pc端网站今日国内重大新闻事件
1、 Java基础入门
a. 什么是计算机
-
名称:Computer,全称电子计算机,俗称电脑。
-
定义:能够按照程序运行,自动、高速处理海量数据的现代化智能电子设备。
-
组成:由硬件和软件组成。
-
形式:常见显示有台式计算机、笔记本计算机、大型计算机等。
-
应用:科学计算、数据处理、自动控制、计算机辅助设计、人工智能、网络等领域。
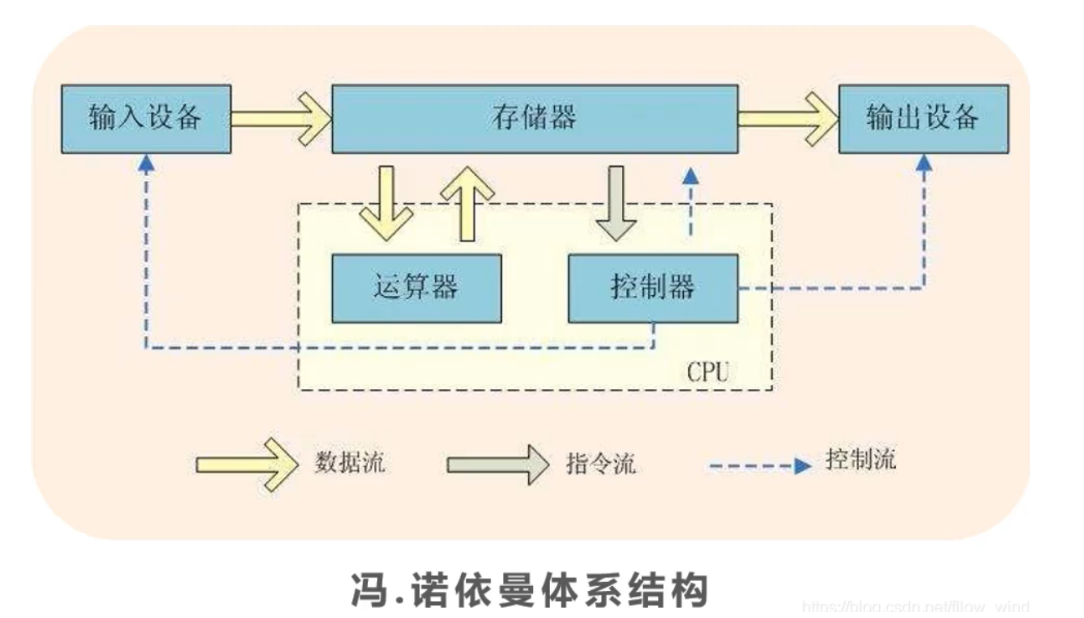
b.硬件及冯诺依曼结构
计算机硬件
组成:CPU,主板,内存,电源,主机箱,硬盘,显卡,键盘、鼠标,显示器。
冯诺依曼结构
c. 软件及软件开发
计算机软件
Windows常用快捷键
Alt+f4关闭窗口 Shift+Delete永久删除 ctrl+w自动保存
死机:任务管理器结束进程
d. 基本的命令
打开cmd的方式
-
开始+系统+命令提示符
-
win键+R+输入cmd (推荐使用)
-
在任意的文件夹下,按住Shift键+鼠标右击,打开命令行窗口
-
在资源管理器地址栏路径前面加 “cmd ”
