Anomaly detection(异常检测)
Problem motivation
给定数据集,先假设它们都是正常的,如果有一新的数据,想知道是不是异常,即这个测试数据不属于该组数据的几率如何。
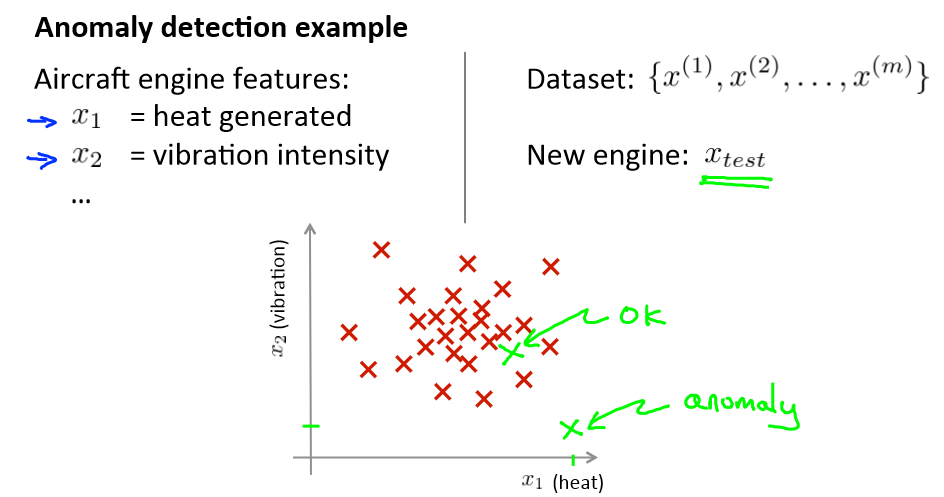
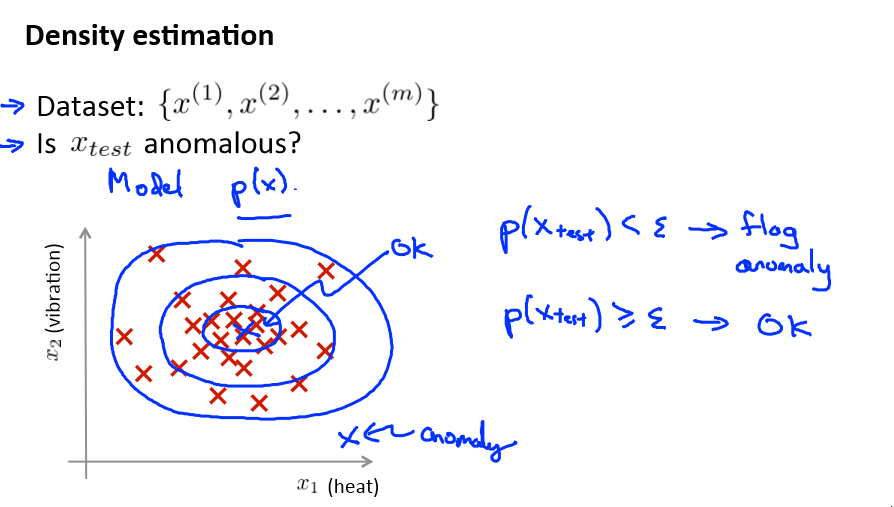
在上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该组数据的可能性就越低。
这种方法称为密度估计

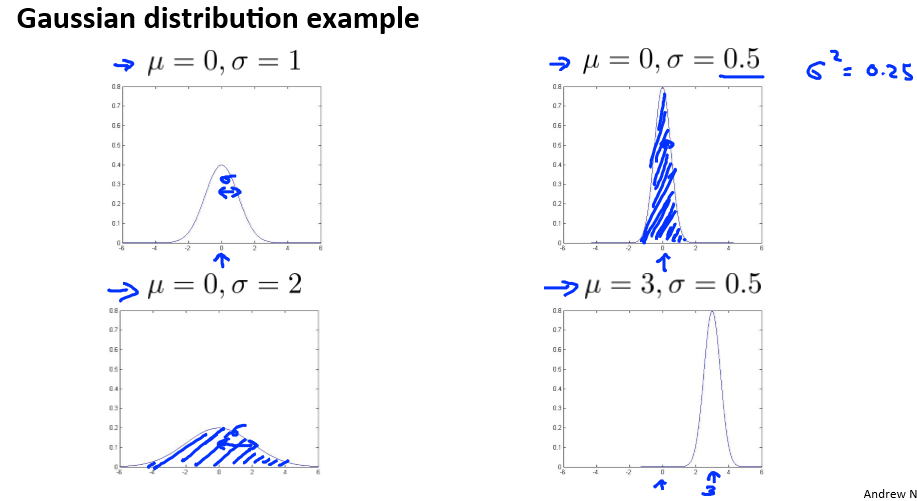
Gaussian distribution
用高数函数来检测是否异常,一般正常的数据都会集中在某个范围,如果一个数据出现在密度很疏密的地方,那么就有很大的几率是异常的。

类似与高中学的正态分布,但又有所不同。高数分布图:
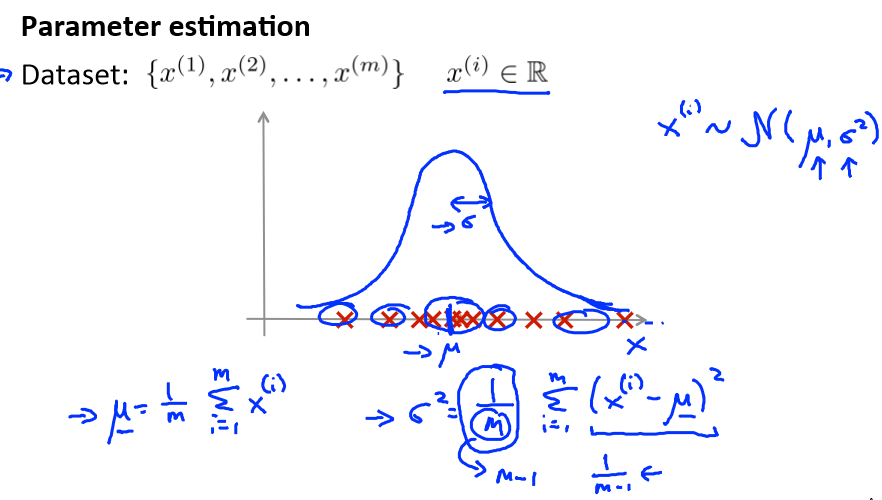
Algorithm
