免费物业网站模板/北京疫情发布不再公布各区数据

一、word2vec简介
word2vec是google开源的一款用于词向量计算的工具。可以这样理解word2vec,它是一个计算词向量的工具,也是一种语言算法模型。它的原理大致就是通过背后的CBow和skip-gram模型进行相应的计算,然后得出词向量。
本文的目的主要是介绍如何训练和使用word2vec来完成相应的NLP任务,这里不涉及原理。使用的包是:gensim
二、模型训练和保存及加载
模型训练
首先看看要用到的类:(部分代码)

主要关注的就是 sentences、size、window、min_count这几个参数。
sentences:是一个list,size表示输出向量的维度。
window:当前词与预测次在一个句子中最大距离是多少。
min_count:用于字典阶段,词频少于min_count次数的单词会被丢弃掉,默认为5
在训练模型之前,要对收集的预料进行分词处理,同时也要进行停用词的处理。在对数据进行预处理之后就可以训练我们的词向量了。训练的方式,从代码实现角度看,有两种,部分代码如下:
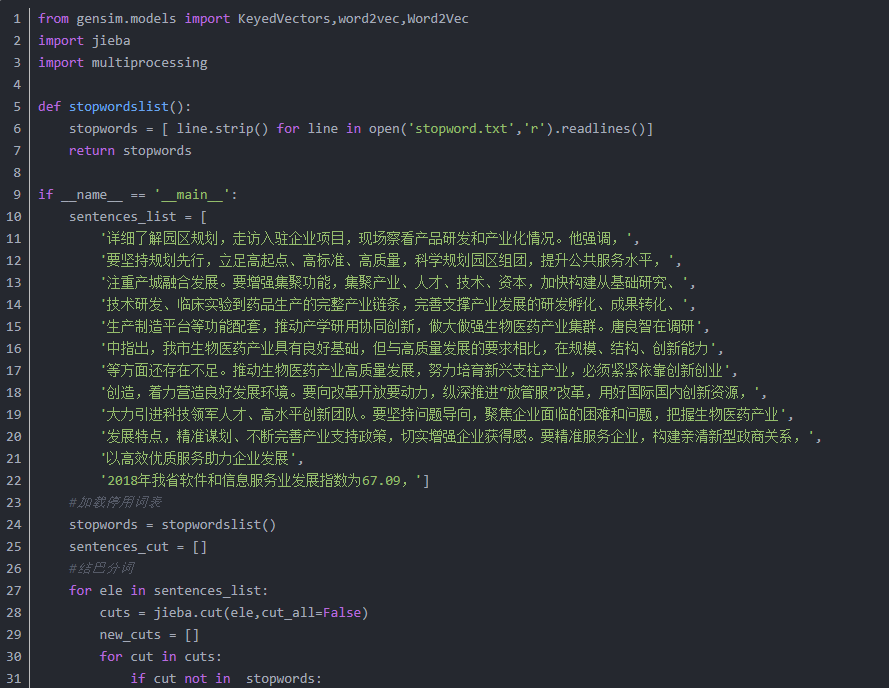
模型保存和加载
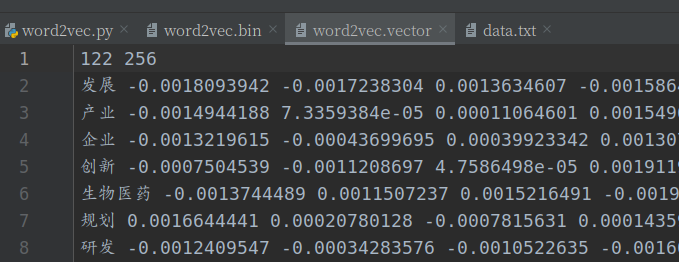
模型保存可以有很多种格式,根据格式的不同可以分为2种,一种是保存为.model的文件,一种是非.model文件的保存。笔者常用的保存格式是.model和.vector直接上代码和结果:

注意使用的API不同,一个是model.save() 一个是 model.wv.save_word2vec_format()。结果如图:.vector和.bin文件直接可以用txt打开可视,它们的内存占用要少一些,加载的时间要多一点。
模型加载,对比如下:
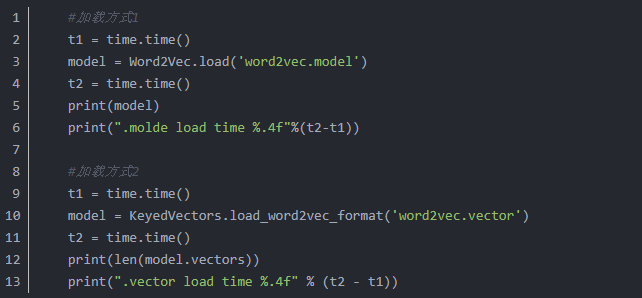
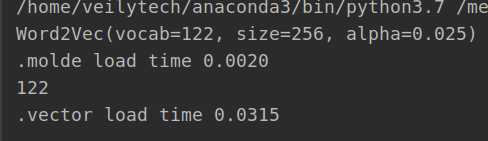
这两种方式的加载在获取词向量的时候应该是差别不大,区别就是.model可以继续训练,.vector的文件不能继续训练。加载速度也可以见,前者比后者快很多。前者时间为0.0020秒后者0.03秒,相差十多倍。
模型的增量训练
模型训练以后,模型中用到的词已经确定下来了,一般都会存在这样的场景,模型训练以后,会有新的语料,也就存在新词,这个时候新词用word2vec就得不到词向量,会报ovo的错误。那么就需要重新训练模型,gensim就提供了一个很好的机制,就是增量训练,新词不用和旧词全部一起训练。部分代码如下:
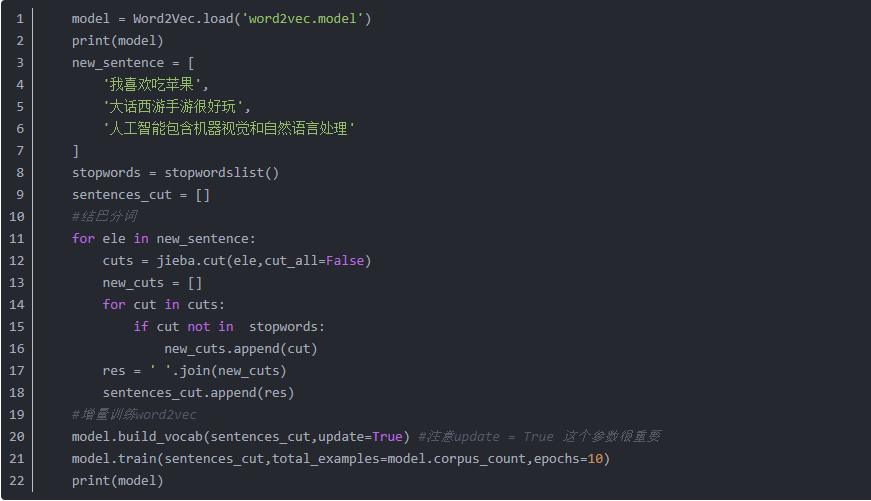

三、模型常用API

现在要获取词向量,直接使用

四、文本相似度计算——文档级别
文本相似度的计算可以分为词、句子、段落和全文这几个层次,全文级别的也就是文档级别的。文档级别的相似任务,作为一个新入坑的小白,很容易就想到这样一条思路:对文档提取关键词,然后计算关键词之间的词移距离。这里面涉及到分词、关键词提取、关键词个数的选择等技术细节,最后还涉及到词移距离的计算,关键词的权重(重要程度)是否带入计算中。这里不考虑很多技术细节,仅仅把提取好的关键词做一个词移距离计算,展示一下gensim.model.word2vecmodelAPI的使用。
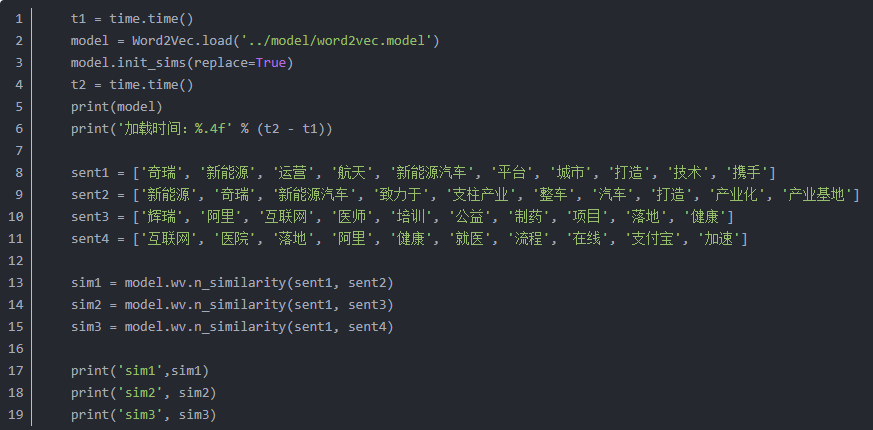
model.wv.n_similarity(ws1,ws2)数据如下:

计算sent1和其他的相似度:
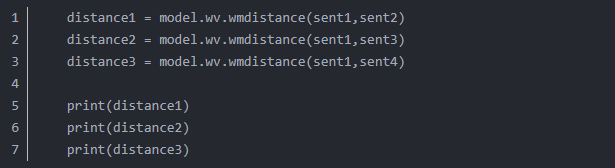
用词移距离来度量的话:
结果如下所示:
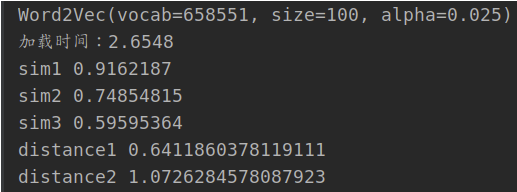
sim值越大文档的相似性就越高,distances的值越小就越相似。这种用关键词来衡量文档的相似度,用词移距离比用cos距离效果更好。在计算词移距离的时候,把关键词的权重引入,效果更好,但是计算是非常耗时的。
参考文章:
《NLP之——Word2Vec详解》
《word2vec两种训练方法》
《Word2Vec模型增量训练》
如想查看全部代码,可点击“阅读原文”查看作者博客
作者:NLP工程师 黄洋
————————————————
版权声明:本文为CSDN博主「colourmind」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/HUSTHY/article/details/103164934
关注我们园区精准化服务快人一步噢!


园宝科技
为园区增效,为企业赋能!
创新|融合|协同|成长
点“在看”给我一朵小黄花