-
管理员运行方式:命令提示符右键以管理员身份运行(最高权限运行
常用的Dos命令
# 盘符切换 E:
# 查看当前目录下所有文件 dir
# 切换目录 cd /d E:\idea
# 返回上一级目录 cd ..
# 进入同级目录下的下一级目录 cd tmp(该目录下的文件名)
# 清屏 cls (clear screen)
# 退出终端 exit
# 查看电脑当前IP地址 ipconfig# 打开计算器 calc
# 打开画图 mspaint
# 新建记事本 notepad# 在当前目录新建文件夹 md test(文件夹名)
# 新建文件 cd> a.txt(文件名)
# 删除文件 del a.txt(文件名)
# 删除目录 rd test(目录名)# ping命令(复制链接进入Dos直接单击鼠标右键粘贴)ping www.baidu.com
e. 计算机语言的发展史
-
第一代语言:机器语言
-
第二代语言:汇编语言
-
第三代语言:高级语言
f. 高级语言
C、C++、Java、C#、Python、PHP、JavaScript …
大体上分为:面向过程与面向对象两大类
- C语言是典型的面向过程的语言,C++,Java是典型的面向对象的语言
2、Java入门
Java帝国的诞生


Java的特性与优势
-
简单性
-
面向对象
-
可移植性
-
高性能
-
高并发
-
分布式
-
多态性
-
多线程
-
安全性
-
健壮性
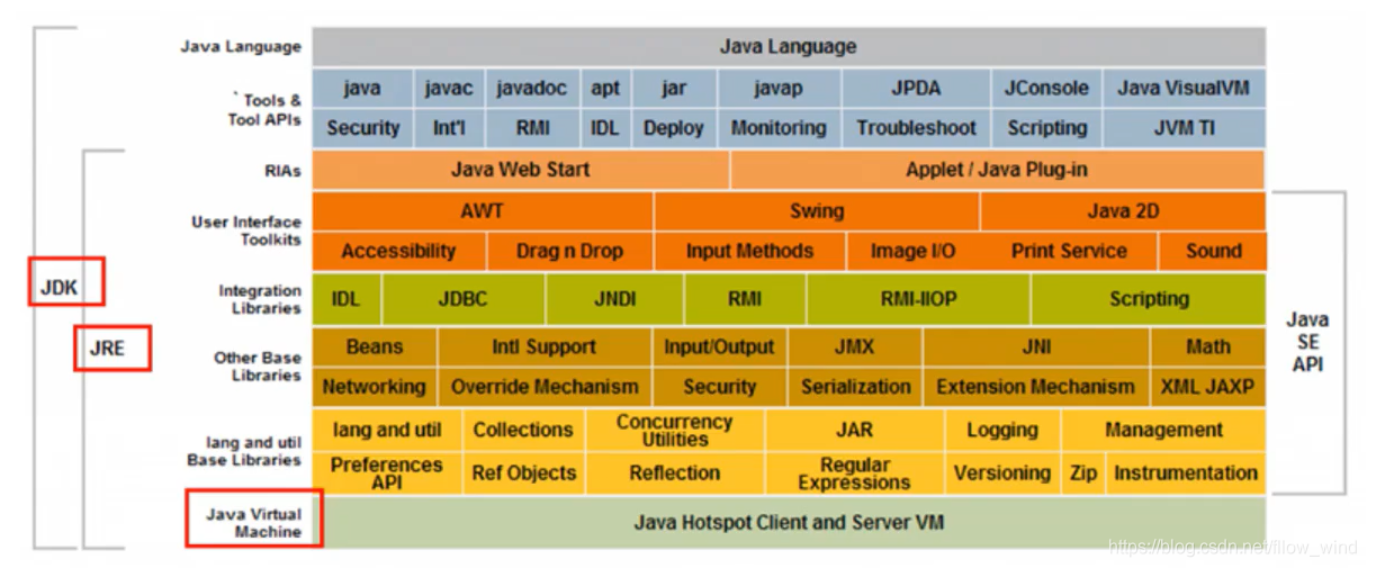
Java三大版本
-
JDK: Java Development Kit (Java开发者工具,包括 JRE,JVM)
-
JRE: Java Runtime Environment (Java运行时环境)
-
JVM: Java Virtual Machine (Java虚拟机,跨平台核心)
- 安装开发环境
1. 卸载JDK
-
删除Java安装目录
-
删除环境变量JAVA_HOME
-
删除path下关于JAVA的目录
-
Java -version
2. 安装JDK
-
百度搜索JDK8,找到下载地址
-
同意协议,下载电脑对应的版本,如64位操作系统下载 jdk-8u281-windows-x64.exe
-
双击安装JDK
-
记住安装路径
-
配置环境变量
-
我的电脑-》属性-》系统高级设置-》环境变量
-
系统变量 新建–> JAVA_HOME 输入对应的jdk安装路径
-
path变量–>% JAVA_HOME%\bin
-
-
测试是否成功 cmd–>Java -version
3、 Java基础
注释
-
单行注释 //
-
多行注释 /* */
-
文档注释 /** */
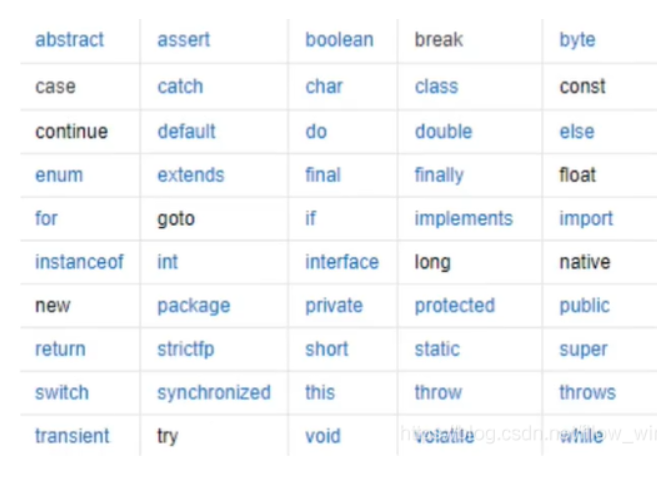
标识符和关键字
- Java 所有的组成部分都需要名字。类名、变量名、方法名都被称为标识符。
标识符注意事项:
-
所有标识符都应该以 字母、$(美元符)、_(下划线) 开头
-
首字母之后可以是 字母、$、_ 或数字任何字符组合
-
关键字不能作为变量名或方法名
-
标识符大小写敏感
-
可以用中文命名,但不建议使用,即使用拼音命名也Low
关键字
数据类型
-
强类型语言
- 要求变量的使用要严格符合规定,所有变量都必须先定义后才能使用
-
弱类型语言:JavaScript,Python
-
Java的数据类型分为两大类
-
基本类型(primitive type),有8大基本类型,此外都是引用类型
-
引用类型(reference type)
-

//整数
int num1 = 10; //最常用,只要别超过21亿(2^31-1)
byte num2 = 20; //-128~127
short num3 = 30;
long num4 = 30L; //long类型数字后面要加个L(尽量用大写,小写l容易与1搞混)
//小数:浮点数
float num5 = 50.1F; //float类型数字后面要加个F
double num6 = 3.141592653589793238;//小数:浮点数
float num5 = 50.1F; //float类型数字后面要加个F
double num6 = 3.141592653589793238;
//布尔值:是非
boolean flag = true
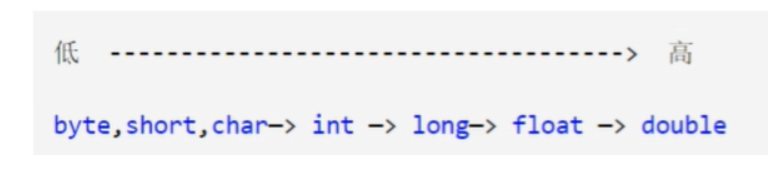
类型转换
-
由于Java是强语言类型,所以在进行运算时需要进行,类型转换。
-
从高到低转换,需要强制转换
-
从低到高转换,可以自动转换。
//强制转换 (类型)变量名 高--低
//自动转换 低--高
int i = 128;
byte b = (byte)i; //强制转换 内存溢出 -128~127
double d =i; //自动转换System.out.println(i); //128
System.out.println(b); //-128
System.out.println(d); //128.0
/*注意点:1.不能对布尔值进行转换2.不能把对象类型转换为不相干的类型3.在把高容器转换到低容量的时候,强制转换4.可能存在内存溢出,或者精度问题* */
System.out.println((int)23.7); //23 丢失精度
char c = 'a';
int n = c+1;
System.out.println(n); //98
System.out.println((char)n); //b//当操作数比较大时,注意溢出问题
//JDK7新特性,数字之间可以用下划线分割
int money = 10_0000_0000; //10亿,下划线不会被打印出来
System.out.println(money); //1000000000
int years = 20;int total = money*years; //数据大,溢出
System.out.println(total); //-1474836480long total2 = money*years; //默认是int,转换前就有溢出问题
System.out.println(total2); //-1474836480long total3 = money*(long)years; //先把一个数转Long
System.out.println(total3); //20000000000变量 常量 作用域
-
变量是什么:就是可以变化的量
-
Java是一种强类型语言,每个变量都需要声明其类型。
-
Java变量是程序中最基本的存储单元,要素包括变量名,变量类型和作用域。
//数据类型 变量名 = 值;
type varName [=value][{,varName[=value]}];
//可以使用逗号隔开同多个类型的变量,但不建议在一行定义多个变量变量作用域
-
类变量(static)
-
实例变量
-
局部变量
public class Variable{ static int allClicks = 0; //类变量 String str = "hello world"; //实例变量 public void method(){ int i=0; //局部变量 }}常量
-
常量:初始化不能再改变的量,不会变动的值。
-
可以理解为一种特殊的变量,其值被设定后,在程序运行过程中不允许被改变。
//常量一般用大写字符final 常量名=值;final double PI=3.14;//修饰符 不存在先后顺序,static可以写final后面static final doube PI=3.14; //类变量,该类下的全局范围
变量的命名规范
-
所有的变量,方法,类名:见名知意。
-
类成员变量:首字母小写+驼峰原则 :lastName
-
局部变量:首字母小写+驼峰原则
-
常量:大写字母和下划线:MAX_VALUE
-
类名:首字母大写 +驼峰原则 :Man GoodMan
-
方法名:首字母小写 +驼峰原则 :run(),fastRun()
运算符

int a=10;int b=20;System.out.println(a/b); //0System.out.println((double)a/b); //0.5long c=12300000000;System.out.println(a+b); //intSystem.out.println(a+c); //long 自动转换式子中容量大的数据类型自增自减运算符
// ++自增 --自减 单目运算符int a = 3;int b = a++; //b=a,a=a+1 先赋值 即b=3 a=4int c = ++a; //a=a+1,c=a 先自增 即a=5 c=5System.out.println(a); //5System.out.println(b); //3System.out.println(c); //5//幂运算 2^3 2*2*2=8double pow = Math.pow(2,3); // (底数,指数)double型System.out.println(pow); //8.0//扩展:笔试题 i=5 s=(i++)+(++i)+(i--)+(--i) s=?int i=5;int s=(i++)+(++i)+(i--)+(--i);System.out.println(s); //24逻辑运算符
-
&& 逻辑与运算:两个变量都为真,结果为true
-
|| 逻辑与运算:两个变量有一个为真,结果为true
-
! 取反,真变为假,假变为真
// 与(snd) 或(or) 非(取反)
boolean a = true;
boolean b = false;System.out.println(a&&b); // false
System.out.println(a||b); // true
System.out.println(!(a&&b)); // trueint c=5;
boolean d = (c<5)&&(c++<5); //第一个值为false,后面就不进行判定了
System.out.println(d); //false