它的实现首先需要算出平均值和方差,一旦获得了这两个参数,那么就可以判断新的数据是否是异常的概率了。

例如:
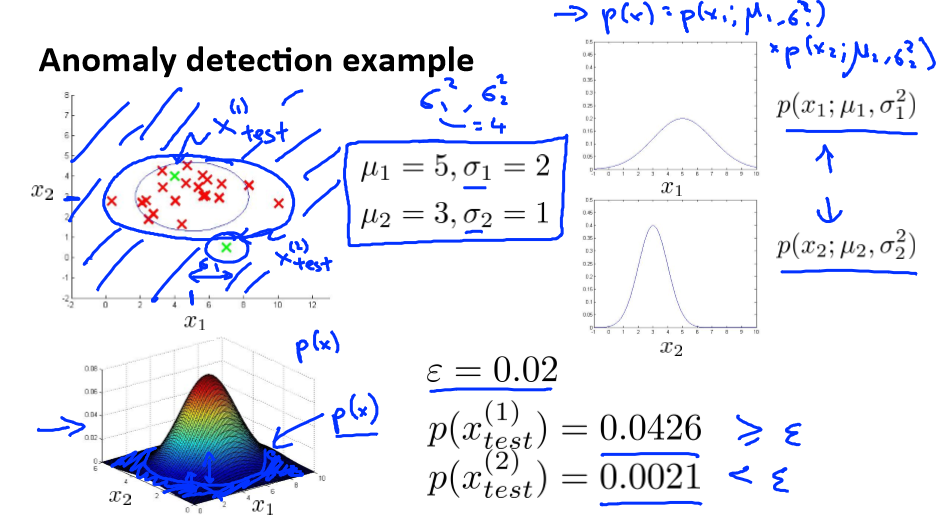
Developing and evaluating an anomaly detection system
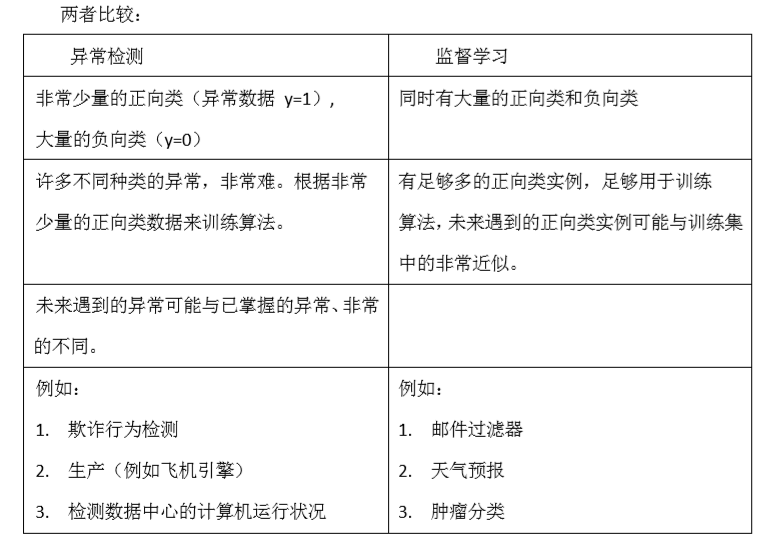
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 y 的值来告诉我们数据是否真的是异常的。
我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系 统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训 练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。

