宁波专业网站建设公司/网络培训平台
InnoDB下的B+Tree数据结构
其特点就是能较好的利用B+Tree,支持范围查找数据的能力。
B+树索引
在数据库中,B+树是高度平衡的,树的高度一般都在2 ~ 4层,所以查某一键值的行记录最多需要2 ~ 4次 IO。B+ 树索引种类分为聚集索引(clustered index)和辅助索引(secondary index)
如何大致计算B+树中的行数与高度?
首先需要知道:
- 在 InnoDB 存储引擎里面,最小的存储单元是页(page),一个页的大小时16KB,即一个B+树节点。页结构可参考《MySQL技术内幕》的4.4。
- 叶子节点存放行数据,非叶子节点存放 索引键值 和 指向数据页的指针
第一层存放的索引个数(即下一层的页数) = (页的大小 - 固定数据结构[约128B]) /( 索引占用空间 + 指针占用空间 )
第二层如果是叶子节点,那么存放的行数据个数 = 第一层索引个数 *( 页大小 / 行数据大小 );
如果是非叶子节点,那么其存放索引个数 = 第一层索引个数 *( 页的大小 /( 索引占用空间 + 指针占用空间 ))
第三层 正常情况下都是叶子节点,其可以存放的行数据 = 第二层索引个数 * (页大小 / 行数据大小 )
当 InnoDB 将出现第四层时,数据行数已经非常大了,应该考虑分表等方案。
聚集索引(clustered index)
聚集索引按照每张表中的主键顺序构建B+树(每张表只能有一个主键,故每张表只能有一个聚集索引),其叶子节点存放完整的行数据,非叶子节点存放键值及指向数据页的偏移量。

聚集索引的存储,是逻辑连续的,叶子节点间通过双向链表互相连接,存储叶子节点的页也是通过双向链表互相连接的。
辅助索引(Secondary Index)
每张表只有一个CI,除了CI的索引,都是SI索引。
SI 不同于 CI,其叶子节点并不是存放的一整行信息,而是存放索引具体的值和一个书签(bookmark),bookmark就是聚集索引中行数据的键。

由图中 SI 与 CI 的关系我们可以知道,当使用 SI 无法获取到需要的数据时,那么将通过 SI 中的 bookmark 去 CI 中继续查找。这便是一个“回表”查询的流程。
索引的管理
可以通过 SHOW INDEX FROM employees;查看表中存在的索引

