罗岗网站建设公司/长沙靠谱的关键词优化
1 KNN
1.1 基本的KNN模型
KNN(k-nearest neighbor)的思想很简单,就是解决评价未知物品U的问题,只需找k个与U相似的已知的东西,并通过k个已知的对U再对进行评估。
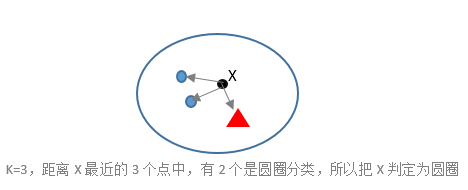
假如要预测用户A对一部电影M的评分,根据kNN的思想,我们可以先找出k个对M进行过评分的相似用户,然后再用这些用户的评分预测用户A对电影M的评分。(user-based-KNN)
又或者先找出k个与用户A评价过的相似电影,然后再用这k部电影的评分预测用户A对M的评分。(item-based kNN)
这两种方法的思想和实现都大同小异,我们在下文中只讨论item-based kNN,并且将其简称为kNN。
根据kNN的思想,我们可以将kNN分为以下三个步骤(假设预测用户u对物品i的评分):
(1) 计算相似度
推荐系统中常用的相似度有:Pearson correlation,Cosine,Squared Distance,其中Pearson correlation的运用最为普遍。
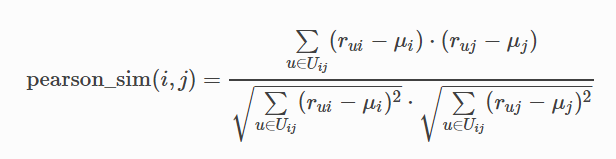
Uij表示对物品i和用户j都有过评分的用户集合。
(2) 选择邻居
在用户u评过分的所有电影中,找出k个与电影m相似度最高的电影,并用N(u, m)表示这k个电影的集合。
(3) 计算预测值
有了k个相似的电影后,就可以用以下公式预测评分:
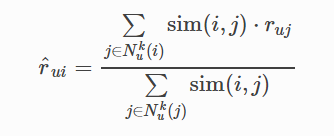
2 数据稀疏性与KNN的改进
现在待处理的推荐系统规模越来越大,用户和商品数目动辄百千万计,两个用户之间选择的重叠非常少。如果用用户和商品之间已有的选择关系占所有可能存在的选择关系的比例来衡量系统的稀疏性,那么平时研究最多的MovieLens数据集的稀疏度是4.5%,Netflix是1.2%,Bibsonomy是0.35%,Delicious是0.046%。
从Pearson correlation的计算公式上看,如果某两个电影的交集大小比其它电影的交集要小得多,那么这两个电影的相似度的计算就非常受到少数用户打分的影响,因此这样得到的结果可靠性就比较低。
由上面描述的数据稀疏性可知,在推荐系统中出现某些交集的较小的情况将会十分平常,而这会大大加强相似度的不可靠性。
为了预测结果的可靠性,有必要减轻交集较小时的不稳定性,因此我们要根据交集的大小对相似度进行一次压缩(shrinkage):
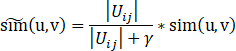
Python实现(surprise包):
from surprise import KNNBasic
from surprise import Dataset
from surprise import dump
from surprise.accuracy import rmse#加载movielens-100k数据集(本地没有的情况会自动下载)
data = Dataset.load_builtin('ml-100k')#此处使用KNNBasic算法
algo = KNNBasic()for trainset, testset in data.folds():algo.train(trainset)predictions = algo.test(testset)rmse(predictions)dump.dump('./dump_file', predictions, algo)输出结果:
Computing the msd similarity matrix...warnings.warn('train() is deprecated. Use fit() instead', UserWarning)
Done computing similarity matrix.
RMSE: 0.9758
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9806
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9797
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9793
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9769
参数调节:
class surprise.prediction_algorithms.knns.KNNBasic(k=40, min_k=1, sim_options={}, verbose=True, **kwargs)
| Parameters 参数: |
|
|---|