北海做网站哪家好小红书信息流广告
文章目录
- 1. 合并两个有序链表(迭代法)
- 2. 合并两个有序链表(递归法)
- 3. 链表概念
- 4. Python实现链表
- 1. 定义节点
- 2. 链表的基本操作
- 1. 计算链表长
- 2. 从前插入
- 3. 向后插入
- 4. 查找
- 5. 删除(方法一)
- 6. 删除(方法二)
- 7. 打印输出
- 8. 获取所有data
- 9. 测试代码
1. 合并两个有序链表(迭代法)
'''
将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
'''
迭代法
算法:
首先,设定一个哨兵节点 “prehead” ,这可以在最后让我们比较容易地返回合并后的链表。维护一个 prev 指针,需要做的是调整它的 next 指针。然后,重复以下过程,直到 l1 或者 l2 指向了 null :如果 l1 当前位置的值小于等于 l2 ,我们就把 l1 的值接在 prev 节点的后面 prev.next = l1,同时将 l1 指针往后移一个 l1 = l1.next。否则,对 l2 做同样的操作。不管将哪一个元素接在了后面,都把 prev 向后移一个元素。
在循环终止的时候, l1 和 l2 至多有一个是非空的。由于输入的两个链表都是有序的,所以不管哪个链表是非空的,它包含的所有元素都比前面已经合并链表中的所有元素都要大。这意味着我们只需要简单地将非空链表接在合并链表的后面,并返回合并链表。
复杂度分析:
时间复杂度:O(n + m) 。因为每次循环迭代中,l1 和 l2 只有一个元素会被放进合并链表中, while 循环的次数等于两个链表的总长度。所有其他工作都是常数级别的,所以总的时间复杂度是线性的。
空间复杂度:O(1) 。迭代的过程只会产生几个指针,所以它所需要的空间是常数级别的。
# Definition for singly-linked list.
class ListNode:def __init__(self, val):self.val = valself.next = Noneclass Solution:def mergeTwoLists(self, l1, l2):# 在返回节点之前,保持对节点的不变的引用。prehead = ListNode(-1)prev = preheadwhile l1 and l2:if l1.val <= l2.val:prev.next = l1l1 = l1.nextelse:prev.next = l2l2 = l2.nextprev = prev.next# l1和l2中的一个可能是非空的,因此将非空列表连接到合并列表的末尾。prev.next = l1 if l1 is not None else l2return prehead.next
2. 合并两个有序链表(递归法)
我们可以如下递归地定义在两个链表里的 merge 操作(忽略边界情况,比如空链表等):
list1[0] + merge(list1[1:], list2) list1[0] < list2[0]
list2[0] + merge(list1, list2[1:]) otherwise
也就是说,两个链表头部较小的一个与剩下元素的 merge 操作结果合并。
算法:
直接将以上递归过程建模,首先考虑边界情况。
特殊的,如果 l1 或者 l2 一开始就是 null ,那么没有任何操作需要合并,所以我们只需要返回非空链表。否则,我们要判断 l1 和 l2 哪一个的头元素更小,然后递归地决定下一个添加到结果里的值。如果两个链表都是空的,那么过程终止,所以递归过程最终一定会终止。
复杂度分析:
时间复杂度:O(n+m)。 因为每次调用递归都会去掉 l1 或者 l2 的头元素(直到至少有一个链表为空),函数 mergeTwoList 中只会遍历每个元素一次。所以,时间复杂度与合并后的链表长度为线性关系。
空间复杂度:O(n+m)。调用 mergeTwoLists 退出时 l1 和 l2 中每个元素都一定已经被遍历过了,所以 n + m个栈帧会消耗 O(n + m)的空间。
class Solution:def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:if not l1:return l2 # 终止条件,直到两个链表都空if not l2:return l1if l1.val <= l2.val: # 递归调用l1.next = self.mergeTwoLists(l1.next, l2)return l1else:l2.next = self.mergeTwoLists(l1, l2.next)return l2
3. 链表概念
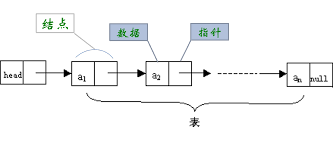
在链式存储中,每个存储节点不仅包含元素本身的信息(称为数据域),而且包含有元素之间逻辑关系的信息,即一个节点包含有后继节点的地址信息(称为指针域),这样可以通过一个节点的指针域方便地找到后继节点的位置。
一般地,每个节点有一个或多个这样的指针域。若一个节点中的某个指针域不需要指向其他任何节点,则将它的值置为空,用常量NULL表示(在Python中一般用None表示)。
单链表:在每个节点中除数据域外,应只设置一个指针域,用以指向其后继节点,这样构成的链接表称为线性单向链接表。
双链表:在每个节点中数值域外,设置两个指针域,分别用以指向其前驱节点和后继节点,这样构成的链接表称为线性双向链接表。
单链表中,由于每个节点包含有一个指向后继节点的指针,所以当访问过一个节点后,只能接着访问它的后继节点,而无法访问它的前驱节点。
双链表中,每个节点既包含一个指向后继节点的指针,又包含一个指向前驱节点的指针,当访问一个节点后,既可以一次向后访问每一个节点,也可以一次向前访问每一个节点。
每个链表带有一个头节点,并通过头节点的指针唯一标识该链表。
翻出大学时的《数据结构教程》课本,拍了其中一张图,另一张网上找的:

4. Python实现链表
链表的基本元素:
- 节点:每个节点有两个部分,左边部分称为值域,用来存放用户数据;右边部分称为指针域,用来存放指向下一个元素的指针。
- head:head节点永远指向第一个节点
- tail: tail永远指向最后一个节点
- None:链表中最后一个节点的指针域为None值
1. 定义节点
class Node:def __init__(self, data=None, next=None):self.data = dataself.next = nextdef __str__(self):return str(self.data)node1 = Node(1)
node2 = Node(2)
node3 = Node(3)node1.next = node2
node2.next = node3print(node1, node1.next) # 1 2
print(node2, node2.next) # 2 3
print(node3, node3.next) # 3 None
