什么是静态网页和动态网页/手机优化是什么意思
前言
我们在爬取网页时经常会遇到动态渲染页面,对于普通的Ajax,可以利用requests和urllib来实现数据爬取,但是javascript不止ajax一种,其规律有时很难发现,这一过程也会浪费很多时间。而selenium可以模拟浏览器执行特定的动作,这样就不用在乎javascript是如何渲染页面了。本次的实验对象是京东商品的评论,网址如下:
【ThinkPad】联想ThinkPad E580 15.6英寸轻薄窄边框笔记本电脑ibm大屏办公笔记本 英特尔酷睿 i5-7200U 8G 256G 1WCD【行情 报价 价格 评测】-京东item.jd.com
当然你也可以使用selenium模拟浏览器在京东网页中搜索相关商品,操作也比较简单。所以我们专注讲解爬取商品评论的核心代码。
环境准备
1.我使用的编译器是pycharm
首先需要selenium库来模拟浏览器执行相关操作
在解析页面内容时我们会用到pyquery。
两个库可直接在anaconda中添加。
2.为方便以后selenium的学习,建议下载Splash
Splash是一个Javascript渲染服务,相当于一个轻量级的浏览器。
下载Splash前需要下载docker,官网下载地址如下:
https://www.docker.com/products/docker-desktop
下载前需要注册,如果是Win10专业版可以直接安装成功,Win10家庭版的话还需要安装hyper-V服务,将如下复制到.cmd文件中以管理员身份执行,完成hyper-V安装。
pushd "%~dp0"
dir /b %SystemRoot%servicingPackages*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%servicingPackages%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
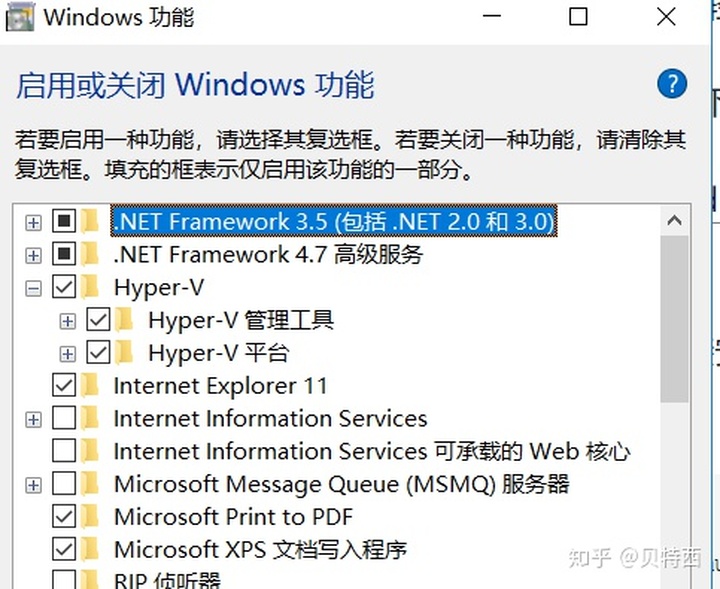
安装后查看Windows功能,可以看到hyper-v:
随后还要伪装成专业版,不然安装时还会报错,方法是:
打开注册表,定位到HKEY_LOCAL_MACHINEsoftwareMicrosoftWindows NTCurrentVersion,点击current version,在右侧找到EditionId,右键点击EditionId 选择“修改“,在弹出的对话框中将第二项”数值数据“的内容改为Professional,然后点击确定。再安装docker.exe文件即可正常安装。
然后在终端输入如下代码安装splash:
docker run -p 8050:8050 scrapinghub/splash
即可安装splash。
代码实战
1.观察商品界面,找到评论处,发现html后面会加上'#html',我们爬取时可以直接从这个页面中爬取。
爬取思路是先获取评论页面,并可以执行翻页功能,核心就是找到‘下一页’按钮。
右键‘下一页’,点击检查,获取节点信息:
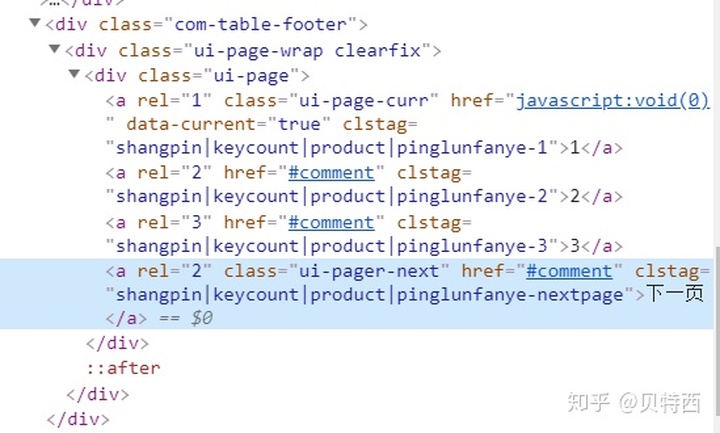
可以看到它的父元素的class为ui=page,他的class为'ui-pager-next',爬取代码如下:
def commodity_page(page):print('正在爬取第', page, '页')try:url = 'https://item.jd.com/46339527372.html#comment'browser.get(url)if page == 1:browser.maximize_window() #避开右下角图标try:next_page = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.ui-page>a.ui-pager-next')))except:next_page = 0print(next_page)# ActionChains(browser).move_to_element(next_page).perform()## ActionChains(browser).move_to_element(mouse).perform()time.sleep(3)browser.get(url)get_comments()if next_page != 0:# time.sleep(3)next_page = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.ui-page>a.ui-pager-next')))next_page.click()page = page+1commodity_page(page) #获取评论信息else:print('已经是最后一页')returnexcept TimeoutException:print('连接超时')代码量不多,但是有两个大坑。第一个坑如下:

报错的意思就是'下一页'按钮被覆盖,观察界面,它被右下角的图标覆盖,如下图。
打开浏览器,要想去掉它,可以通过点击叉号或者鼠标悬停一段时间然后移出,但是更简单的方法是改变浏览器大小,直接避开了这个问题。代码如下:
browser.maximize_window()第二个坑是在爬取第三页的时候报错

这里必须重新寻找下一页的按钮,否则只能爬取两页的数据。
2.获取评论信息
同样的方法查找评论具体信息的节点的class为comment-0,然后通过pyquery解析界面,筛选出评论内容,代码如下:
html = browser.page_sourcedoc = pq(html)items = doc('#comment-0').items()for item in items:comment = {'content': item.find('.comment-con').text()}将结果打印,验证是否成功:

评论爬取成功!
补充
本文侧重于selenium的使用,并未对数据在数据库上进行存储,解析数据时也可以使用其它库,关于这方面的内容可以查看这一篇文章:
贝特西:通过爬虫爬取2000名明星照片进行颜值评测,你心中的男/女神有多少评分?zhuanlan.zhihu.com