新开传奇网站首区律师推广网站排名
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。 但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

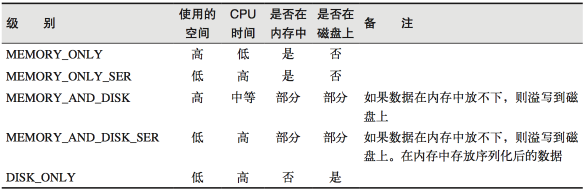
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
 在存储级别的末尾加上“_2”来把持久化数据存为两份
在存储级别的末尾加上“_2”来把持久化数据存为两份
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
实例演示:
将RDD转换为携带当前时间戳并做缓存:
1、编写代码:
object CacheDemo01 {def main(args: Array[String]): Unit = {// 创建SparkConf并初始化SparkContextval sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("cache")val sc = new SparkContext(sparkConf)// 创建一个RDDval rdd1: RDD[String] = sc.makeRDD(Array("zhaozhao"))// 为RDD1中元素加上当前时间戳val rdd2: RDD[String] = rdd1.map(_.toString + System.currentTimeMillis())// 输出结果rdd2.collect().foreach(println)rdd2.collect().foreach(println)rdd2.collect().foreach(println)}
}
2、运行结果
我把打印信息剔除一部分,为了方便展示结果。明显看出三次结果不一样。
20/08/26 15:52:02 INFO DAGScheduler: ResultStage 0 (collect at CacheDemo01.scala:17) finished in 0.213 s
20/08/26 15:52:02 INFO DAGScheduler: Job 0 finished: collect at CacheDemo01.scala:17, took 1.271296 s
zhaozhao1598428322340
20/08/26 15:52:02 INFO DAGScheduler: Final stage: ResultStage 1 (collect at CacheDemo01.scala:18)
20/08/26 15:52:02 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 1856.0 B, free 1442.4 MB)
20/08/26 15:52:02 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1200.0 B, free 1442.4 MB)
20/08/26 15:52:02 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.222.1:65520 (size: 1200.0 B, free: 1442.4 MB)
20/08/26 15:52:02 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996
20/08/26 15:52:02 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[1] at map at CacheDemo01.scala:15)
20/08/26 15:52:02 INFO DAGScheduler: ResultStage 1 (collect at CacheDemo01.scala:18) finished in 0.046 s
20/08/26 15:52:02 INFO DAGScheduler: Job 1 finished: collect at CacheDemo01.scala:18, took 0.106986 s
zhaozhao1598428322526
20/08/26 15:52:02 INFO SparkContext: Starting job: collect at CacheDemo01.scala:19
20/08/26 15:52:02 INFO DAGScheduler: Got job 2 (collect at CacheDemo01.scala:19) with 1 output partitions
20/08/26 15:52:02 INFO DAGScheduler: Final stage: ResultStage 2 (collect at CacheDemo01.scala:19)
20/08/26 15:52:02 INFO DAGScheduler: Parents of final stage: List()
20/08/26 15:52:02 INFO DAGScheduler: Missing parents: List()
20/08/26 15:52:02 INFO DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[1] at map at CacheDemo01.scala:15), which has no missing parents
20/08/26 15:52:02 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 2) in 26 ms on localhost (executor driver) (1/1)
zhaozhao1598428322607
3、为RDD2加上缓存操作
 4、运行结果
4、运行结果
三次打印结果一样,说明开启了缓存操作。
20/08/26 15:56:19 INFO DAGScheduler: Job 0 finished: collect at CacheDemo01.scala:17, took 0.818124 s
zhaozhao1598428579160
20/08/26 15:56:19 INFO SparkContext: Starting job: collect at CacheDemo01.scala:18
20/08/26 15:56:19 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 1864.0 B, free 1442.4 MB)
20/08/26 15:56:19 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1204.0 B, free 1442.4 MB)
zhaozhao1598428579160
20/08/26 15:56:19 INFO SparkContext: Starting job: collect at CacheDemo01.scala:19
20/08/26 15:56:19 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 1864.0 B, free 1442.4 MB)
20/08/26 15:56:19 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1204.0 B, free 1442.4 MB)
20/08/26 15:56:19 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.222.1:49236 (size: 1204.0 B, free: 1442.4 MB)
20/08/26 15:56:19 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996
20/08/26 15:56:19 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[1] at map at CacheDemo01.scala:15)
zhaozhao1598428579160