永久网站建设/爱站seo查询
webdriver是:
WebDriver是Selenium体系中设计出来操作浏览器的一套API,可支持多种编程语言,对于Python来说,可以将WebDriver视为Python的一个用于实现Web自动化的第三方类库。
WebDriver一共提供了八种元素定位方法,我们以百度输入框和百度搜索框为例来学习,
百度输入框和百度搜索按钮的代码如下:
<inputid=”kw” class=”s_ipt” autocomplete=”off” maxlength=”100” value=”“ name=”wd”>
<input id=”su” class=”bg s_btn” type=”submit” value=”百度一下”>
1、id定位
HTML规定id属性在HTML文档中必须是唯一的,WebDriver提供的id定位方法就是通过元素的id属性来查找元素。通过id定位百度输入框与搜索按钮,用法如下:
find_element_by_id(“kw”)
find_element_by_id(“su”)
2、name定位
HTML规定name来指定元素的名称,name的属性值在当前页面可以不唯一。通过name定位百度输入框:
find_element_by_name(“wd”)
find_elements_by_name(“wd”)[索引]
3、. By.className()
使用className来进行元素定位时,有时会碰到一个元素指定了若干个class属性值的“复合样式”的情况,出现这种情况必须指定其中一个class属性,不然就会报错:
<button name="sampleBtnName" id="sampleBtnId" class="buttonStyle">I'm Button</button>
browser.find_elements_by_class_name("buttonStyle")
4、tag定位
该方法可以通过元素的标签名称来查找元素。该方法跟之前两个方法的区别是,这个方法搜索到的元素通常不止一个,所以一般建议结合使用findElements方法来使用。比如我们现在要查找页面上有多少个button,就可以用button这个tagName来进行查找,
find_elements_by_tag_name(“input”)[索引]
5、By.linkText()
这个方法比较直接,即通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接。通常一个超文本链接会长成这个样子:
<a href="http://news.baidu.com" target="_blank"class="mnav">新闻</a>
<a href="http://www.hao123.com" target="_blank"class="mnav">hao123</a>
通过link定位链接如下:
find_element_by_link_text(“新闻”)
find_element_by_link_text(“hao123”)
6、partial link定位
parial link定位是对link定位的一种补充,有些文本链接会比较长,这个时候我们可以取文本链接的一部分定位,只要这一部分信息可以唯一地标识这个链接。通过partial link定位百度首页的文本链接的代码如下:
find_element_by_partial_link_text(“新”)
find_element_by_partial_link_text(“hao”)
注意:使用这种方法进行定位时,可能会引起的问题是,当你的页面中不止一个超链接包含About时,findElement方法只会返回第一个查找到的元素,而不会返回所有符合条件的元素。如果你要想获得所有符合条件的元素,还是只能使用findElements方法。通过索引
7、XPath定位
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用XPath进行定位前,我们先了解下什么是XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图(2)所示HTML代码为例,要引用对应的对象,XPath语法如下:
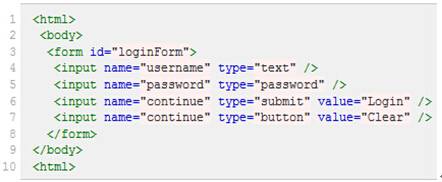
绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):/html/body/form[1]
注意:
- 元素的xpath绝对路径可通过firebug直接查询。
- 一般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。
- 绝对路径以单/号表示,而下面要讲的相对路径则以//表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以/开头时,表示让Xpath解析引擎从文档的根节点开始解析。当xpath路径以//开头时, 则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路径中时,则表示寻找父节点的直接子节点,当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级。弄清这个原则,就可以理解其实xpath的路径可以绝对路径和相对路径混合在一起来进行表示,想怎么玩就怎么玩。
- 验证xpath的对错,我们需要在页面按“CTRL+F”,把定位路径填写,来检验定位的准确性

(1)查找页面上id为loginForm的form元素:
//form[@id='loginForm']
(2)逻辑运算:查找页面上具有name属性为username,且id为loginForm的input元素:
//input[@name='username' and @id='loginForm']
(3)层级定位

//div[@id="u1"]/a[@name="tj_login"]
/表示“儿子”,//表示孙子
(4)函数定位
a、用Text关键字,定位代码如下:

//div[@id="u_sp"]/a[text()="地图"]
b、用contains关键字,contains@属性/text(),value

//span[@id="s_menu_mine"]/div[contains(@class,"mine-text")]
(5)轴定位:轴定位学习连接
8、By.cssSelector()
-
根据 标签定位 tagName(定位的是一组,多个元素)
find_element_by_cssSelector(“div”)
-
根据 id属性定位(注意id使用#表示)
find_element_by_cssSelector("#eleid")
find_element_by_cssSelector(“div#eleid”)
-
根据className属性定位(注意class属性使用.)
find_element_by_cssSelector(“div.eleclass”)
-
根据元素属性定位
4.1 精确匹配:
find_element_by_cssSelector(“div[name=elename]”) 属性名=属性值,精确值匹配
4.2 模糊匹配
find_element_by_cssSelector(“div[name^=elename]”) 从起始位置开始匹配
find_element_by_cssSelector(“div[name$=name2]”) 从结尾匹配
find_element_by_cssSelector(“div[name*=name1]”) 从中间匹配,包含
4.3 多属性匹配
find_element_by_cssSelector(“div[type='eletype][value=‘elevalue’]”) #同时有多属性
find_element_by_cssSelector("div.eleclsss[name=‘namevalue’] #选择class属性为eleclass并且name为namevalue的div节点
find_element_by_cssSelector("div[name=‘elename’][type=‘eletype’]:nth-of-type(1) #选择name为elename并且type为eletype的第1个div节点
还有很多复杂的定位方式,大家可以去学习