例如:我们有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 我们这样分配数据:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和 10 台异常引擎的数据作为测试集 
具体的评价方法如下:
1、根据测试集数据,我们估计特征的平均值和方差并构建 p(x)函数
2、对交叉检验集,我们尝试使用不同的 ε 值作为阀值,并预测数据是否异常,根据 F1值或者查准率与查全率的比例来选择 ε
3、选出 ε 后,针对测试集进行预测,计算异常检验系统的 F1 值,或者查准率与查全率之比

Anomaly detection vs. supervised learning


Choosing what features to use
对于异常检测算法,我们使用的特征是至关重要的,下面谈谈如何选择特征:
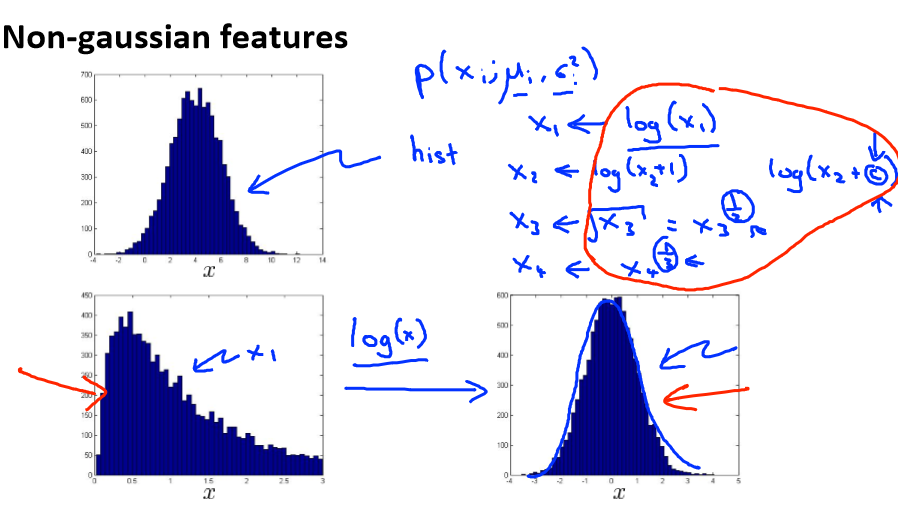
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:x = log(x+c),其中 c 为非
负常数; 或者 x=xc,c 为 0-1 之间的一个分数,等方法。
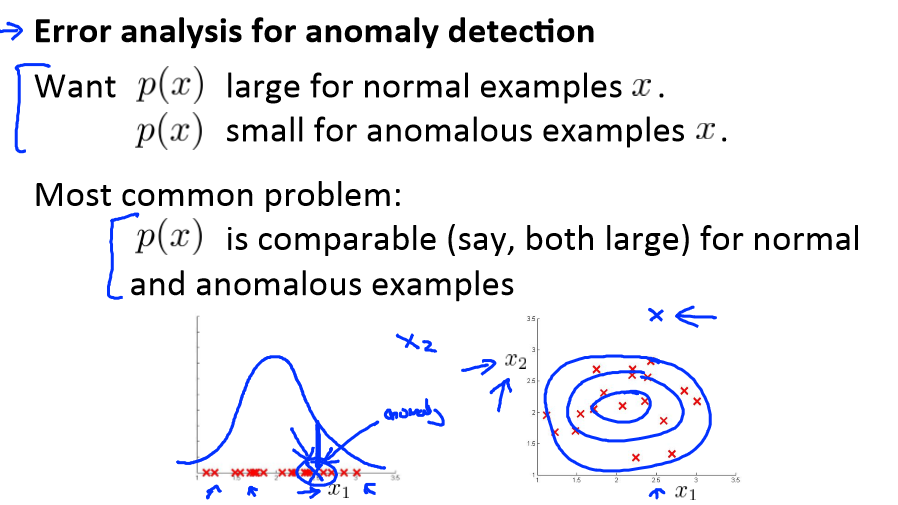
误差分析:
一个常见的问题是一些异常的数据可能也会有较高的 p(x)值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察
能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。

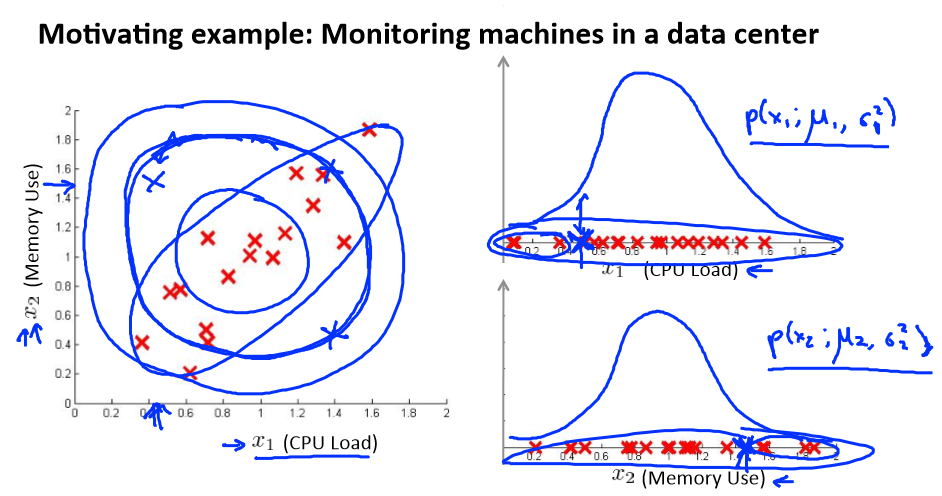
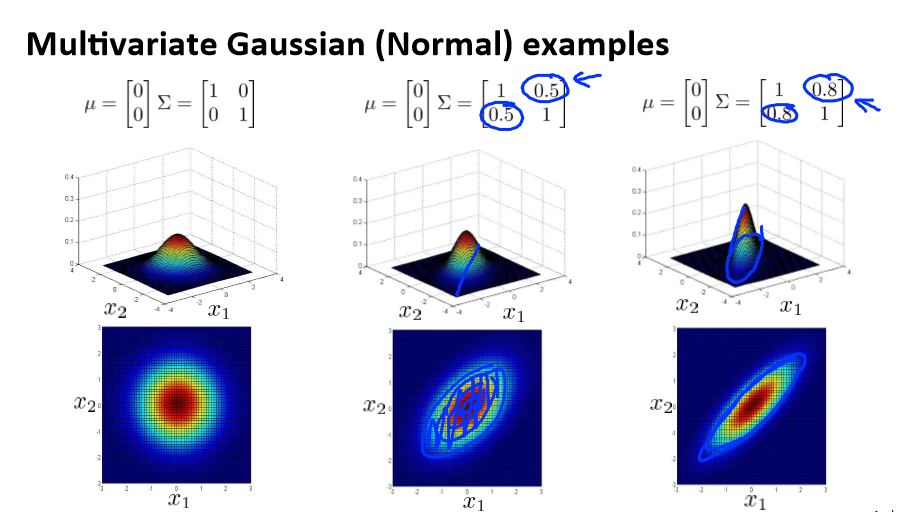
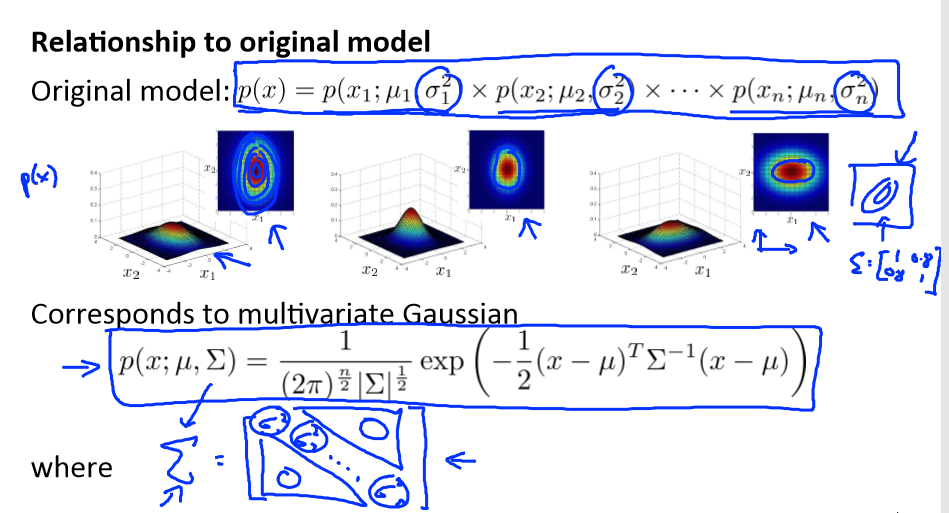
Multivariate Gaussian distribution
假使我们有两个相关的特征,而且这两个特征的值域范围比较宽,这种情况下,一般的高斯分布模型可能不能很好地识别异常数据。其原因在于,一般的高斯分布模型尝试的是去
同时抓住两个特征的偏差,因此创造出一个比较大的判定边界。