字段含义:
-
Non_unique:非唯一的索引,可以看到primary key是0,因为必须是唯–的
-
Seq_in_index:索引中该列的位置,如果是联合索引,那么这个值会大于1
-
Collation:列以什么方式存储在索引中。可以是A或NULL。B+树索引总是A,即排序的。如果使用了Heap存储引擎,并且建立了Hash索引,这里就会显示NULL了。因为Hash根据Hash桶存放索引数据,而不是对数据进行排序
-
Cardinality:非常关键的值,表示索引中唯一值的数目的估计值。Cardinality 如果非常小,那么需要考虑是否可以删除此索引
-
Sub_part:是否是列的部分被索引。即前缀索引的长度,如果索引整个列,则该字段为NULL。
-
Packed:关键字如何被压缩。如果没有被压缩,则为NULL
-
Null:索引的列是否含有NULL值
Fast Index Creation(快速引创建)
MySQL 5.5 之前(不包括5.5),对索引的添加/删除之类的 DDL(Data Definition Language) 操作时,需要对旧的表和其中的数据拷贝到新的表中(临时表数据会被存放在全局参数 tmpdir 目录下,需保证有足够的空间,否则 DDL 操作将失败),如果有大量的事务访问正在被修改的表,那么此时的数据库服务将不可用。
InnoDB 从 1.0.x 版本开始支持 FIC 的索引创建方式。对于辅助索引的创建,InnoDB 会对创建索引的表加上一个 S 锁;删除辅助索引时,删除对应的数据即可。
由于 FIC 在索引的创建的过程中对表加上了S锁,若有需要对目标表进行写操作,那么数据库的服务同样不可用。此外,FIC方式只限定于辅助索引,对于主键的创建和删除同样需要重建一张表。
Online DDL
虽然 FIC 提高了辅助索引的创建效率,但在索引创建期间还是会阻塞 DML(data manipulation language) 操作,MySQL 5.6 开始支持 ODDL,可完成如下功能的 在线 操作:
-
辅助索引的创建与删除,且可同时进行 DML 操作
-
改变自增长值
-
添加或删除外键约束
-
列的重命名
并不是全部的 DDL 操作都支持 ODDL 的,例如修改列数据类型、删除主键、变更表字符集等,需要线上 DDL 时,建议先进行测试是否会阻塞 DML。
在 ODDL 方式下,用户可以调整参数,选择索引的创建方式:
ALTER TABLE tbl_name
| ADD {INDEX|KEY) [index name]
[index_type] (index_col_name,...) [index_option] ...
ALGORITHM [=] (DEFAULT|INPLACE|COPY)
LOCK [=] (DEFAULT | NONE | SHARED | EXCLUSIVE)
ALGORITHM指定了创建或删除索引的算法(默认 DEFAULT,等于 INPLACE)
LOCK 部分为索引创建或删除时对表添加锁的情况(默认 DEFAULT )
B+ 树索引的使用与注意事项
联合索引
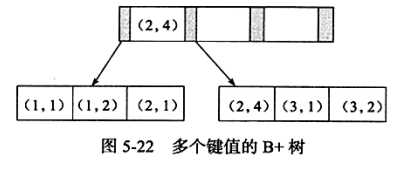
联合索引是指对表上的多个列进行索引。与单列索引不同的是,联合索引 B+ 树中键值的数量 >=2。
联合索引会对多个键值依次进行排序处理(即在每个a下,b是有序的),所以,如果需要使用到联合索引,需要根据这个依次排序的特性去分析查询条件。常见用例如下:
-
联合索引(a, b) 其实是根据列a 、b 进行排序, 因此下列语句可以直接使用联合索引得到结果:
SELECT … FROM TABLE WHERE a=xxx ORDER BY b; -
对于联合索引( a, b , c) 来说, 下列语句也可以直接通过联合索引得到结果:
SELECT … WHERE a=xxx ORDER BY b;
SELECT … WHERE a=xxx AND b=xxx ORDER BY c
但是对于下面的语句, 联合索引不能直接得到结果, 其还需要执行一次 filesort 排序操作, 因为索引(a , c) 并未排序:
SELECT … WHERE a=xxx ORDER BY c
对于下面的语句,可以使用到联合索引,但还使用到了 Using index condition(使用 index 后对数据进行的条件筛查)
SELECT … WHERE a=xxx AND b>xxx AND c=xxx;
覆盖索引(covering index)
covering index 是指从辅助索引中就可以得到查询的数据,而不需要回表查询对应的行数据。
CI 不包含整行数据的所有信息, 故其大小要远小于聚集索引, 数据读取时可以减少磁盘 IO。若查询的SQL内容在CI中均存在,那么将不需要回表查询,也可以减少磁盘IO。
使用 CI 需要注意,CI 需要额外的空间来存储建立的索引。
优化器不使用索引及解决方案
在某些情况下,优化器放弃了可以使用的辅助索引,而是去扫描聚集索引(也就是直接进行全表扫描)来得到数据。这种情况多发生于范围查找、JOIN 链接操作等情况下。
为什么不使用索引?而是去全表扫描?
在某些 SQL 条件中,通过辅助索引不能覆盖到我们要查询的字段信息,因此还需要使用辅助索引中的 bookmark 再做一次回表查询(即覆盖索引失效)。
但借助聚集索引回表查找的 数据是无序的, 因此变为了磁盘上的离散读操作。如果要求访问的数据量很小, 则优化器还是会选择辅助索引, 但是当访问的数据占比较高时( >=20 % 左右), 优化器会 放弃对应的辅助索引,选择聚集索引的顺序读来查找数据(顺序读要远远快于离散读)。
如何解决?
-
优化器之所以放弃辅助索引,使用聚集索引,是根据传统的机械硬盘性质决定的,所以你可以听从优化器的方案
-
如果 DB 的磁盘是固态硬盘,那么离散读操作效率是比较高的,且同时能够确定 使用辅助索引能够提高效率的,可以在 SQL 中使用 force index(index_name) 来指定索引
EXPLAIN SELECT * FROM party_answer force INDEX(idx_abc) WHERE exam_id<72
Memory下的Hash结构
基于哈希表实现,只有精确匹配所有列的查询才有效。MySQL中只有Memory引擎显式的支持哈希索引。
备注:更多的哈希索引内容,可以参考《高性能MySQL》 5.1.1节 146页 的内容。
自适应哈希索引(adaptive hash index)
当InnoDB的某些索引值被经常使用时,该引擎会在内存中基于B+tree索引之上,再建设一个Hash索引,实现快速的哈希查找。不过 AHI 能力是 InnoDB 内部封装的一个能力,使用者不感知。如果业务场景有必要,可以按官网介绍关闭该功能。MySQL AHI参数介绍