wordpress调用树形目录/seo综合查询怎么用
前景提要
最近这段时间的CSDN评论增加很快很快,心思把每一个博客网站的评论都拿下来分析一下,看看自己哪里有不足的地方,看看粉丝们都给我评论了什么,根据粉丝的意愿去继续写博客才是个好的博主啊。
网页分析
首先启动检查,刷新自己的网页后查看XML中寻找存在评论的XML地址,发现能够找到一共含有的评论页数和当前页面的评论内容。

该请求参数除 page 之外均为可固定参数, page 为网页访问页数。
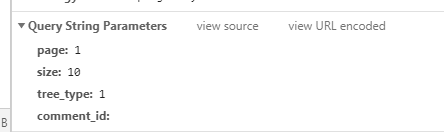
大致参数正确,开始写代码!
完整代码
import urllib
import requests
from lxml import etree
class csdn_comment:def __init__(self,url):self.page_dict = {}if not url[:4] == "http":raise NameError("输入博客地址失败")self.url = urlself.headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",}urls = self.get_url()for url in urls:self.get_page(url)self.get_comment()def get_url(self):html = requests.get(self.url,headers=self.headers)if html.status_code == 200:text = html.textdom = etree.HTML(text)urls = dom.xpath('//*[@id="mainBox"]/main/div[2]/div[*]/h4/a/@href')url = list(map(lambda x:x.split("/")[-1], urls))return urlreturn Nonedef get_page(self,url):data = {'page': '1','size': '10','tree_type': '1','comment_id': ''}page_url = self.url + '/phoenix/comment/list/' + url + "?"+ urllib.parse.urlencode(data)html = requests.post(page_url,headers=self.headers)page_int = html.json()['data']['page_count']self.page_dict[url] = int(page_int)def get_comment(self):one_comment_dict = {}one_comment_list = []self.all_comment_dict = {}for url,all_page in self.page_dict.items():for page in range(1,int(all_page)+1):data = {'page': str(page),'size': '10','tree_type': '1','comment_id': ''}comment_url = self.url + '/phoenix/comment/list/' + url + "?"+ urllib.parse.urlencode(data)html = requests.post(comment_url,headers=self.headers)lists = html.json()['data']['list']for comment_list in lists:comment = comment_list['info']['Content']author = comment_list['info']['NickName']if author:one_comment_dict[author] = commentelse:one_comment_dict['匿名人士'] = commentone_comment_list.append(one_comment_dict)self.all_comment_dict[url] = one_comment_listself.write_json()def write_json(self):import jsonall_comment_str = json.dumps(self.all_comment_dict,ensure_ascii=False)with open('all_comment.txt','w') as f:f.write(all_comment_str)
csdn_comment('CSND博客的URL')