我们首先计算所有特征的平均值,然后再计算协方差矩阵: 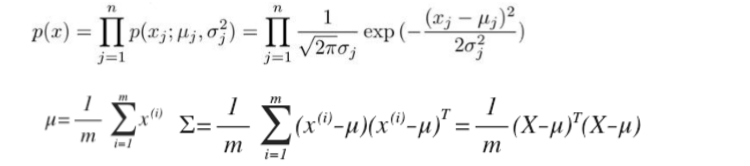
注:其中 μ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后我们计算多元高斯分布的 p(x):
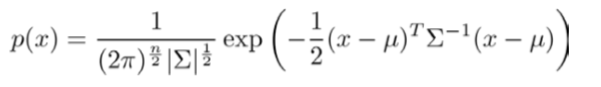
其中: |Σ|是定矩阵,在 Octave 中用 det(sigma)计算
例如:
Anomaly detection using the multivariate Gaussian distribution
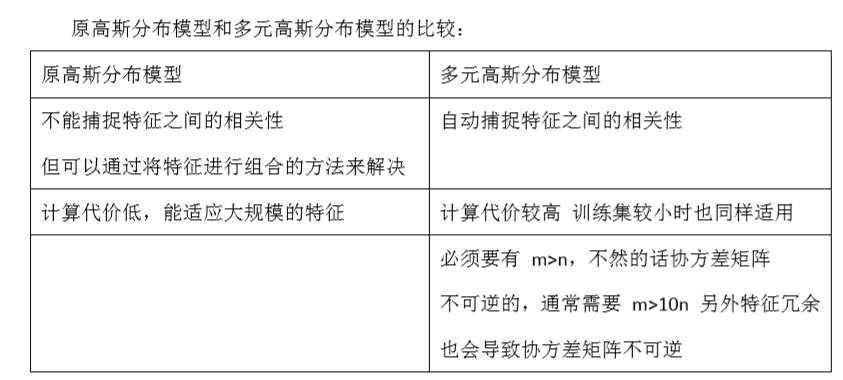
多元高斯分布和多元正态分布:
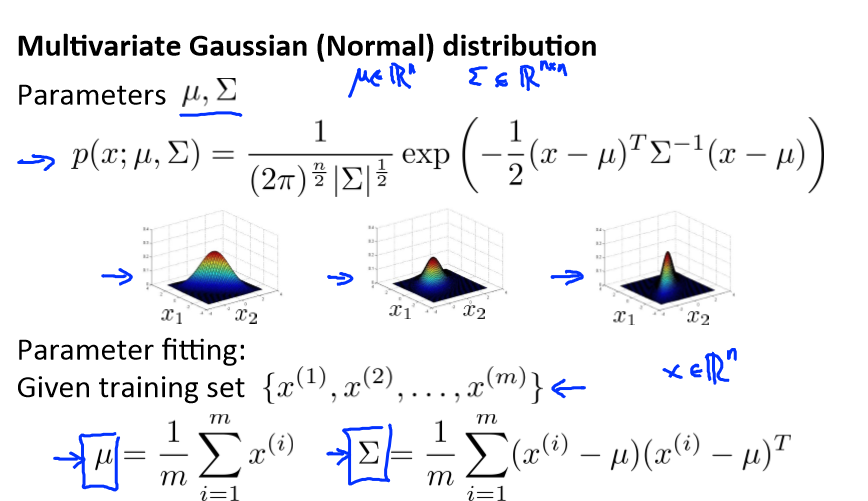
我有一组样本{x(1),x(2),...,x(m)}是一个 n 维向量,我想我的样本来自一个多元高斯分布。我如何尝试估计我的参数μ和Σ以及标准公式?
