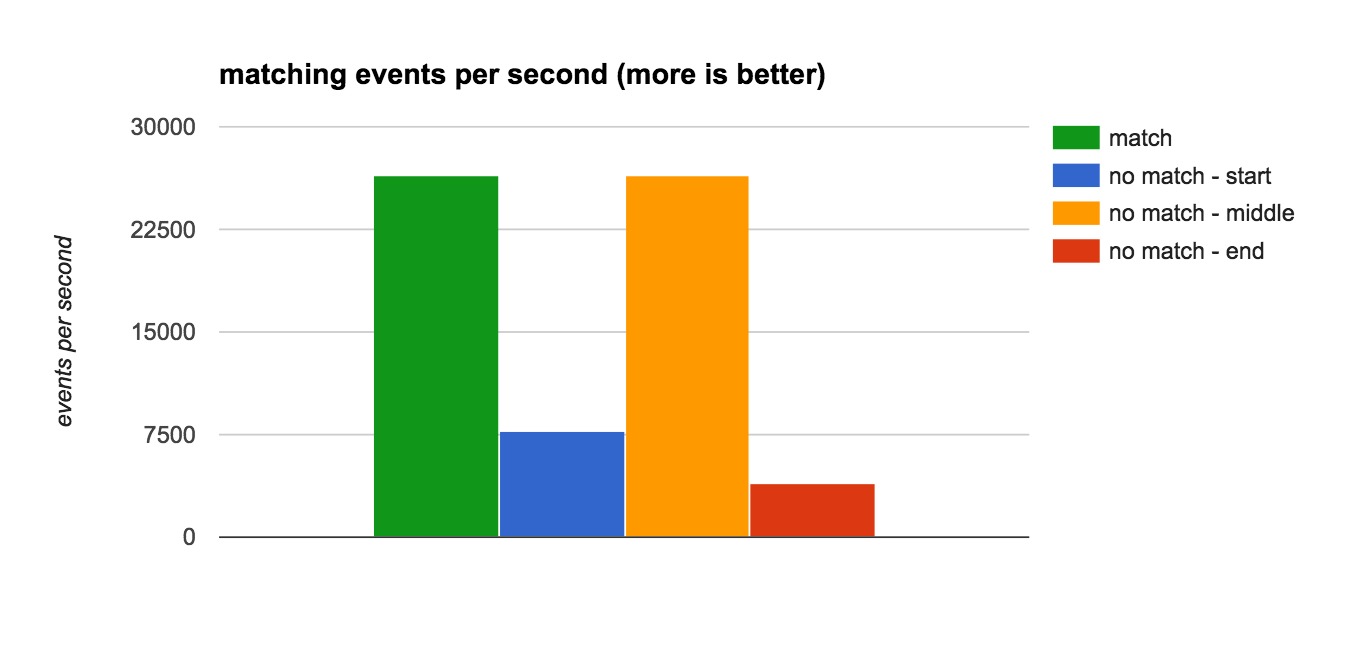
我们可以看到,对于这个 grok 表达式,根据不匹配的位置,检查一行不匹配所花费的时间可能比常规(成功)匹配慢 6 倍。 这有助于解释有关 grok 在行不匹配时最大化 CPU 使用率的用户报告,例如 https://github.com/logstash-plugins/logstash-filter-grok/issues/37。
我们对于它可以做些什么呢?
更快失败,设定锚点(Anchors)
因此,既然我们知道匹配失败对管道的性能是危险的,我们就需要修复它们。 在正则表达式设计中,你可以为正则表达式引擎做的最好的事情就是减少它需要做的猜测量。 这就是通常避免使用 greedy 模式的原因,但我们稍后会回过头来讨论这个问题,因为有一个更简单的更改可以改变你的模式的匹配方式。
让我们回到可爱的 Apache 日志行……
220.181.108.96 - - [13/Jun/2015:21:14:28 +0000] "GET /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