System.out.println(c); //5 c++未执行位运算
/*A = 0011 1100B = 0000 1101A&B 0000 1101 按位与A|B 0011 1101 按位或A^B 0011 0001 异或~B 1111 0010 非面试题:2*8 怎么算最快? 2<<3<<左移 *2 效率极高!!>>右移 /2*/
System.out.println(2<<3); // 16三元运算
int a = 10;int b = 20;a+=b; // a = a+ba-=b; // a = a-bSystem.out.println(a); //10//字符串连接符 + ,转化为String类型,然后拼接 注意!!System.out.println(""+a+b); //1020System.out.println(a+b+""); //30 先进行运算,再转为String拼接System.out.println(a+b+"str"); //30str// x ? y : z//如果x为真,则结果为y,否则为z//if(x) y; else z;int score = 80;String type = score<60?"及格":"不及格";System.out.println(type); //及格包机制
-
为更好的组织类,Java提供包机制,由于区分类名的命名空间。
-
包的语法机制:
package pkg1[.pkg2[.pkg3...]];-
一般利用公司域名作为包名:com.manmanstudy.www
-
为了能够使用一个包的成员,需要在Java程序中导入该包。
import package1[.package2...].(className|*); //通配符* 导入包下所有的类- 参考:阿里巴巴Java开发手册。
javaDoc生成文档
-
javadoc命令是用来生成自己的API文档的
-
参数信息
-
@author 作者名
-
@version 版本号
-
@since 指明最早用的jdk版本
-
@param 参数名
-
@return 返回值情况
-
@throws 异常抛出情况
点击跳转API文档
点击跳转百度
点击跳转CSDN社区
-
/*** @author Kuangshen* @version 1.0* @since 1.8*/
public class Demo05 {String name;/*** @author kuangshen* @param name* @return* @throws Exception*/public String test(String name) throws Exception{return name;}}-
打开某个类所在文件夹下的cmd命令行
-
输入:javadoc -encoding UTF-8 -charset UTF-8 Doc(类名).java
-
会自动生成该类有关的API文档,查看文件夹发现多了一些文件
-
打开 index.html(首页)查看文档注释
4、Java流程控制
- 用户交互Scanner
Scanner对象
-
之前我们学的基本语法并没有实现程序和人的交互,Java给我们提供了一个工具类,可以获取用户的输入java.util.Scanner是Java5的新特征,我们通过Scanner类来获取用户的输入。
-
基本语法
Scanner s = new Scanner(System.in); -
通过Scanner类的 next()与 nextLine()方法获取用户的字符串,读取前一般用hasNext()与hasNextLine()判断是否还有输入的数据。
//创建一个扫描器对象 Scanner scanner = new Scanner(System.in);System.out.println("使用next方式接收"); //判断用户有没有输入字符串 if(scanner.hasNext()){ //使用hasNextLie()会接收一行 "hello word"//使用next方式接收String str = scanner.next(); System.out.println("输入的内容为:"+str);//input: hello word//输入的内容为:hello } //凡是属于IO流的类如果不关闭会一直占用资源 scanner.close();next():
-
一定要读取到有效字符后结束输入
-
对输入有效字符之前遇到的空白,next()方法会自动将其去掉
-
只有输入有效字符后才能将后面输入的空白作为分隔符或者结束符
-
next()不能得到带有空格的字符串
-
Scanner scanner=new Scanner(System.in);
System.out.println("你输入的是:");
String str=scanner.nextLine();
System.out.println("输出:"+str);
scanner.close();nextLine():
-
