果洛wap网站建设公司/搜索引擎排名机制
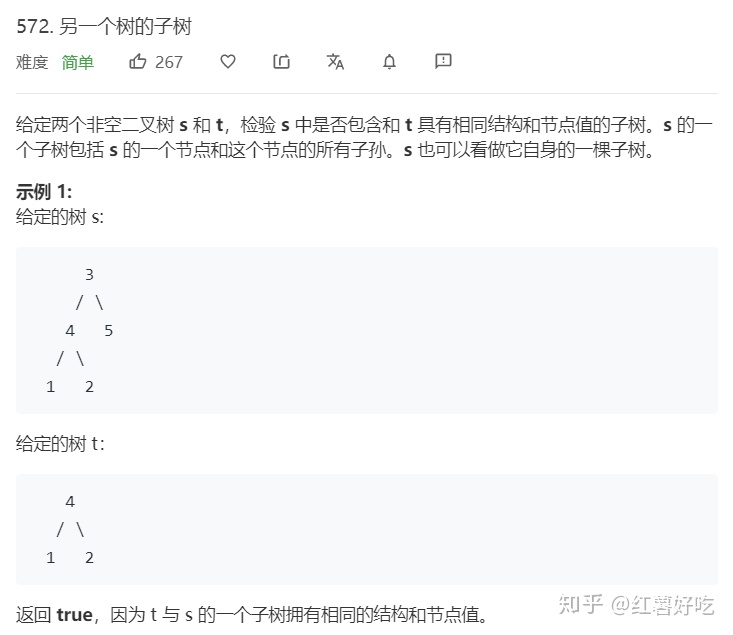
思路一:dfs里面嵌套dfs,第一层dfs遍历s树,然后以当前节点代表的子树和t进行dfs判断是否相等。时间复杂度为O(s*t)
# Definition for a binary tree node.
思路二:kmp
如何更好地理解和掌握 KMP 算法? - 海纳的回答 - 知乎 https://www.zhihu.com/question/21923021/answer/281346746
从这篇讲解里面可以看出,求next数组的就是,以模式字符串为主字符串,以模式字符串的前缀为目标字符串,也就是通过这个过程就能求出主字符串前缀后缀最大的重复长度了。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:def compute_next(self,s):Next = [0]*len(s)i = 1j = 0while i < len(s):if s[j] == s[i]:j += 1i += 1if i < len(s):Next[i] = jelse:i += 1j = 0Next[0] = -1 #在下面代码里有妙用return Nextdef isSubtree(self, s: TreeNode, t: TreeNode) -> bool:#序列化s,ttmp = []def xulie(cur):if not cur:tmp.append('#')return tmp.append(cur.val)xulie(cur.left)xulie(cur.right)xulie(s)s = tmptmp = []xulie(t)t = tmpNext = self.compute_next(t)j = 0i = 0while i < len(s) and j <len(t): #j==-1说明次数和t的第0位都不匹配,要把i也加1,防止死循环if j==-1 or s[i] == t[j]:j+=1i+=1else:j = Next[j]return j==len(t)