如何构建企业网站/网站排名分析
【机器学习个人笔记】用sklearn实现特征正则化
我们在学习机器学习的时候会经常听到正则化(Regularization),其一般是用于改善或者减少过度拟合问题。
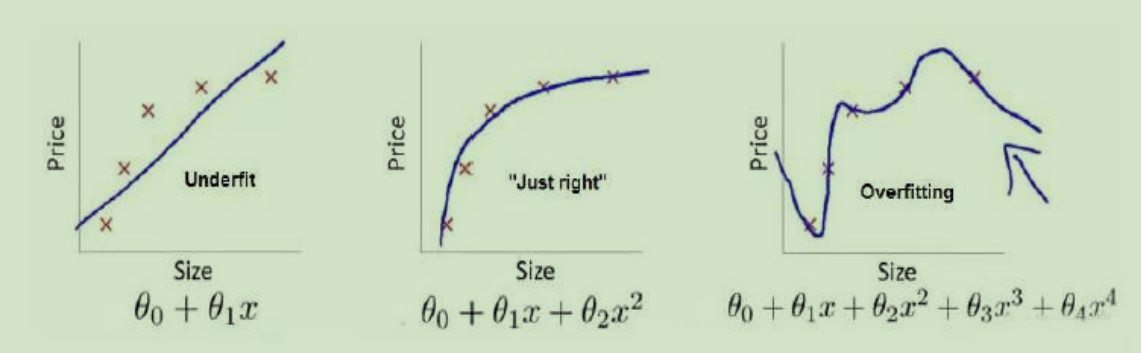
下图是一个回归问题的例子:
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一
个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看
出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的
训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类问题中也存在这样的问题:
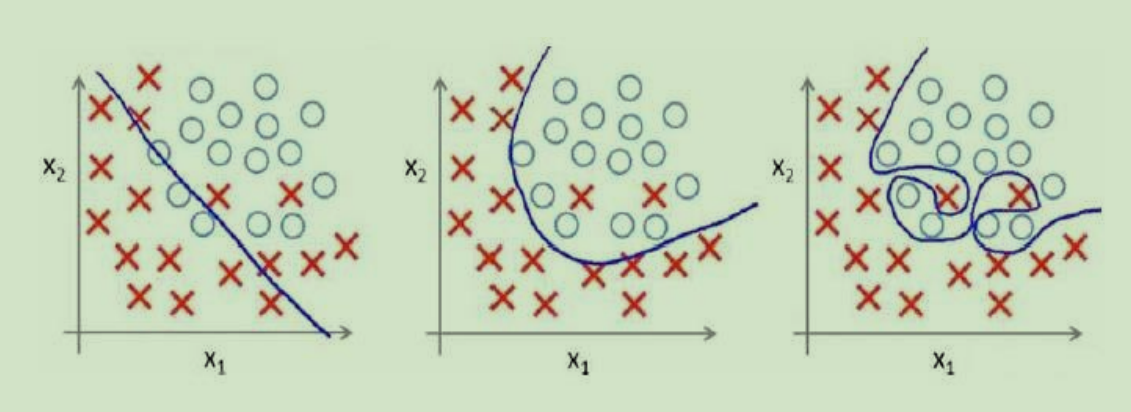
就以多项式理解,x 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
问题是,如果我们发现了过拟合问题,应该如何处理?
- 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用
一些模型选择的算法来帮忙(例如 PCA) - 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
在sklearn里实现正则化非常简单,只需几行代码:
X = [[1,-1,2],[2,0,0],[0,1,-1]]# 使用L2正则化
from sklearn.preprocessing import normalize
X1 = normalize(X, norm = 'l2')# 使用L1正则化
from sklearn.preprocessing import Normalizer
normalizer = Normalizer(norm= 'l1')
X2 = normalizer.fit_transform(X)
normalize()参数:
X : 需要正则化的特征
norm : 设置范数,‘l1’, ‘l2’, 或者’max’, 默认是’l2’
return_norm : boolean, 默认False,如果为True将会返回计算后的norm参数
正则化的结果如图:
