怎么改网站模板/惠州网络营销公司
梯度
在微积分中,对多元函数的参数求偏导数,把求得的各个参数的偏导数以向量的形式表示出来,就是梯度。举个例子,对于函数f(x, y),我们分别对自变量x和y求偏导数为∂f/∂x和∂f/∂y,那么梯度向量就是(∂f/∂x, ∂f/∂y),简称grad f(x, y)或者▽f(x, y)。
从几何上讲,梯度其实就是函数变化增加最快的地方,沿着梯度向量的方向会更容易找到函数的最大值,沿着梯度向量的反方向会更容易找到函数的最小值。
因此,最小化损失函数就可以通过梯度下降法来进行不断迭代求解,最终得到最小化的损失函数和模型参数值。
梯度是微积分中的一个重要概念。
- 在单变量函数中,梯度就是函数的微分,代表着函数在某个给定点的切线的斜率。
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向或反方向就指明了函数在给定点的上升或下降最快的方向。
梯度下降法
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性与非线性均可),是一个使损失函数越来越小的优化算法。在无求解机器学习算法的模型参数问题(约束优化问题)中,梯度下降是最常用的方法之一(另一种常用方法是最小二乘法),梯度下降法可以通过一步步的迭代求解得到最小化的损失函数和模型参数值。在机器学习中,基于基本的梯度下降法主要有随机梯度下降法和批量梯度下降法。
我们可以将梯度下降法比作下山,但是我们并不知道下山的路,只能通过一步一步的试探来下山。假设下山过程无安全性问题,那么每走到一个位置的时候,我们就会求当前位置的梯度,并沿着梯度的负方向,也就是当前最陡峭的位置(这样走更接近山下)向下走一步。类似这种方法一步一步得走,直到我们感觉已经到了山脚。这里为什么说是感觉,那是因为山会有多个峰,这种走法不一定能到正真的山脚,而可能只是到了某个局部山峰的最低处,也就是局部最优解。
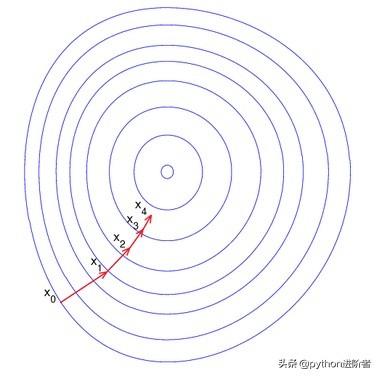
梯度下降
这个问题在特征较少的情况下可能会导致陷入某个局部最优解,但当特征足够时,出现这种情况的概率就几乎为0了,因此当我们有成百上千万甚至上亿的特征时可以忽略这一问题。
在梯度下降法调优中,影响较大的三个因素为步长、初始值和归一化。
- 步长:又称学习率,决定了梯度下降迭代过程中每一步沿梯度负方向前进的长度。也就是上述所说的沿最陡峭的位置走的那一步的长度。
- 初始值:随机选取的值,当损失函数是非凸函数时,找到的可能是局部最优解,此时需要多测试几次,从局部最优解中找出最优解。当损失函数是凸函数时,得到的解就是最优解。
- 归一化:若不进行归一化,会导致收敛速度很慢,从而形成“之”字形的路线。
Mini-batch的梯度下降法
对整个训练集进行梯度下降法时,我们需要处理整个训练数据集,然后才能进行一步梯度下降,即每走一步梯度下降都需要对整个训练集进行一次处理。可以预见的是,当训练数据集很大的时候梯度下降处理速度会非常缓慢,并且我们也不可能将庞大的训练数据集全部一次性地载入到内存或显存中。基于这种情况,我们考虑将大数据集分割成小数据集,然后对每个小数据集进行训练,这个训练子集就称为Mini-batch,这种梯度下降法也叫小批量梯度下降。
在PyTorch中,使用梯度下降法时就是使用Mini-batch来进行训练的,例如在之前章节中介绍使用DataLoader进行数据的加载与预处理中,其中的batch_size参数其实就是一个Mini-batch的大小。对于一般的梯度下降法而言,一个epoch只能进行一次梯度下降,而对于Mini-batch的梯度下降法而言,有多少个Mini-batch,一个epoch就可以进行多少次梯度下降。
- 当训练数据集比较小时,能够一次性读入到内存或显存中时,不需要使用Mini-batch。
- 当训练数据集比较大时,无法一次性读入到内存或显存中时,只能使用Mini-batch来分批次进行计算。
- Mini-batch的size计算规则如下:在内存允许的最大情况下使用2的N次方个size。
PyTorch中的常用优化器
在PyTorch中有专门提供优化器的库——torch.optim,其中实现了各种优化算法,我们可以直接调用。
- torch.optim.SGD
SGD随机梯度下降算法,除了模型参数外,还需要设置学习率lr。此外还可以设置momentum,表示带有动量的SGD。
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)SGD的优点是梯度计算快,缺点是随机选择梯度时会引入噪声,使权值更新的方向不一定正确,但只要噪声不是特别大,SGD还是能够很好地收敛的。此外,带有动量的SGD也是主要解决噪声问题以及收敛过程中和正确梯度相比来回摆动比较大的问题。
- torch.optim.RMSprop
RMSprop也是一种可以加快梯度下降的算法,可以减小某些维度更新波动较大的情况,使梯度下降的速度更快。RMSprop已经被证明是一种有效且实用的深度神经网络优化算法,在深度学习实用中非常常用。
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01, alpha=0.99)- torch.optim.Adam
Adam算法的基本思想就是将动量momentum和RMSprop结合起来形成的一种适用于不同深度学习结构的优化算法。在Adam中,动量直接并入了梯度-阶矩的估计。Adam算法在实际操作中也是很常见的。
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08)Adam( )函数中lr、betas、eps都可以直接使用默认值,因此使用起来会更简单。
方差与偏差
偏差度量了学习算法的期望预测与真实结果的偏离程序,即刻画了学习算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能的变换,即模型的泛化能力。
正则化
利用正则化可以解决高方差的问题,正则化是成本函数中加入的一项正则化项。
- L1正则化
损失函数基础上加上权重参数的绝对值。
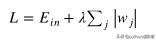
L1正则化
- L2正则化
损失函数基础上加上权重参数的平方和。
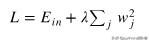
L2正则化
需要注意的是,L1正则化相比于L2正则化更容易获得稀疏解。