估计他们是你设置μ是你的训练样本的平均值。
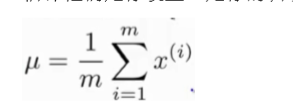
并设置Σ:
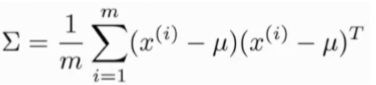
这其实只是当我们使用 PCA 算法时候,有Σ时写出来。


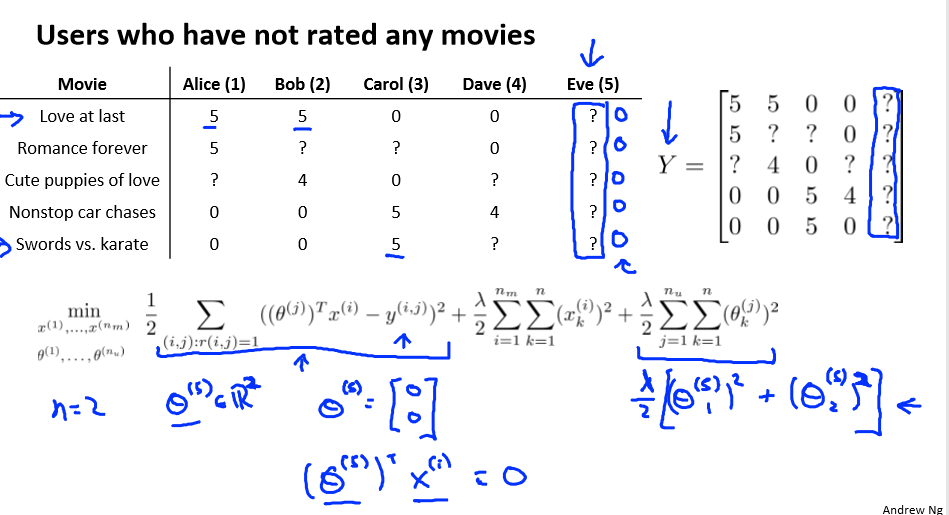
Recommender Systems(推荐系统)
Problem formulation
比如电影推荐系统,根据人的不同喜爱而推荐不同的电影
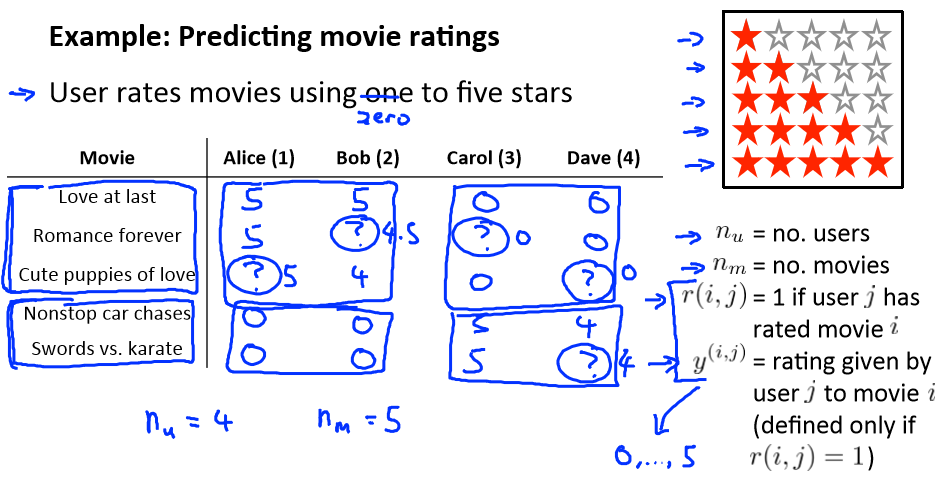
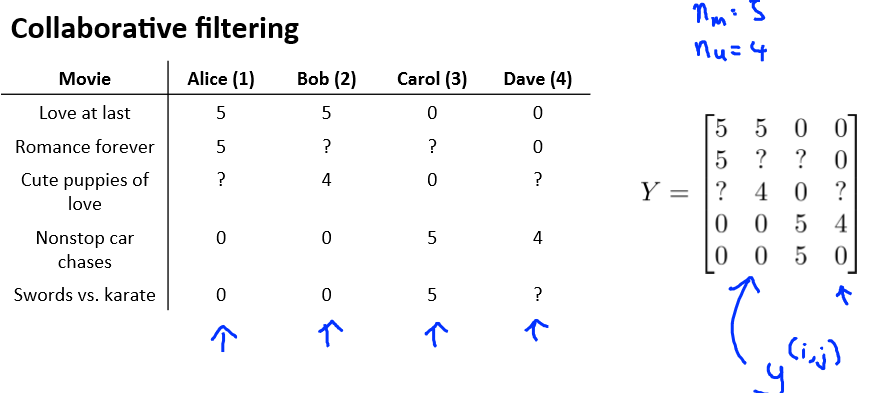
符号定义:
nu 代表用户的数量
nm 代表电影的数量
r(i,j)如果用户 i 给电影 j 评过分则 r(i,j)=1
y(i,j)代表用户 i 给电影 j 的评分
mj 代表用户 j 评过分的电影的总数
Content-based recommendations
在我们的例子中,我们可以假设每部电影都有两个特征,如 x1代表电影的浪漫程度,x2 代表电影的动作程度。
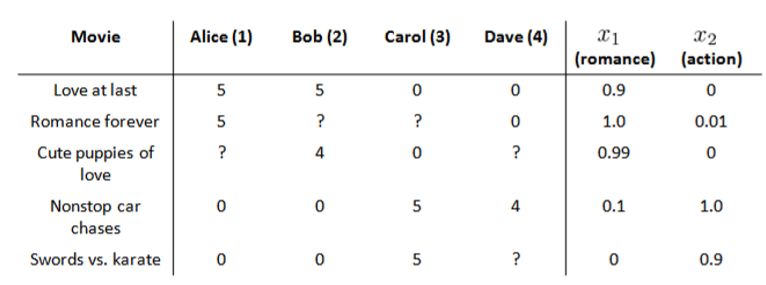
