网站建设违约/百度广告平台电话
目录
0 前言
1 需求案例
2 问题分析
0 前言
我们都知道oracle,mysql或greenplum中都支持不等连接,但在hive数据库中2.1之前的版本是不支持的,那么对一些需要不等连接的语句就需要改写,或寻找其他实现方案,那么有没有一种替代的解决方案呢?本文就针对这一问题进行探讨。
1 需求案例
如下两张表
t表
| id | dt | |
| 1 | 2022-06-03 | |
| 2 | 2022-05-04 | |
| 3 | 2022-04-01 | |
| 4 | 2022-05-22 | |
t1表
| id | dt |
| 1 | 2022-04-01 |
| 2 | 2022-05-30 |
| 3 | 2022-04-03 |
两张表根据id进行关联其中t表为主表,并获取t表中dt大于t1表的中的dt的数据。
数据准备
创建t表
create table t as
select 1 as id,'2022-06-03' as dt
union all
select 2 as id,'2022-05-04' as dt
union all
select 3 as id,'2022-04-01' as dt
union all
select 4 as id,'2022-05-22' as dtt.id t.dt
1 2022-06-03
2 2022-05-04
3 2022-04-01
4 2022-05-22创建t1表
create table t1 as
select 1 as id,'2022-04-01' as dt
union all
select 2 as id,'2022-05-30' as dt
union all
select 3 as id,'2022-04-03' as dtt1.id t1.dt
1 2022-04-01
2 2022-05-30
3 2022-04-03
2 问题分析
情形1:非等值连接区间连接
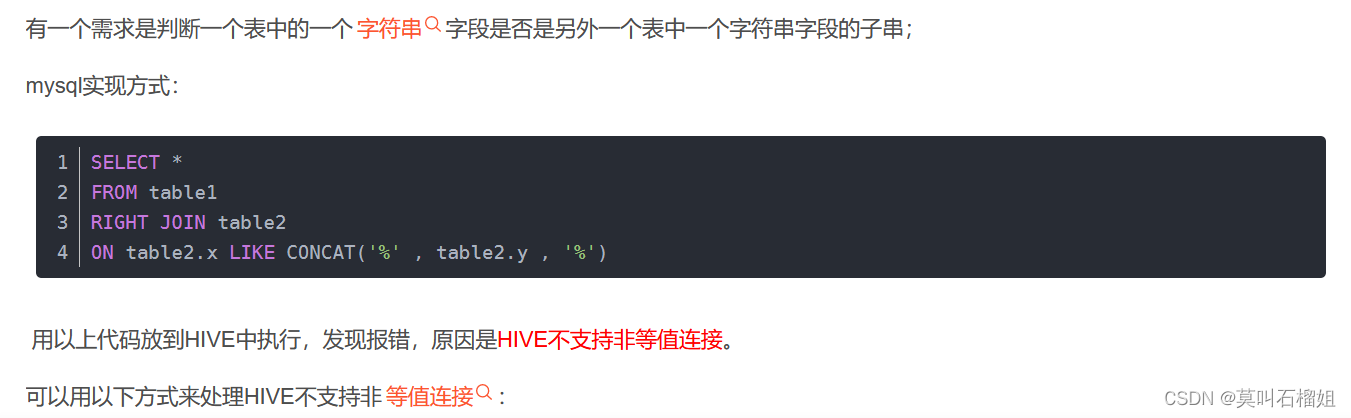
针对 上述问题如果在mysql中我们做法如下:
select t.id, t.dt, t1.dt
from t lfetjoin t1 on t1.id = t1.idand t.dt > t1.dt但是在hive2.2之前的版本中会报语法错误,针对此问题的替代方案,查阅了一些资料,给出的解决方案如下:一种是采用locate()匹配的方式
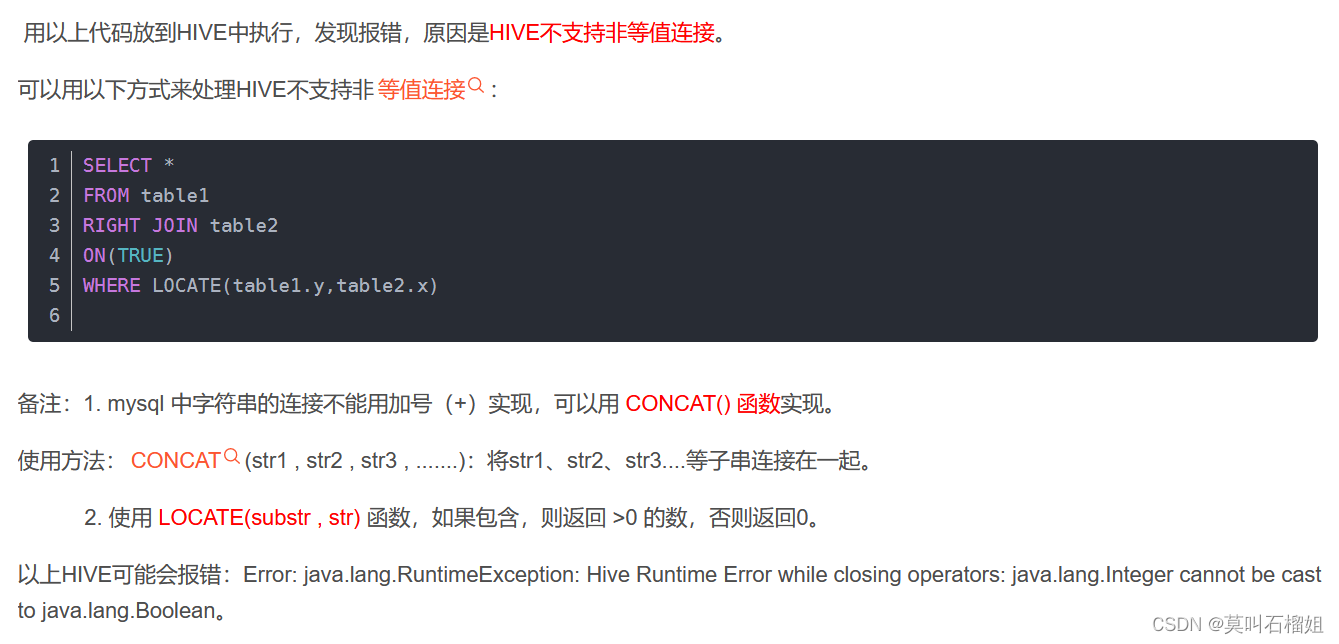 或是采用自关联在where中进行过滤
或是采用自关联在where中进行过滤
其实这两种方式本质上一样的,都是进行笛卡尔集然后where中过滤,这种对于join类型的关联没什么问题,但对于left join或right join就有问题了,因为数据的记录数会丢失。为了保证记录数不丢失,本文采用嵌套关联的方式,也就是原来的主表不变,把需要不等条件的这种放在where条件中过滤单独求出结果集,外层再根据关联条件和主表再做left join具体SQL如下:
第一步:求出满足条件的结果集
