文章目录 一、导包 二、读取数据 三、获取分类特征和数值特征 四、数据处理 五、使用具名元组为特征做标记 六、构建模型 6.1 构建输入层 6.2 将类别特征进行embedding 6.3 将所有的sparse特征embedding进行拼接 6.4 构建残差块 6.5 构建输出层 6.6 构建模型 七、训练模型 7.1 构建模型 7.2 编译模型 7.3 准备输入数据 7.4 模型训练
from collections import namedtuple import tensorflow as tf
from tensorflow import keras
from tensorflow. keras. layers import *
from tensorflow. keras. models import * from tqdm import tqdmfrom sklearn. model_selection import train_test_split
from sklearn. preprocessing import MinMaxScaler, LabelEncoderimport pandas as pd
import numpy as np
"""读取数据"""
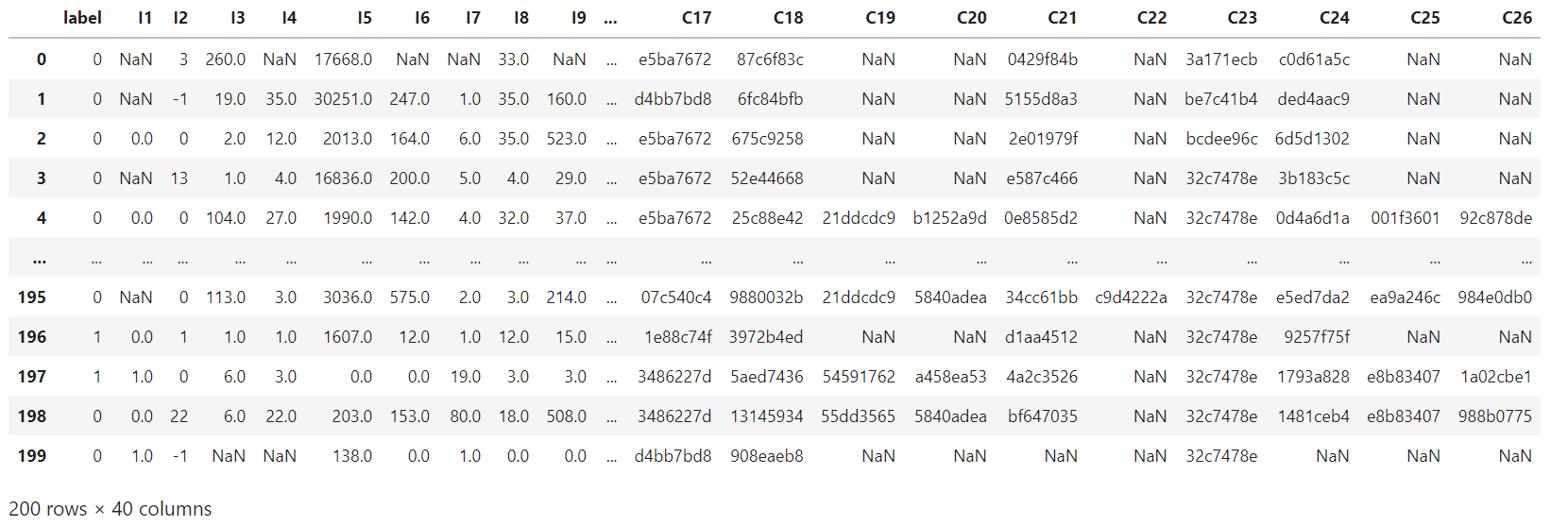
data = pd. read_csv( './data/criteo_sample.txt' )
"""获取分类特征和数值特征"""
columns = data. columns. values
dense_features = [ feat for feat in columns if 'I' in feat]
sparse_features = [ feat for feat in columns if 'C' in feat]
"""数据处理"""
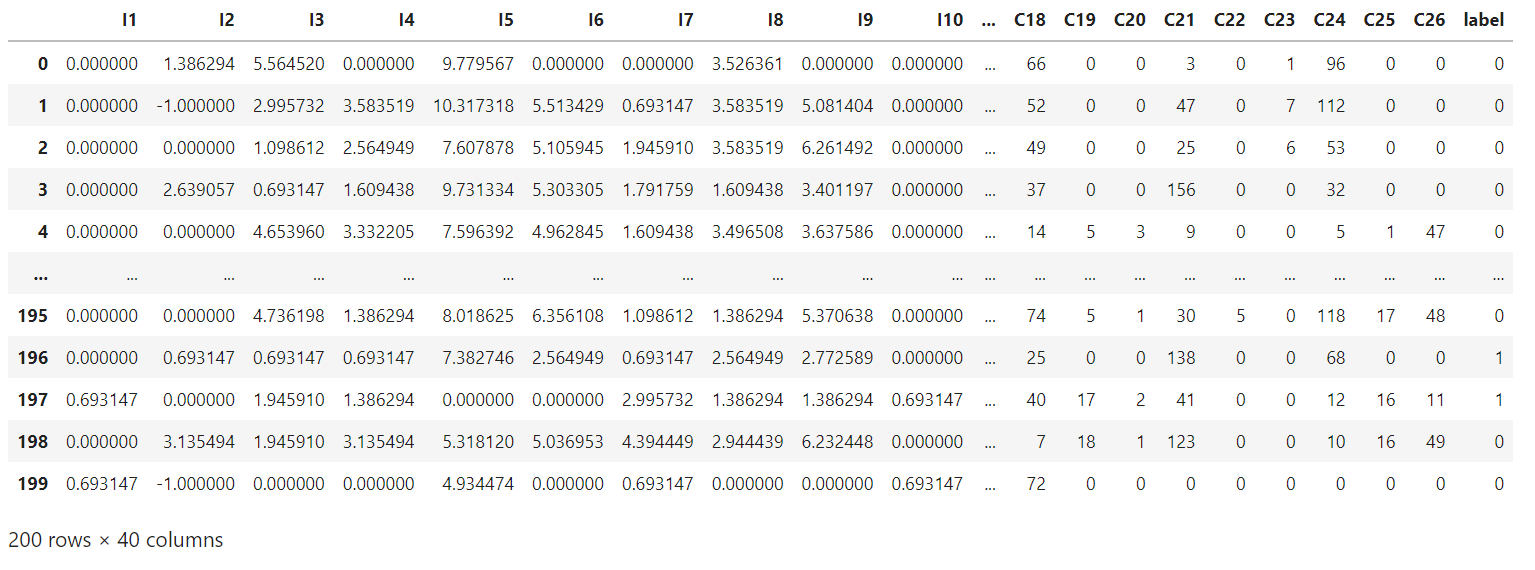
def data_process ( data, dense_features, sparse_features) : data[ dense_features] = data[ dense_features] . fillna( 0.0 ) for f in dense_features: data[ f] = data[ f] . apply ( lambda x: np. log( x+ 1 ) if x > - 1 else - 1 ) data[ sparse_features] = data[ sparse_features] . fillna( "0" ) for f in sparse_features: le = LabelEncoder( ) data[ f] = le. fit_transform( data[ f] ) return data[ dense_features + sparse_features]
train_data = data_process( data, dense_features, sparse_features)
train_data[ 'label' ] = data[ 'label' ]
train_data
"""使用具名元组为特征做标记"""
SparseFeat = namedtuple( 'SparseFeat' , [ 'name' , 'vocabulary_size' , 'embedding_dim' ] )
DenseFeat = namedtuple( 'DenseFeat' , [ 'name' , 'dimension' ] ) dnn_features_columns = [ SparseFeat( name= feat, vocabulary_size= data[ feat] . nunique( ) , embedding_dim = 4 ) for feat in sparse_features] + [ DenseFeat( name= feat, dimension= 1 ) for feat in dense_features]
