web网站开发与实现深圳网站设计公司排行
基于requests模块构建免费代理IP池
前言
此篇文章中介绍基于requests模块,实现对在响应内容中嵌入JS,真实的url地址进行跳转后数据的爬取,并以爬取行政区划代码数据为例进行讲解。
正文
1、需求梳理
抓取民政部网站最新行政区划代码
一级页面:

二级页面:

2、爬虫思路
-
确认所抓数据在响应内容中是否存在
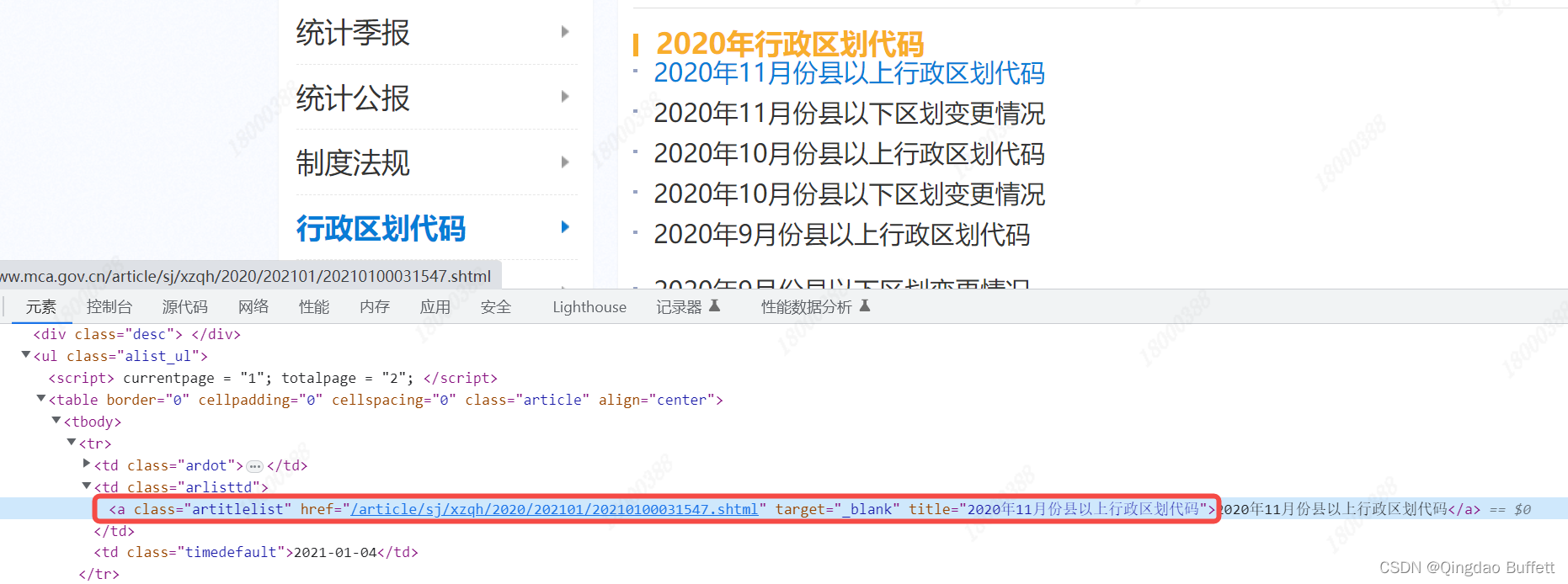
一级页面抓取数据:
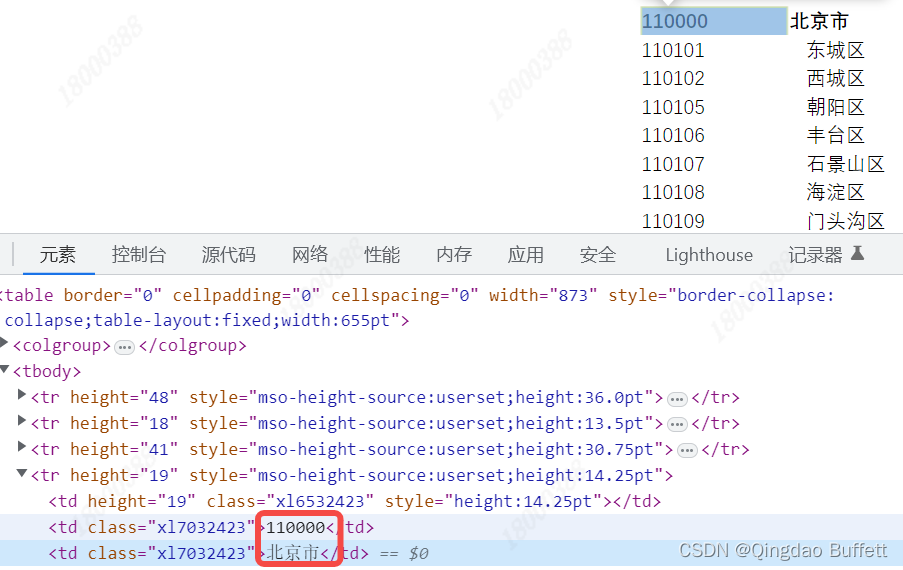
二级页面抓取数据:
-
分析url地址规律
一级页面的url地址:https://www.mca.gov.cn/article/sj/xzqh/2020/
二级页面的url地址:https://www.mca.gov.cn/article/sj/xzqh/2020/2020/202101041104.html
注意:获取二级页面的url地址时,因为网站加入了反爬机制,在响应内容中嵌入了JS,所以url地址会进行跳转,在一级页面中获取的url地址并不是真实的url地址

从上面的动图中可以看到:url地址从https://www.mca.gov.cn//article/sj/xzqh/2020/202101/20210100031547.shtml跳转成了https://www.mca.gov.cn/article/sj/xzqh/2020/2020/202101041104.html
那么应该如何获取二级页面真实的url地址呢?