… 由下面的 grok 模式解析:
%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}
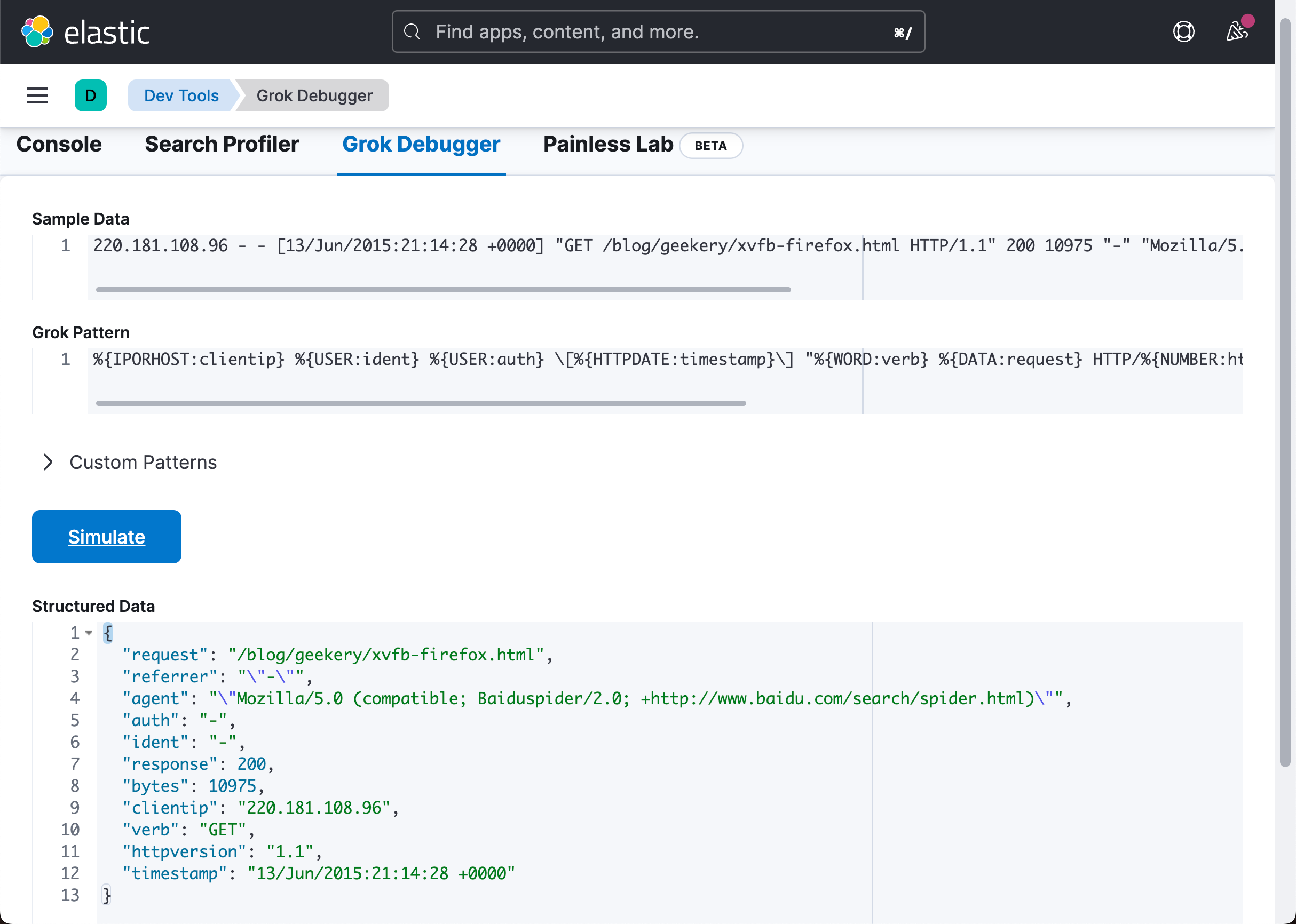
由于 grok 插件用户的自然期望,存在一个显而易见的性能问题:假设我们编写的 grok 表达式从头到尾只匹配我们的日志行。 实际上,grok 被告知的是 “在一行文本中找到这个元素序列”。
等等,什么? 没错,“一行文字之内”。 这意味着诸如下面的一行:
OMG OMG OMG EXTRA INFORMATION 220.181.108.96 - - [13/Jun/2015:21:14:28 +0000] "GET /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" OH LOOK EVEN MORE STUFF
…仍然会匹配 grok 模式! 好消息是修复很简单,我们只需要添加几个锚点 Anchors!