dnn_features_columns
"""构建输入层"""
def build_input_layers ( dnn_features_columns) : dense_input_dict, sparse_input_dict = { } , { } for f in dnn_features_columns: if isinstance ( f, SparseFeat) : sparse_input_dict[ f. name] = Input( shape= ( 1 , ) , name= f. name) elif isinstance ( f, DenseFeat) : dense_input_dict[ f. name] = Input( shape= ( f. dimension, ) , name= f. name) return dense_input_dict, sparse_input_dict
"""将类别特征进行embedding"""
def build_embedding_layers ( dnn_features_columns, input_layers_dict, is_linear) : embedding_layer_dict = { } sparse_feature_columns = list ( filter ( lambda x: isinstance ( x, SparseFeat) , dnn_features_columns) ) if dnn_features_columns else [ ] if is_linear: for f in sparse_feature_columns: embedding_layer_dict[ f. name] = Embedding( f. vocabulary_size + 1 , 1 , name= '1d_emb_' + f. name) else : for f in sparse_feature_columns: embedding_layer_dict[ f. name] = Embedding( f. vocabulary_size + 1 , f. embedding_dim, name= 'kd_emb_' + f. name) return embedding_layer_dict
"""将所有的sparse特征embedding进行拼接"""
def concat_embedding_list ( dnn_features_columns, input_layer_dict, embedding_layer_dict, flatten= False ) : sparse_feature_columns = list ( filter ( lambda x: isinstance ( x, SparseFeat) , dnn_features_columns) ) embedding_list = [ ] for f in sparse_feature_columns: _input = input_layer_dict[ f. name] _embed = embedding_layer_dict[ f. name] embed = _embed( _input) if flatten: embed = Flatten( ) ( embed) embedding_list. append( embed) return embedding_list
"""构建残差块"""