select t.id, t.dt,t1.dt
from tleft join t1 on t.id = t1.id
where t.dt > coalesce(t1.dt,0)
order by id结果如下:
t.id t.dt t1.dt
1 2022-06-03 2022-04-01
4 2022-05-22 NULL第二步:用主表t left join 第一步的结果集
select *
from tleft join(select t.id as id, t1.dt as dtfrom tleft join t1 on t.id = t1.idwhere t.dt > coalesce(t1.dt, 0)) t2on t.id = t2.id结果如下:
OK
t.id t.dt t2.id t2.dt
2 2022-05-04 NULL NULL
3 2022-04-01 NULL NULL
1 2022-06-03 1 2022-04-01
4 2022-05-22 4 NULL
Time taken: 3.392 seconds, Fetched: 4 row(s)如果直接采用自关联形式获取结果,代码如下:
select t.id, t.dt,t1.dt
from t,t1
where t.id=t1.idand t.dt > coalesce(t1.dt,0)
order by id最终结果如下:
t.id t.dt t1.dt
1 2022-06-03 2022-04-01
Time taken: 2.291 seconds, Fetched: 1 row(s)可以看出最终的结果集变小,不是想要的结果。
对于关联健如本题的id,本身关联的时候不能唯一确定一条数据,也就是关联的时候数据产生了膨胀,这类求解的时候注意上层去重。
情形2:非等值连接or连接
对于本题外,如果非等值连接中出现or连接的这种情况,可以采用union的形式进行改写。例如如下数据
t表
| id | dt | |
| 1 | 2022-06-03 | |
| 2 | 2022-05-04 | |
| 3 | 2022-04-01 | |
| 4 | 2022-05-22 | |
t1表:
| id | dt1 | dt2 | |
| 1 | 2022-06-03 2022-05-03 | ||
| 2 | 2022-05-25 2022-05-04 | ||
| 3 | 2022-03-01 2022-05-04 | ||
找出t表中时间字段dt在t1表中dt1,dt2任意出现的id,及时间,保留t表中数据,如果能够匹配到取匹配的时间,未匹配到置为NULL
数据准备:
create table t as
select 1 as id,'2022-06-03' as dt
union all
select 2 as id,'2022-05-04' as dt
union all
select 3 as id,'2022-04-01' as dt
union all
select 4 as id,'2022-05-22' as dt
------------------
create table t1 as