以enter为结束符,也就是说nextLine()方法返回的是输入回车之前的所有字符
-
可以获得空白
Scanner scanner=new Scanner(System.in); int i=0; System.out.println("请输入整数:"); if (scanner.hasNextInt()){i = scanner.nextInt();System.out.println("你输入的没错:" + i); }else{System.out.println("请输入整数"); }Scanner sanner=new Scanner(System.in); float a=0.0f; System.out.println("请输入小数:"); if (scanner.hasNextFloat()){a = scanner.nextFloat();System.out.println("你输入的是小数没错:" + a); }else{System.out.println("请输入小数"); } scanner.claose();例题:我们可以输入多个数字,并求其总和和平均数,每输入一个数字回车确认,通过输入非数字来结束输入并输出执行结果
Scanner scanner=new Scanner(System.in);
float f=0.0f;
float sum=0.0f;
float avg=0.0f;
System.out.println("请输入多个数字:");
while (scanner.hasNextFloat()){f=scanner.nextFloat();sum=sum+f;avg++;System.out.println("你输入了第"+avg+"数字");
}
System.out.println("一共有"+avg+"个数字,"+"和为"+sum+",平均数为:"+sum/avg);
scanner.close();switch 选择结构
多选择结构还有一个实现方式就是switch case语句
switch语句中的变量类型可以是:
-
byte、short、int或者char
-
从Java SE7开始
-
switch支持字符串String类型了
-
同时case标签必须为字符串常量或字面量
char grade='C';switch (grade){case 'A':System.out.println("优秀");break;case 'B':System.out.println("良好");break;case 'C':System.out.println("及格");break;case 'D':System.out.println("再接再厉");break;default:System.out.println("未知等级");}switch可以支持字符串
String str="world";switch (str){case "hello":System.out.println("你好");break;case "world":System.out.println("世界");break;default:System.out.println("java");break;}- 循环结构
-
while循环
//计算1+2+3+...+100 int i=0; int sum=0; while(i<100){i++;sum+=i; } System.out.println(sum); //5050
-
-
do …while循环
//先执行后判断,至少执行一次 do{i++;sum+=i; }while(i<100) //跟上面效果一样```-
for循环
//(初始化;条件判断;迭代) for(int i=0;i<100;i++){i++;sum+=i; } for(; ; ){...} //死循环 -
九九乘法表
for (int i=1;i<=9;i++){for (int j=1;j<=i;j++){System.out.print(i+"*"+j+"="+(i*j)+"\t");}System.out.println();} -
输出1-1000能被5整除的数,每行输出3个
//练习:输出1-1000能被5整除的数,每行输出3个 for (int i = 1; i <= 1000; i++) { if(i%5==0){ System.out.print(i+"\t"); //输出完不换行 } if(i%(3*5)==0){ //每当第三个数字可以被15整除的时候就可以换行了System.out.println(); //或者 System.out.print(“\n”);//println :输出完会换行//print :输出完不会换行}} -
死循环
//(初始化;条件判断;迭代) for(int i=0;i<100;i++){ i++; //自增sum+=i; }for(; ; ){...} //死循环 -
break & continue
-
break可以用在任何循环体的主体部分,用于强行退出循环,也可以用在swich语句中。
-