class ResidualBlock ( Layer) : def __init__ ( self, units) : super ( ResidualBlock, self) . __init__( ) self. units = unitsdef build ( self, input_shape) : out_dim = input_shape[ - 1 ] self. dnn1 = Dense( self. units, activation= 'relu' ) self. dnn2 = Dense( out_dim, activation= 'relu' ) def call ( self, inputs) : x = inputsx = self. dnn1( x) x = self. dnn2( x) x = Activation( 'relu' ) ( x + inputs) return x
"""构建输出层"""
def get_dnn_logits ( dnn_inputs, block_nums= 3 ) : dnn_out = dnn_inputsfor i in range ( block_nums) : dnn_out = ResidualBlock( 64 ) ( dnn_out) dnn_logits = Dense( 1 , activation= 'sigmoid' ) ( dnn_out) return dnn_logits
"""构建模型"""
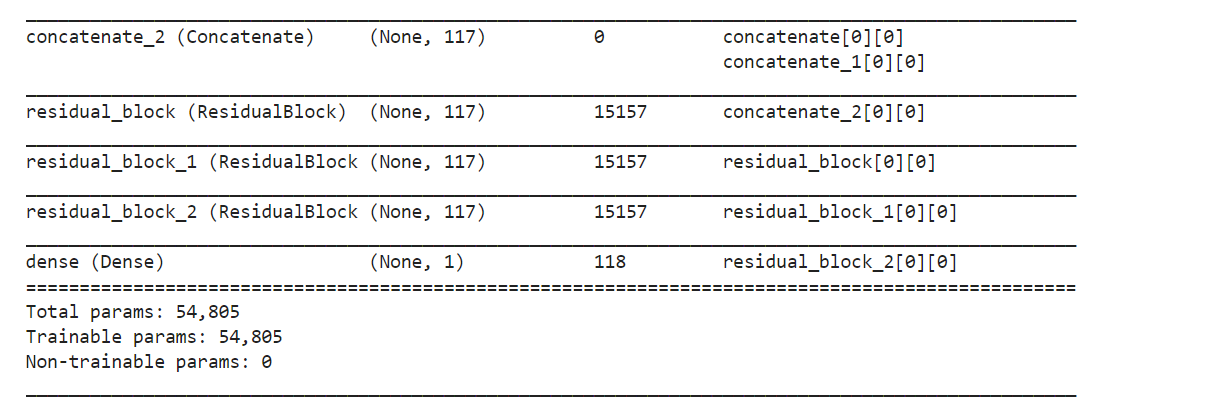
def DeepCrossing ( dnn_features_columns) : dense_input_dic, sparse_input_dic = build_input_layers( dnn_features_columns) input_layers = list ( dense_input_dic. values( ) ) + list ( sparse_input_dic. values( ) ) embedding_layer_dict = build_embedding_layers( dnn_features_columns, sparse_input_dic, is_linear= False ) dense_dnn_list = list ( dense_input_dic. values( ) ) dense_dnn_inputs = Concatenate( axis= 1 ) ( dense_dnn_list) sparse_dnn_list = concat_embedding_list( dnn_features_columns, sparse_input_dic, embedding_layer_dict, flatten= True ) sparse_dnn_inputs = Concatenate( axis= 1 ) ( sparse_dnn_list) dnn_inputs = Concatenate( axis= 1 ) ( [ dense_dnn_inputs, sparse_dnn_inputs] ) output_layer = get_dnn_logits( dnn_inputs, block_nums= 3 ) model = Model( input_layers, output_layer) return model
history = DeepCrossing( dnn_features_columns)
history. summary( )
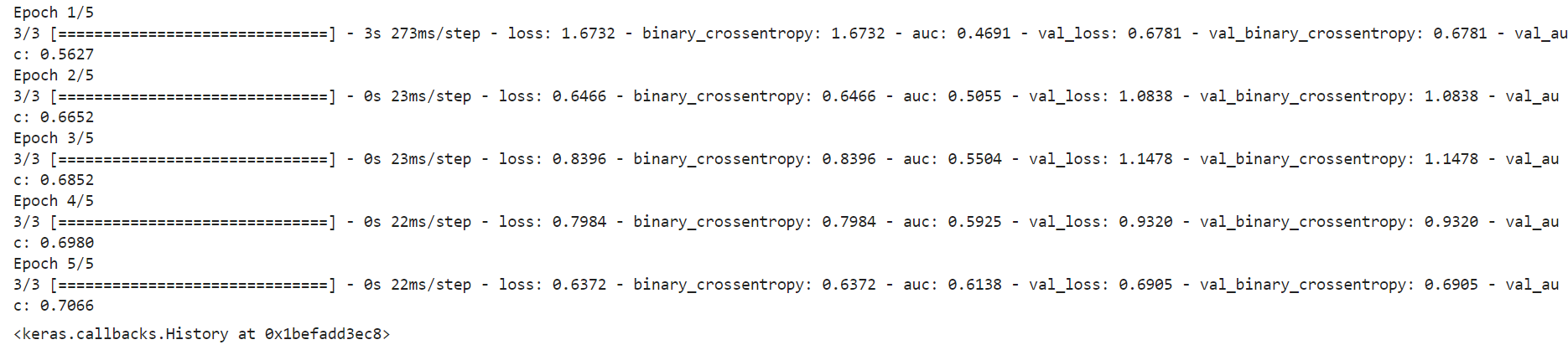
history. compile ( optimizer= 'adam' , loss= 'binary_crossentropy' , metrics= [ 'binary_crossentropy' , tf. keras. metrics. AUC( name= 'auc' ) ] )
train_model_input = { name: data[ name] for name in dense_features + sparse_features}
history. fit( train_model_input, train_data[ 'label' ] . values, batch_size= 64 , epochs= 5 , validation_split= 0.2 )