网站建设_制作_设计网站seo报价
来源:https://yemengying.com/2017/06/04/reddit-view-counting/之前没听过也没了解过 HyperLogLog,通过翻译这篇文章正好简单学习下。欢迎指正错误~

我们想要更好的向用户展示 Reddit 的规模。为了这一点,投票和评论数是一个帖子最重要的指标。然而,在 Reddit 上有相当多的用户只浏览内容,既不投票也不评论。所以我们想要建立一个能够计算一个帖子浏览数的系统。这一数字会被展示给帖子的创作者和版主,以便他们更好的了解某个帖子的活跃程度。

在这篇博客中,我们将讨论我们是如何实现超大数据量的计数。
计数机制
对于计数系统我们主要有四种需求:
- 帖子浏览数必须是实时或者近实时的,而不是每天或者每小时汇总。
- 同一用户在短时间内多次访问帖子,只算一个浏览量
- 显示的浏览量与真实浏览量间允许有小百分之几的误差
- Reddit 是全球访问量第八的网站,系统要能在生产环境的规模上正常运行,仅允许几秒的延迟
要全部满足以上四个需求的困难远远比听上去大的多。为了实时精准计数,我们需要知道某个用户是否曾经访问过这篇帖子。想要知道这个信息,我们就要为每篇帖子维护一个访问用户的集合,然后在每次计算浏览量时检查集合。一个 naive 的实现方式就是将访问用户的集合存储在内存的 hashMap 中,以帖子 Id 为 key。
这种实现方式对于访问量低的帖子是可行的,但一旦一个帖子变得流行,访问量剧增时就很难控制了。甚至有的帖子有超过 100 万的独立访客! 对于这样的帖子,存储独立访客的 ID 并且频繁查询某个用户是否之前曾访问过会给内存和 CPU 造成很大的负担。
因为我们不能提供准确的计数,我们查看了几种不同的基数估计算法。有两个符合我们需求的选择:
- 一是线性概率计数法,很准确,但当计数集合变大时所需内存会线性变大。
- 二是基于 HyperLogLog (以下简称 HLL )的计数法。 HLL 空间复杂度较低,但是精确度不如线性计数。
下面看下 HLL 会节省多少内存。如果我们需要存储 100 万个独立访客的 ID, 每个用户 ID 8 字节长,那么为了存储一篇帖子的独立访客我们就需要 8 M的内存。反之,如果采用 HLL 会显著减少内存占用。不同的 HLL 实现方式消耗的内存不同。如果采用这篇文章的实现方法,那么存储 100 万个 ID 仅需 12 KB,是原来的 0.15%!!
Big Data Counting: How to count a billion distinct objects using only 1.5KB of Memory – High Scalability -这篇文章很好的总结了上面的算法。
许多 HLL 的实现都是结合了上面两种算法。在集合小的时候采用线性计数,当集合大小到达一定的阈值后切换到 HLL。前者通常被成为 ”稀疏“(sparse) HLL,后者被称为”稠密“(dense) HLL。这种结合了两种算法的实现有很大的好处,因为它对于小集合和大集合都能够保证精确度,同时保证了适度的内存增长。可以在 google 的这篇论文中了解这种实现的详细内容。
http://antirez.com/news/75
现在我们已经确定要采用 HLL 算法了,不过在选择具体的实现时,我们考虑了以下三种不同的实现。因为我们的数据工程团队使用 Java 和 Scala,所以我们只考虑 Java 和 Scala 的实现。
- Twitter 提供的 Algebird,采用 Scala 实现。Algebird 有很好的文档,但他们对于 sparse 和 dense HLL 的实现细节不是很容易理解。
- stream-lib中提供的 HyperLogLog++, 采用 Java 实现。stream-lib 中的代码文档齐全,但有些难理解如何合适的使用并且改造的符合我们的需求。
- Redis HLL 实现,这是我们最终选择的。我们认为 Redis 中 HLLs 的实现文档齐全、容易配置,提供的相关 API 也很容易集成。还有一个好处是,我们可以用一台专门的服务器部署,从而减轻性能上的压力。

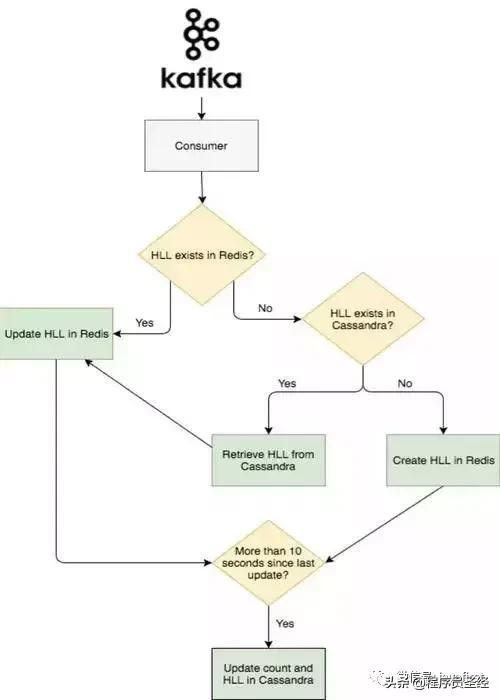
Reddit 的数据管道依赖于 Kafka。当一个用户访问了一篇博客,会触发一个事件,事件会被发送到事件收集服务器,并被持久化在 Kafka 中。
之后,计数系统会依次顺序运行两个组件。在我们的计数系统架构中,第一部分是一个 Kafka 的消费者,我们称之为 Nazar。Nazar 会从 Kafka 中读取每个事件,并将它通过一系列配置的规则来判断该事件是否需要被计数。我们取这个名字仅仅是因为 Nazar 是一个眼睛形状的护身符,而 ”Nazar“ 系统就像眼睛一样使我们的计数系统远离不怀好意者的破坏。其中一个我们不将一个事件计算在内的原因就是同一个用户在很短时间内重复访问。Nazar 会修改事件,加上个标明是否应该被计数的布尔标识,并将事件重新放入 Kafka。
下面就到了系统的第二个部分。我们将第二个 Kafka 的消费者称作 Abacus,用来进行真正浏览量的计算,并且将计算结果显示在网站或客户端。Abacus 从 Kafka 中读取经过 Nazar 处理过的事件,并根据 Nazar 的处理结果决定是跳过这个事件还是将其加入计数。如果 Nazar 中的处理结果是可以加入计数,那么 Abacus 首先会检查这个事件所关联的帖子在 Redis 中是否已经存在了一个 HLL 计数器。如果已经存在,Abacus 会给 Redis 发送个 PFADD 的请求。如果不存在,那么 Abacus 会给 Cassandra 集群发送个请求(Cassandra 用来持久化 HLL 计数器和 计数值的),然后向 Redis 发送 SET 请求。这通常会发生在网友访问较老帖子的时候,这时该帖子的计数器很可能已经在 Redis 中过期了。
为了存储存在 Redis 中的计数器过期的老帖子的浏览量。Abacus 会周期性的将 Redis 中全部的 HLL 和 每篇帖子的浏览量写入到 Cassandra 集群中。为了避免集群过载,我们以 10 秒为周期批量写入。
下图是事件流的大致流程:
总结
我们希望浏览量可以让发帖者了解帖子全部的访问量,也帮助版主快速定位自己社区中高访问量的帖子。在未来,我们计划利用我们数据管道在实时方面的潜力来为 Reddit 的用户提供更多的有用的反馈。