continue用于循环语句中,用于终止某次循环,跳过剩余语句,之后进行下一次循环条件的判断。
-
标签:后米跟着一个冒号的标识符:label
-
-
增强for循环
int []num={10,12,45,31,2,12}; for (int i=0;i<6;i++){ System.out.println(num[i]); } System.out.println("==================="); for (int x: num){ System.out.println(x); } 增强for循环可以进行简写,简单方法:如果要循环5次,可以“5.for”就可以在idea中使用
-
增强for循环可以进行简写,简单方法:如果要循环5次,可以“5.for”就可以在idea中使用
-
打印等腰三角形
public static void main(String[] args) {for (int i = 0; i <= 6; i++) {for (int j = 6; j > i; j--) { // 打印倒三角形 i负责行数 此时j=6(最大) j>i ; j-- 负责输出 “*”System.out.print(" ");//使用空白方式 打印出一个倒三角形} // 将之后的三角形分成两个三角形,然后分别打印for (int j = 0; j <=i; j++) {System.out.print("*"); // 这是最左边的三角形 j <=i i始终负责行数}for (int j = 0; j <i ; j++) {System.out.print("*"); // 这是打印最右边的三角形 此时 j < i ,因为要将一个三角形平分 ,左右不能不一样, // 所以此时不能平分 ,左边的三角形 j<=i 先把三角形的定点打印出来。}System.out.println();}}- Java方法详解
Java方法是语句的集合 ,他们在一起执行一个功能。
-
方法是解决一类问题的步骤的有序集合。
-
方法包含于类或者对象中。
-
方法在程序中被创建,在其他地方被引用。
-
设计方法的原则:方法的本意是代码块,就是实现某个功能的语句块。我们设计方法的时候,最好保持方法的原子行,就是一个方法只完成1个功能,这样利于我们后期的扩展。
方法的定义
Java的方法类似于其他语言的函数,是一段用来完成特定功能的代码片段,一般情况下,定义一个方法,包涵以下语法:
-
方法包含一个方法跟方法体。下面是一个方法的所有部分。
-
修饰符:修饰符,这是可选的告诉编译器如何来调用该方法,定义了该方法的询问类型,
-
返回值类型:方法可能会返回值,returnValueType是返回值的数据类型,有些方法执行所需的操作,但没有返回值,在这种情况下,returnValueType是关键字void
-
方法名:是方法的实际名称,方法名和参数共同构成方法签名。
-
参数类型像是一个占位符,当方法被调用时,传递值给参数,这个值被称为实参或变量,参数列表是指方法的参数类型 顺序和参数的个数,参数是可选的,方法可以不包含任何参数。
-
//main方法public static void main(String[] args) {//实际参数:实际调用传递给他的参数int sum=add(5,5);System.out.println(sum);}//加法//形式参数,用来定义作用的public static int add(int a,int b){return a+b;}- 方法体:方法体包含具体的语句定义该方法的功能
修饰符 返回值类型(void不返回) 方法名(参数类型 参数名){···方法体···return 返回值;
}Java是进行值传递的。
方法的重载
-
重载就是在一个类中,有相同的函数名称,但形参不同的函数。
-
方法的重载的规则:
-
方法名必须相同
-
参数列表必须不同(个数不同,类型不同或者参数的排列顺序不同)
-
方法的返回值类型必须相同
-
仅仅返回值类型不同不足以构成方法的重载
-
-
实现理论:
- 方法名称相同的时候 编译器会调用方法的参数个数,参数类型去逐一匹配,以选择对应的方法,如果匹配失败,则编译器报错,编译失败。
命令行传参
-
有时候希望运行一个程序时再传递给它消息。这要靠传递命令行参数给main()函数实现
public static void main(String[] args) { //args.length 数组长度 for (int i = 0; i < args.length; i++) { System.out.println("args["+i+"]: "+args[i]); } }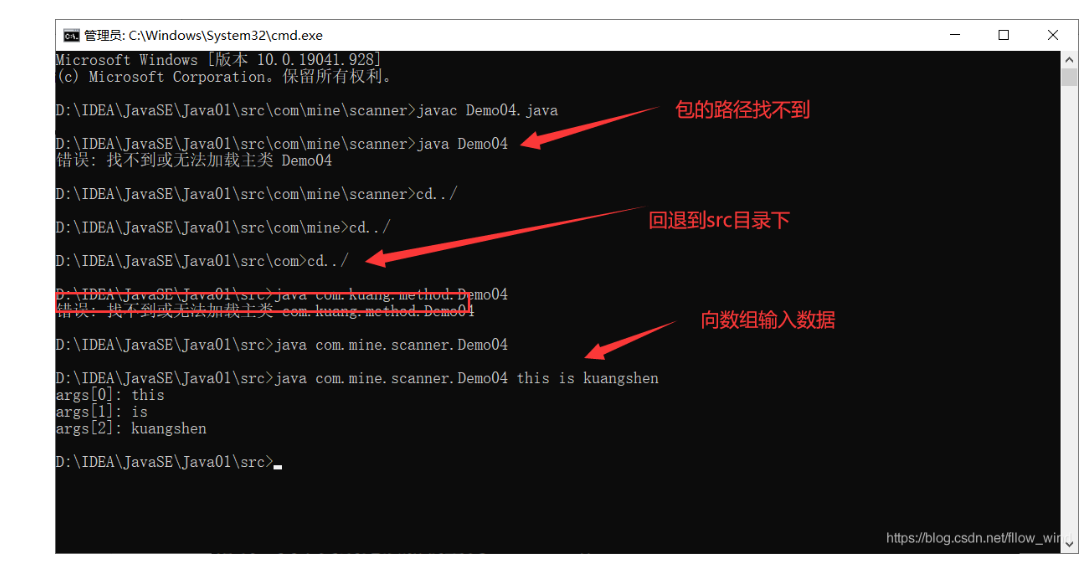
可变参数
-
Jdk1.5开始,Java支持传递同类型的可变参数给一个方法。
-
在方法声明中,在指定参数类型后加一个省略号 (…)。
-
一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。