下面我们要基于这些特征来构建一个推荐系统算法。 假设我们采用线性回归模型,我们可以针对每一个用户都训练一个线性回归模型,如 θ(1)是第一个用户的模型的参数。 于
是,我们有:
θ(j)用户 j 的参数向量
x(i)电影 i 的特征向量
对于用户 j 和电影 i,我们预测评分为:(θ(j))Tx(i)
代价函数如下:
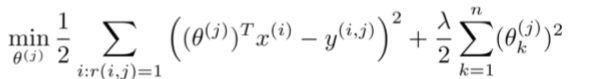
上面的代价函数只是针对一个用户的,为了学习所有用户,我们将所有用户的代价函数求和:
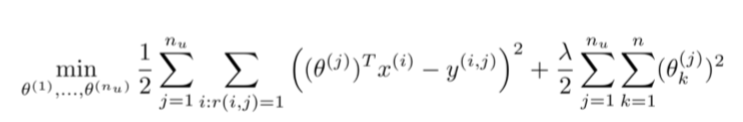
如果我们要用梯度下降法来求解最优解,我们计算代价函数的偏导数后得到梯度下降的更新公式为: 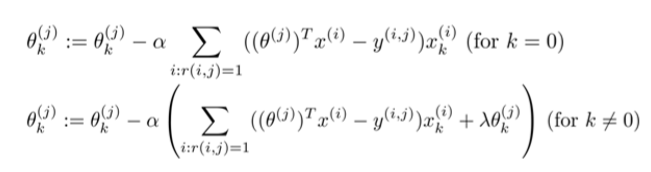
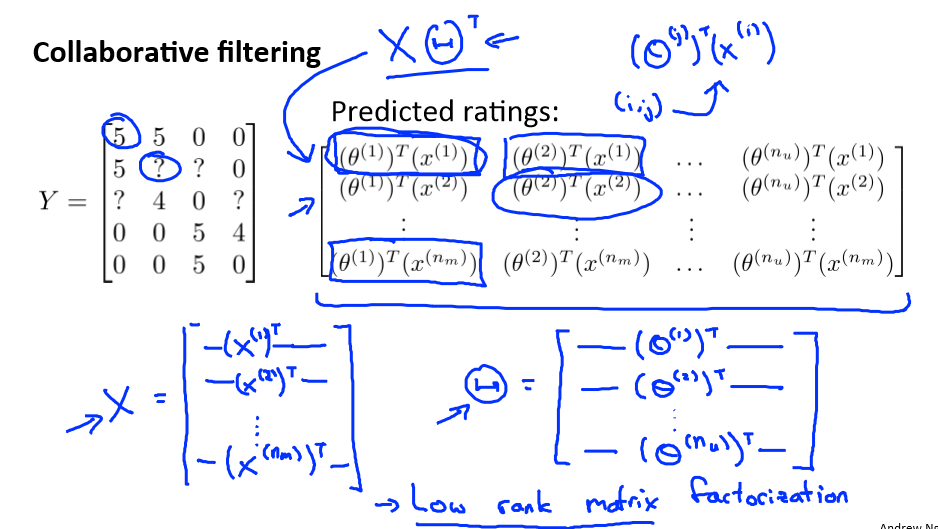
Collaborative filtering
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出
电影的特征。
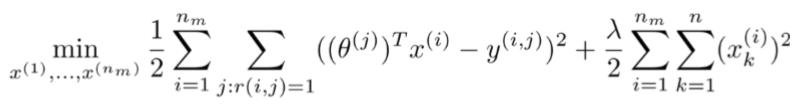