锚点允许你将正则表达式固定到字符串的特定位置。 通过向我们的 grok 表达式添加行锚点(^ 和 $)的开始和结束,我们确保我们只会将这些模式与整个字符串从开始到结束进行匹配,而不是其他任何内容。
这在匹配失败的情况下非常重要。 如果锚点不在相应的位置并且正则表达式引擎无法匹配一行,它将开始尝试在初始字符串的子字符串中查找模式,因此我们在上面看到的性能下降。
因此,为了查看性能影响,我们将以前的表达式与新表达式进行了基准测试,现在使用锚点:
^%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}$
以下是结果:
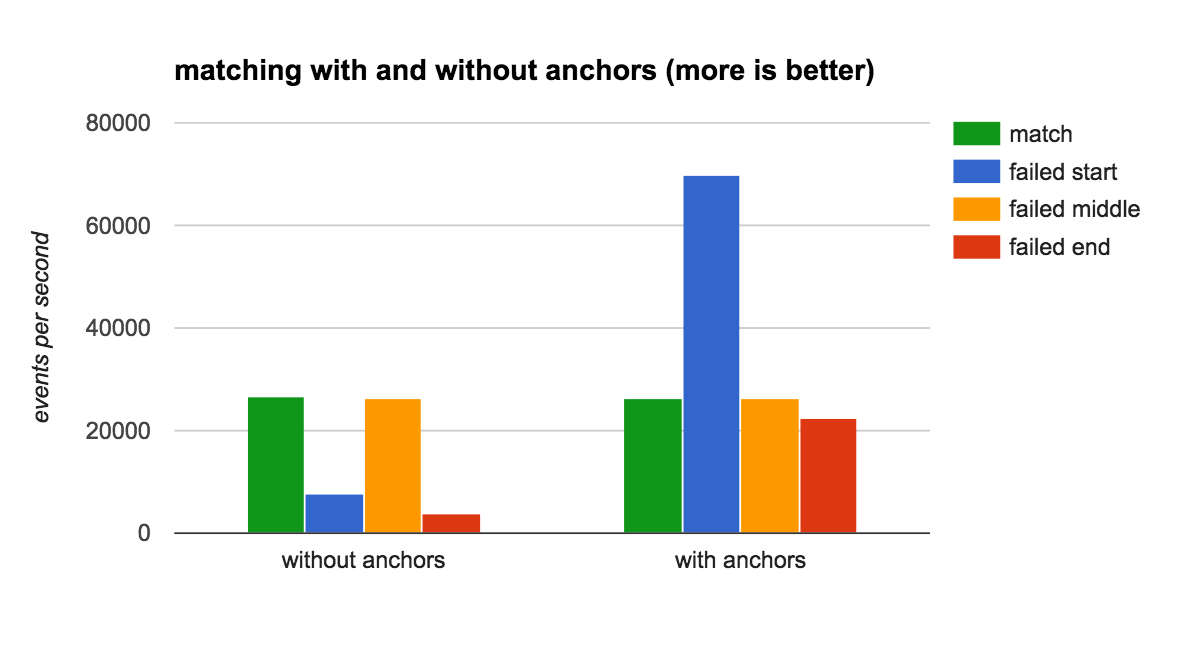
对于不匹配的场景,这是一个非常显着的行为变化! 我们不仅消除了中端场景中的巨大性能下降,而且还使初始匹配失败检测速度提高了约 10 倍。 太棒了!
小心匹配相同的东西两次
你可能会想说:“好吧,我的所有行的格式都正确,所以我们没有匹配失败”,但事实可能并非如此。
随着时间的推移,我们已经看到了一种非常常见的 grok 使用模式,尤其是当来自多个应用程序的行通过单个网关(如 syslog)为所有消息添加一个公共标头时。 让我们举个例子:假设我们有三个使用 “common_header: payload” 格式记录日志的应用程序:
Application 1: '8.8.8.8 process-name[666]: a b 1 2 a lot of text at the end'
Application 2: '8.8.8.8 process-name[667]: a 1 2 3 a lot of text near the end;4'
Application 3: '8.8.8.8 process-name[421]: a completely different format | 1111'
一个常见的 grok 设置是在一个 grok 中匹配三种格式:
grok {"match" => { "message => ['%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{WORD:word_1} %{WORD:word_2} %{NUMBER:number_1} %{NUMBER:number_2} %{DATA:data}','%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{WORD:word_1} %{NUMBER:number_1} %{NUMBER:number_2} %{NUMBER:number_3} %{DATA:data};%{NUMBER:number_4}','%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{DATA:data} \| %{NUMBER:number}'] }
}现在请注意,即使你的应用程序正确记录,grok 仍会按顺序尝试将传入的日志行与三个表达式进行匹配,并在第一个匹配时中断。
这意味着确保我们尽可能快地跳到正确的仍然很重要,因为应用程序 2 总是有一个匹配失败,应用程序 3 总是有两个匹配失败。
我们经常看到的第一种策略是对 grok 匹配进行分层:首先匹配标头,覆盖消息字段,然后仅匹配正文:
filter {grok {"match" => { "message" => '%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{GREEDYDATA:message}' },"overwrite" => "message"}grok {"match" => { "message" => ['%{WORD:word_1} %{WORD:word_2} %{NUMBER:number_1} %{NUMBER:number_2} %{GREEDYDATA:data}','%{WORD:word_1} %{NUMBER:number_1} %{NUMBER:number_2} %{NUMBER:number_3} %{DATA:data};%{NUMBER:number_4}','%{DATA:data} \| %{NUMBER:number}'] }}
)仅此一项就提供了一个有趣的性能提升,匹配线的速度比初始方法快 2.5 倍。 但是,如果我们添加其他锚点呢?