循环打印node:
# 在使用链表时常用到while循环
def printLinkedList(node):while node:print(node)node = node.next
printLinkedList(node1)
# 1
# 2
# 3
递归打印node:
- 将 node 拆分成两个部分,head:第一个元素,tail:其余元素
- 向后打印
- 打印第一个元素
# 递归打印def recursiveprintLinkedList(node):if node is None:return Nonehead = nodetail = node.nextprint(head, tail)recursiveprintLinkedList(tail)print(head, tail)recursiveprintLinkedList(node1)# 1 2# 2 3# 3 None# 3 None# 2 3# 1 2
# 简化递归:
def recursiveprintLinkedList2(node):if node is None:return Noneprint(node)return recursiveprintLinkedList2(node.next)recursiveprintLinkedList2(node1)
2. 链表的基本操作
1. 计算链表长
class LinkedList(object):def __init__(self, head=None):self.head = headdef __len__(self):current = self.headcounter = 0while current is not None:current = current.nextcounter += 1return counter
2. 从前插入
- 被插入数据为空,返回
- 使用输入数据创建一个节点,并将该节点指向原来头节点
- 设置该节点为头节点
时间复杂度和空间复杂度均为O(1)
def insert_to_front(self, data):if data is None:return Noneelse:node = Node(data, self.head)self.head = nodereturn node
3. 向后插入
- 若输入数据为空,返回None
- 若头节点为空,直接将输入数据作为头节点
- 遍历整个链表,直到当前节点的下一个节点为None时,将当前节点的下一个节点设置为输入数据
时间复杂度为O(n),空间O(1)
def append(self, data):if data is None:return Nonenode = Node(data)if self.head is None:self.head = nodereturn nodeelse:crt_node = self.headwhile crt_node.next is not None:crt_node = crt_node.nextcrt_node.next = nodereturn node
4. 查找
- 若查找的数据为空,返回
- 设置头节点为当前节点,若当前节点不为None,遍历整个链表
- 若当前节点的data与输入的data相同,但会当前节点,否则轮到下一个节点
可见时间复杂度为O(n),空间复杂度为O(1)
def find(self, data):if data is None:return Noneelse:crt_node = self.headwhile crt_node is not None:if crt_node.data == data:return crt_nodeelse:crt_node = crt_node.nextreturn None
5. 删除(方法一)
申请两个变量,如果遇到匹配的,不用删除,直接将匹配节点的前一节点指向匹配节点的下一节点,因此需要定义一个前节点和一个当前节点,当前节点用来判断是否与输入数据匹配,前节点用来更改链表的指向。
- 若输入数据为None,返回
- 将头节点设置为前节点,头节点的下一个节点设置为当前节点
- 判断前节点是否与输入数据匹配,若匹配,将头节点设置为当前节点
- 遍历整个链表,若当前节点与输入数据匹配,将前节点的指针指向当前节点的下一个节点,否则,移到下一个节点
时间复杂度为O(n),空间复杂度为O(1)
def delete(self, data):if data is None or self.head is None:return Noneelse:if self.head.data == data:self.head = self.head.nextelse:pre_node = self.headcrt_node = self.head.nextwhile crt_node is not None:if crt_node.data == data:pre_node.next = crt_node.next# return None # 若这里直接返回,就只删除第一个找到的等于data的nodecrt_node = crt_node.next # 加上这行可以删除所有匹配的else:pre_node = crt_nodecrt_node = crt_node.nextreturn None
6. 删除(方法二)
只定义一个变量作为当前节点,使用它的下一个节点去判断是否与数据数据匹配,若匹配,直接将当前节点指向下下一个节点。
时间复杂度为O(n),空间复杂度为O(1)
def delete2(self, data):if data is None or self.head is None:return Noneelse:if self.head.data == data:self.head = self.head.nextelse:crt_node = self.headwhile crt_node.next is not None:if crt_node.next.data == data:crt_node.next = crt_node.next.nextelse:crt_node = crt_node.nextreturn None
7. 打印输出
def print_data(self):crt_node = self.headwhile crt_node is not None:print(crt_node.data)crt_node = crt_node.next
8. 获取所有data
def get_all_data(self):get_data = []crt_node = self.headwhile crt_node is not None:get_data.append(crt_node.data)crt_node = crt_node.nextreturn get_data
9. 测试代码
测试以上函数的代码,不在博客中罗列了。
Reference:
linked_list
python数据结构之链表
python数据结构之栈