本文采用的方法是:在程序运行时打印二级页面的响应内容,在响应内容中Ctrl+F 寻找 url地址(https://www.mca.gov.cn/article/sj/xzqh/2020/2020/202101041104.html)

-
写xpath表达式 & re正则表达式
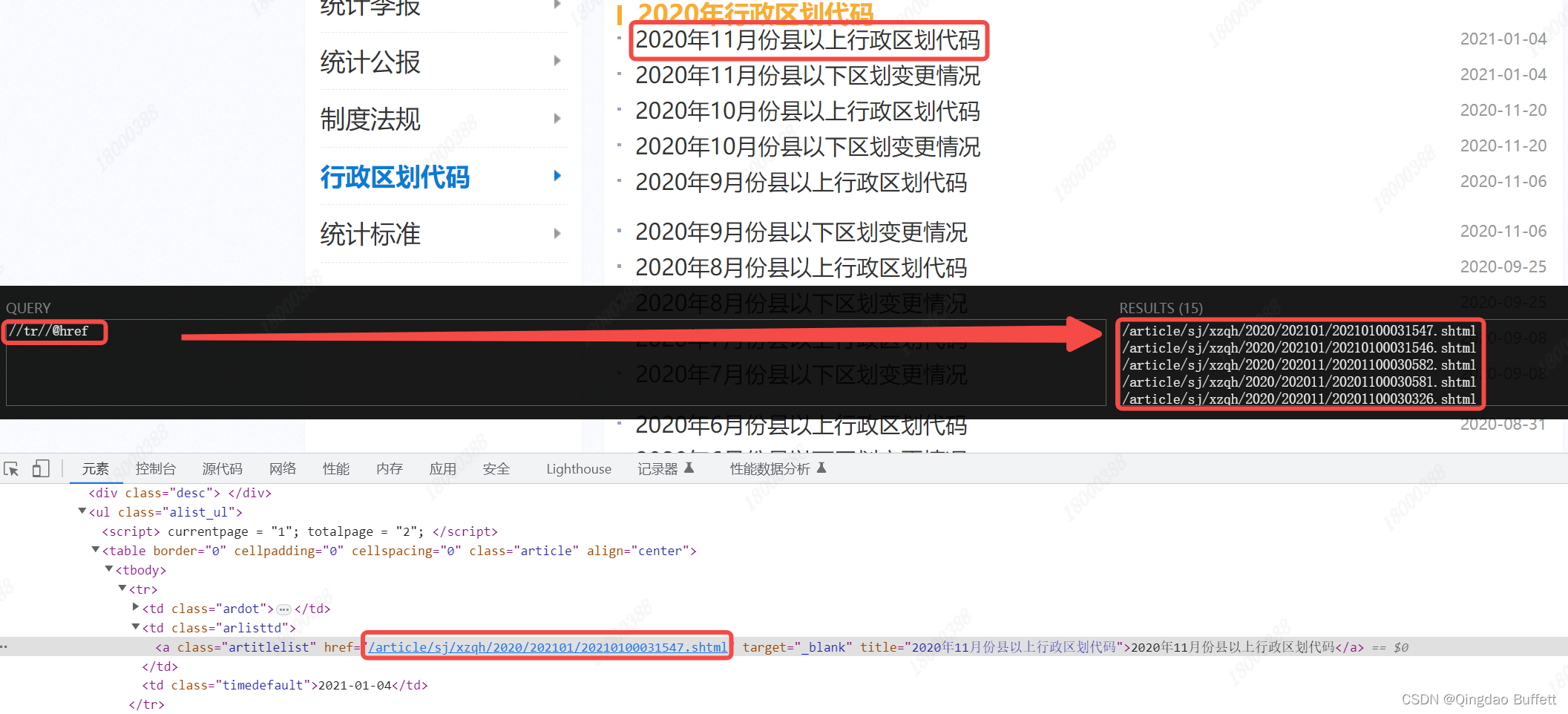
一级页面的xpath表达式://tr//@href

二级页面的re表达式:window.location.href="(.*?)
- 编写程序框架、完善程序
详情见3、程序实现
3、程序实现
- 初始化函数
def __init__(self):self.url = 'https://www.mca.gov.cn/article/sj/xzqh/2020/' # url地址
- 功能函数1:获取html
def get_html(self, url):"""function: 功能函数1:获取htmlin: url:url地址out: html:返回响应内容return: html:返回响应内容others: Func1:Get HTML"""headers = {'User-Agent': UserAgent().random} # 构建随机请求头html = requests.get(url=url, headers=headers).text # get方法获取响应内容return html
- 功能函数2:xpath解析提取数据
def xpath_func(self, html, xpath_bds):"""function: 功能函数2:xpath解析提取数据in: html:响应内容xpath_bds:xpath表达式out: r_list:返回匹配内容return: r_list:返回匹配内容others: """p = etree.HTML(html) # 创建解析对象r_list = p.xpath(xpath_bds) # 解析对象调用xpath表达式return r_list # 返回匹配内容
- 逻辑函数
def parse_html(self):"""function: 逻辑函数1、向主页发请求,提取最新月份的链接2、向最新月份的链接发请求,提取数据in: Noneout: Nonereturn: int >0 ok, <0 some wrong others: Logic Func"""one_html = self.get_html(url=self.url) # 获取html内容one_xpath = '//tr//@href' # 定义xpath表达式href_list = self.xpath_func(html=one_html, xpath_bds=one_xpath) # xpath解析提取数据if href_list: # 判断是否存在one_url = 'https://www.mca.gov.cn' + href_list[0] # 拼接返回列表的第一项self.detail_page(one_url) # 调用 详情页获取具体数据函数else:print("提取最新链接失败!")