但是如果我们既没有用户的参数,也没有电影的特征,这两种方法都不可行了。协同过滤算法可以同时学习这两者。
我们的优化目标便改为同时针对 x 和 θ 进行。
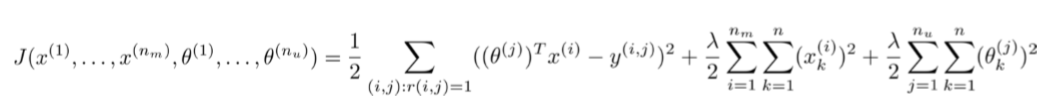
对代价函数求偏导数的结果如下:
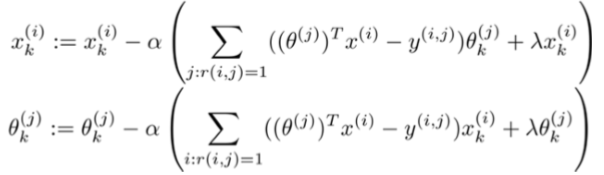
注:在协同过滤从算法中,我们通常不使用方差项,如果需要的话,算法会自动学得。协同过滤算法使用步骤如下:
1、初始 x(1),x(2),...,x(nm),θ(1),θ(2),...,θ(nu)为一些随机小值
2、使用梯度下降算法最小化代价函数
3、在训练完算法后,我们预测(θ(j))Tx(i)为用户 j 给电影 i 的评分


Collaborative filtering algorithm
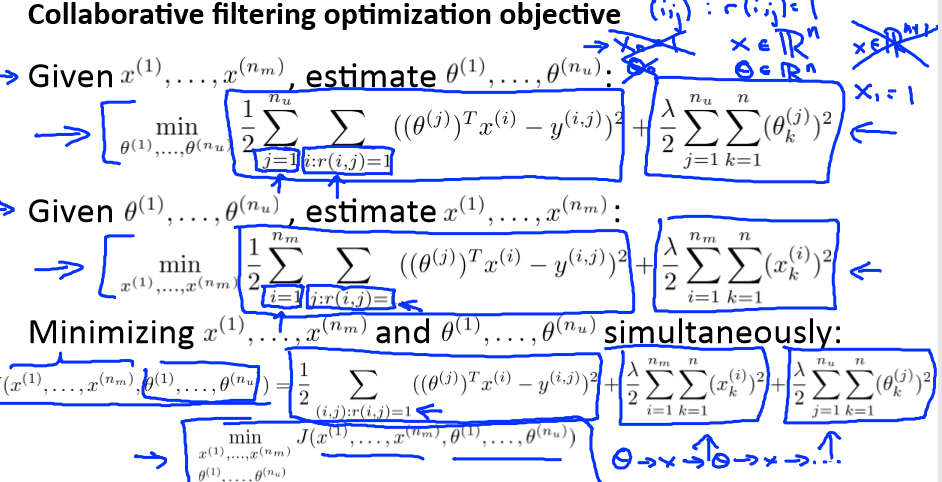

Vectorization: Low rank matrix factorization
协同过滤

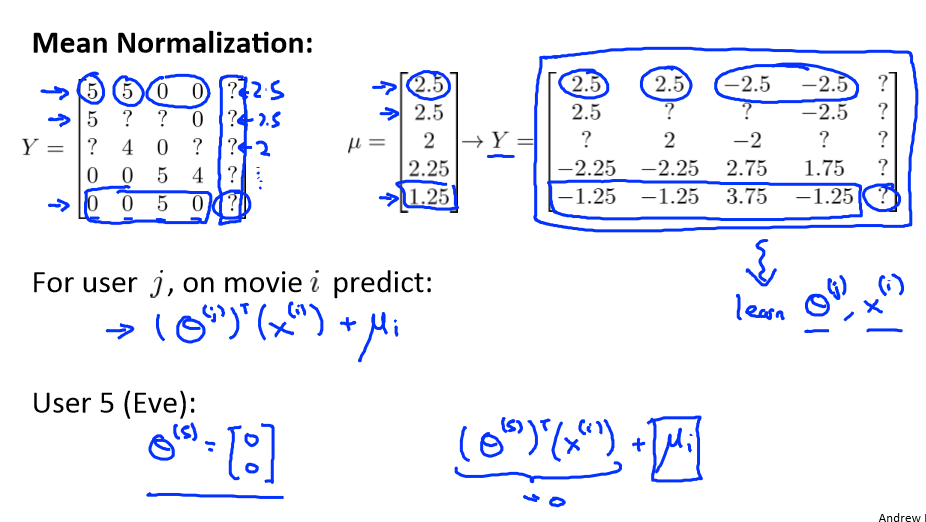
Implementational detail: Mean normalization