public static void main(String[] args) {//调用可变参数的方法printmax(34,45,456,4,6545,44,54,4,54);printmax(new double[]{1,2,3});}public static void printmax(double ...numbers){if (numbers.length==0){System.out.println("No argument passed");return;}double result=numbers[0];//找最大值for (int i=1;i<numbers.length;i++){if (numbers[i]>result){result=numbers[i];}}System.out.println("The max value is "+result);}计算器的实现
public static void main(String[] args) {Scanner scanner=new Scanner(System.in);System.out.println("请输入第一个数值:");while (scanner.hasNextDouble()){double a=scanner.nextDouble();System.out.println("请输入操作符");String str=scanner.next();System.out.println("请输入第二个数值:");double b=scanner.nextDouble();switch (str){case "+":add(a,b);break;case "-":mius(a,b);break;case "*":multiply(a,b);break;case "/":except(a,b);break;default:System.out.println("输入的运算符错误");break;}}}public static void add(double num1,double num2){System.out.println(num1+num2);}public static void mius(double num1,double num2){System.out.println(num1-num2);}public static void multiply(double num1,double num2){System.out.println(num1*num2);}public static void except(double num1,double num2){if (num2==0){System.out.println("分母不能为0");}else{System.out.println(num1/num2);}}5、 数组与方法
Java中的数组
数组的简单实现
- 首先必须声明数组变量,才能在程序中使用数组。下面是声明数组变量的语法:
datatype [] arrayRefVar;int [] num1;
-
Java语言使用new操作符来创建数组,语法如下:
datatype [] arrayRevVar=new dataType[arraySize]; -
数组的元素是通过索引访问的,数组索引从0开始
-
获取数组长度:array.length
//变量的类型 变量的名字=变量的值; //数组类型 public static void main(String[] args) { int [] nums;//1.声明一个数组 nums=new int[10];//2.创建一个数组 int [] nums2=new int[10];//声明和创建可以放在一起 //3.给数组元素赋值 nums[0]=1; nums[1]=2; nums[2]=3; nums[3]=4; nums[4]=5; nums[5]=6; nums[6]=7; nums[7]=8; nums[8]=9; nums[9]=10; //计算所有元素的和 int sum=0; for (int i = 0; i < nums.length; i++) { sum+= nums[i]; } System.out.println(sum); }
数组的初始化
//静态初始化:创建+赋值
int [] a={4,1,2,3,5,4,6,4};
System.out.println(a[0]);
//动态初始化
int [] b=new int[10];
b[0]=10;
System.out.println(b[0]);数组的基本特点与注意事项
-
其长度是确定的,数组一旦被创建,其长度就无法改变。
-
其元素一定是相同类型,不允许出现混合类型。
-
数组中的元素可以是任何类型,包括基本数据类型和引用类型。
-
数组变量引用类型,数组也可以看成对象,数组中的每个元素都相当于对象的成员变量。数组本身就是对象,java对象是存在堆中的,因此数组无论原始类型还是其他对象类型,数组对象本身在堆中。
-
Java语言中的数组是一种引用类的数据类型。不属于基本数据类型。数组的父类是Object。