select 1 as id,'2022-06-03' as dt1,'2022-05-03' as dt2
union all
select 2 as id,'2022-05-25' as dt, '2022-05-04' as dt2
union all
select 3 as id,'2022-03-01' as dt1, ' 2022-05-04' as dt2
其中mysql的实现方法:
select t.id,case when t1.id is not null then t.dt else null end as dt
from tjoin t1
on t.id = t1.id
and (t.dt=t1.dt1 or t.dt=t1.dt2)hive中实现方法:
select id1 as id,max(case when id2 is not null then dt else null end) as dt
from
(select cast(t.id as string) as id1,t.dt as dt,cast(t1.id as string) as id2
from tleft join t1
on t.id = t1.id
and t.dt=t1.dt1
union
select cast(t.id as string) as id1,t.dt as dt,cast(t1.id as string) as id2
from t
left join t1
on t.id = t1.id
and t.dt=t1.dt2
) t
group by id1结果如下:
OK
id dt
1 2022-06-03
2 2022-05-04
3 NULL
4 NULL
Time taken: 3.343 seconds, Fetched: 4 row(s)采用union或union all的方式代替关联中or的时候,根据上层所求的需要酌情去重。如果本题没有其他限制,只求id,那么采用union的方式就不要上层再去去重,本题中group by id1的方式就是为了去重,去不去重是根据需要和你需要展示的字段来看的。
针对本问题还有一种更优雅的实现方式,借助于loacte()的字符串匹配模式进行匹配,具体SQL如下:
select t.id
,case when locate(t.dt,concat_ws(',',t1.dt1,t1.dt2))>0 then t.dt else null end as dt
from t
left join t1
on t.id = t1.id结果如下:
t.id dt
2 2022-05-04
3 NULL
1 2022-06-03
4 NULL2 小结
本文总结了hive left join 时采用不等连接的实现方法,其归为两类一类是基于区间的不等连接,一类是基于or形式的匹配连接,两种连接采用不同的实现思路。基于区间的不等连接采用left join 的嵌套形式,目的是确保数据条数和主表一致,基于or形式的匹配连接,给出了两种思路,一种采用union的形式,一种采用locate()匹配形式,其中locate()的形式更优雅。