- 详情页获取具体数据
def detail_page(self, one_url):"""function: 详情页获取具体数据in: one_url:一级页面的url地址out: Nonereturn: Noneothers: The Details Page Gets Data"""# 在响应内容中嵌入JS,进行了url地址的跳转two_html = self.get_html(one_url) # 传入详情页的url地址true_url = self.get_true_url(two_html) # 从响应内容中提取真实返回数据的链接true_html = self.get_html(true_url) # 开始从真实链接中提取数据two_xpath = "//tr[@height='19']" # 写xpath表达式tr_list = self.xpath_func(html=true_html, xpath_bds=two_xpath)item = {} # 定义一个空字典for tr in tr_list:item["name"] = tr.xpath('./td[3]/text()')[0].strip()item["code"] = tr.xpath('./td[2]/text()|./td[2]/span/text()')[0].strip()print(item)
- 从响应内容中提取真实返回数据的url地址
def get_true_url(self, two_html):"""function: 从响应内容中提取真实返回数据的url地址in: two_html:二级页面的响应内容out: true_url[0]:真实的url地址return: true_url[0]:真实的url地址others: From Html Get True Url"""regex = 'window.location.href="(.*?)"' # 正则表达式pattern = re.compile(regex, re.S) # 创建正则表达式编译对象true_url = pattern.findall(two_html) # 使用findall方法return true_url[0] # 返回真实的url地址
- 程序入口函数
def run(self):"""function: 程序入口函数in: Noneout: Nonereturn: Noneothers: Program Entry Func"""self.parse_html() # 调用逻辑函数
4、完整代码
import re
import requests
from lxml import etree
from fake_useragent import UserAgentclass MinzhengSpider:"""抓取民政部网站最新行政区划代码"""def __init__(self):self.url = 'https://www.mca.gov.cn/article/sj/xzqh/2020/' # url地址def get_html(self, url):"""function: 功能函数1:获取htmlin: url:url地址out: html:返回响应内容return: html:返回响应内容others: Func1:Get HTML"""headers = {'User-Agent': UserAgent().random} # 构建随机请求头html = requests.get(url=url, headers=headers).text # get方法获取响应内容return htmldef xpath_func(self, html, xpath_bds):"""function: 功能函数2:xpath解析提取数据in: html:响应内容xpath_bds:xpath表达式out: r_list:返回匹配内容return: r_list:返回匹配内容others: """p = etree.HTML(html) # 创建解析对象r_list = p.xpath(xpath_bds) # 解析对象调用xpath表达式return r_list # 返回匹配内容def parse_html(self):"""function: 逻辑函数1、向主页发请求,提取最新月份的链接2、向最新月份的链接发请求,提取数据in: Noneout: Nonereturn: int >0 ok, <0 some wrong others: Logic Func"""one_html = self.get_html(url=self.url) # 获取html内容one_xpath = '//tr//@href' # 定义xpath表达式href_list = self.xpath_func(html=one_html, xpath_bds=one_xpath) # xpath解析提取数据if href_list: # 判断是否存在one_url = 'https://www.mca.gov.cn' + href_list[0] # 拼接返回列表的第一项self.detail_page(one_url) # 调用 详情页获取具体数据函数else:print("提取最新链接失败!")def detail_page(self, one_url):"""function: 详情页获取具体数据in: one_url:一级页面的url地址out: Nonereturn: Noneothers: The Details Page Gets Data"""# 在响应内容中嵌入JS,进行了url地址的跳转two_html = self.get_html(one_url) # 传入详情页的url地址true_url = self.get_true_url(two_html) # 从响应内容中提取真实返回数据的链接true_html = self.get_html(true_url) # 开始从真实链接中提取数据two_xpath = "//tr[@height='19']" # 写xpath表达式tr_list = self.xpath_func(html=true_html, xpath_bds=two_xpath)item = {} # 定义一个空字典for tr in tr_list:item["name"] = tr.xpath('./td[3]/text()')[0].strip()item["code"] = tr.xpath('./td[2]/text()|./td[2]/span/text()')[0].strip()print(item)def get_true_url(self, two_html):"""function: 从响应内容中提取真实返回数据的url地址in: two_html:二级页面的响应内容out: true_url[0]:真实的url地址return: true_url[0]:真实的url地址others: From Html Get True Url"""regex = 'window.location.href="(.*?)"' # 正则表达式pattern = re.compile(regex, re.S) # 创建正则表达式编译对象true_url = pattern.findall(two_html) # 使用findall方法return true_url[0] # 返回真实的url地址def run(self):"""function: 程序入口函数in: Noneout: Nonereturn: Noneothers: Program Entry Func"""self.parse_html() # 调用逻辑函数if __name__ == '__main__':spider = MinzhengSpider()spider.run()
5、实现效果