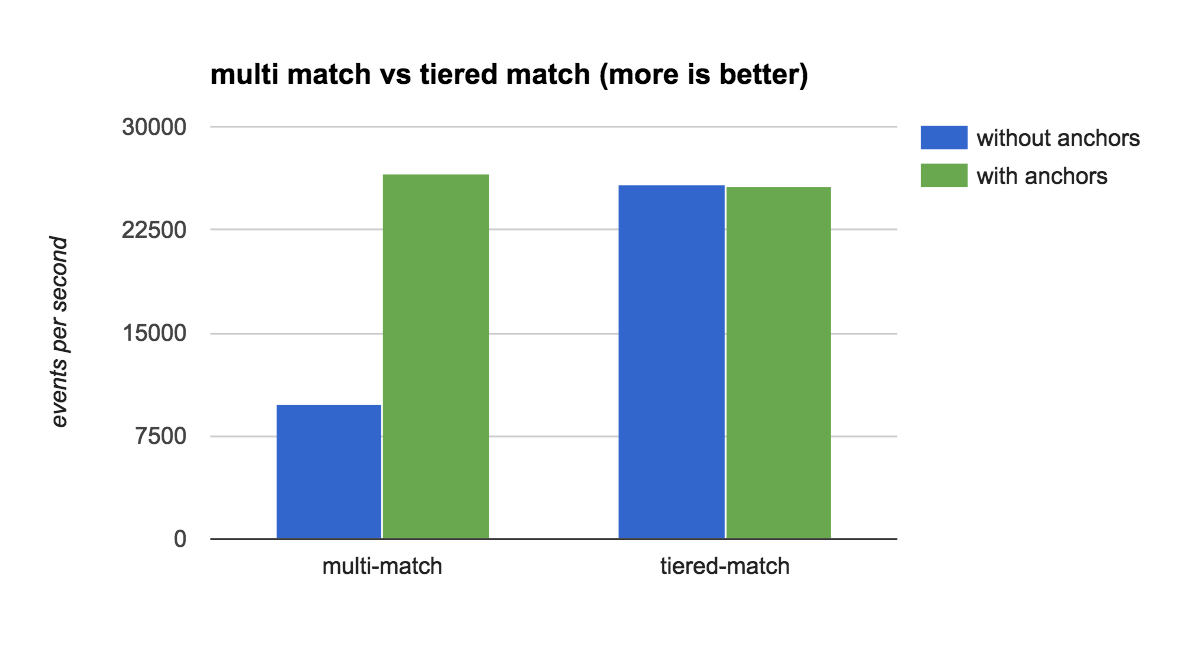
有趣的! 添加锚点使两种架构表现同样出色! 事实上,由于大大提高了失败的匹配性能,我们最初的单一 grok 设计性能略好,因为执行的匹配少了一个。
好的,那么我怎么知道事情进展不顺利呢?
我们已经得出结论,监控 “_grokparsefaiure” 事件的存在是必不可少的,但你还可以做更多的事情:
从 grok 插件的 3.2.0 版本开始,有几个设置可以帮助你了解事件何时需要很长时间才能匹配(或无法匹配)。 使用 timeout_millis 和 tag_on_timeout 可以为 grok 匹配的执行设置上限时间限制。 如果达到此限制,匹配将中断,事件默认标记为 _groktimeout。
使用我们之前介绍的相同条件策略,你可以将这些事件重定向到文件或 elasticsearch 中的不同索引以供以后分析。
在指标上下文中,我们将在 Logstash 5.0 中引入的另一个非常酷的功能是能够提取有关管道性能的数据,最重要的是,每个插件的统计数据。 当 Logstash 运行时,你可以查询其 API 端点并查看 Logstash 在插件上花费了多少累计时间:
$ curl localhost:9600/_node/stats/pipeline?pretty | jq ".pipeline.plugins.filters"
[{"id": "grok_b61938f3833f9f89360b5fba6472be0ad51c3606-2","events": {"duration_in_millis": 7,"in": 24,"out": 24},"failures": 24,"patterns_per_field": {"message": 1},"name": "grok"},{"id": "kv_b61938f3833f9f89360b5fba6472be0ad51c3606-3","events": {"duration_in_millis": 2,"in": 24,"out": 24},"name": "kv"}
]有了这些信息,你就可以看到 grok 的 “durationinmillis” 是否在快速增长,以及失败次数是否在增加,这可以作为一个警告标志,表明某些模式设计不当或消耗的时间超过预期。
结论
希望这篇博文能帮助你了解 grok 的行为方式以及如何提高其吞吐量。 总结我们的结论:
- 匹配失败时,Grok 可能表现不佳;
- 监控 _grokparsefailures 的发生,然后对它们的成本进行基准测试;
- 使用 ^ 和 $ 等锚点来消除歧义并帮助正则表达式引擎;
- 如果你不使用锚点,则分层匹配会提高性能,否则请不要烦恼。 如有疑问,请测量!
- 使用超时设置或 Metrics API 可以让你更好地了解 grok 的行为方式,并作为性能分析的起点。