-
数组实际上是容器,可以同时容纳多个元素。(数组是一个数据的集合。)
1. 数组:字面意思:一组对象
-
数组当中可以存储“基本数据类型”的数据,也可以存储“引用数据类型”的数据。
-
数组因为是引用类型,所以数组对象是堆内存当中。(数组是储存在堆当中)。
-
对于数组当中如果存储的是“java对象”的话,实际上存储的是对象的“引用(内存地址)“。
-
数组一旦创建,在java中规定,长度不可变。(数组长度不可变)。
-
数组的分类:一维数组,二维数组,三维数组,多维数组……(一维数组较多,二维数组偶尔使用)。
-
所有数组对象都有length属性(java自带的),用来获取数组中元素的个数。
-
java中的数组要求数组元素的类型统一。比如,int 类型数组只能存储int同类型,Person类型数组只能存储person数组。
1. 数组中存储的元素类型统一
-
数组中在内存方面存储的时候,数组中的元素内存地址(存储的每一个元素都是有规则的排列着)是连续的。内存地址连续。
1. 这是数组存储元素的特点。
-
数组的内地址就是一个元素的内存地址。(数组中首元素的内存地址作为整个数组对象的内存地址)。
-
数组中每个元素都是有下标的,下标都是从0开始以1递增。最后一个元素的下标是length-1.下标非常重要因为我们对数组元素进行“存取"的时候,都需要通过下标来进行。
-
数组这种数据结构的优点和缺点是什么?
1. 优点:查询/查找/检索某个下标上的元素时效率最高。可以说是查询最高的一个数据结构。
2. 为什么效率最高?3.1. 每个元素的内存地址在空间上的存储是连续的。2. 每一个元素类型相同,所以占用的空间大小是一样的。3. 知道一个元素的内存地址,知道每一个元素占用空间的大小,有知道元素的下标,所以通过一个数学表达式级就可以计算出某个下标上的元素的内存地址。直接通过内存地址定位元素,所以检索的效率是最高的。4.1. 数组中存储100个元素或者存储一百万个元素,在元素查询/检索方面,效率是相同的。2. 因为数组中的元素查找不会一个一个的查询,是通过数学表达式计算出来的。(算出一个内内存地址,剩下的直接定位就可以了)4. 缺点:5.1. 由于为了保证数组中的每个元素的内存地址连续,所以在数组上连续随机删除或者增加元素的时候,效率较低,因为随机删除会涉及到后面元素统一向前或统一向后。6.1. 数组不能存储大元素,为什么?2.1. 因为很难在存储空间上找到特别大的一块连续的内存空间2.
数组的使用
-
普通的for循环
int [] arrays={1,2,3,45,5}; int sum=0; for (int i=0;i< arrays.length;i++){ sum+=arrays[i]; System.out.println(arrays[i]); } -
for—Each循环(增强for循环)
int [] arrays={1,2,3,45,5}; for (int ayyays:arrays){ System.out.println(ayyays); } -
数组做方法入参(void作为方法入参,可以没有返回值)
int [] arrays={1,2,3,45,5};printArray(arrays); //打印数组元素 public static void printArray(int[] arrays){ for (int i=0;i< arrays.length;i++){ System.out.print(arrays[i]+" "); } } -
数组作为返回值(反转数组)
int [] arrays={1,2,3,45,5};int [] reverse= reverse(arrays);for (int i=0;i< reverse.length;i++){ System.out.println(reverse[i]); } //反转数组 public static int[] reverse(int [] arrays){ int [] result=new int[arrays.length]; //反转操作 for (int i=0,j= result.length-1;i< arrays.length;i++,j--){ result[j]=arrays[i]; } return result; }
二维数组
关于java中的二维数组
1.二位数组其实是一个特殊的一维数组,特殊在这个一维数组当中的每一个元素都是一个一维数组
2.三维数组是什么?
三维数组是一个特殊的二维数组,特殊在这个二维数组当中的每一个元素都是一维数组
实际的开发中使用最多的就是一维数组.二位数组很少使用,三维数组几乎不用.
-
二维数组的遍历
int [] [] array={{3,4},{5,6},{6,7}}; // System.out.println(array[1][1]); //遍历二维数组的长度 for (int i=0;i< array.length;i++){ for (int j=0;j<array[i].length;j++){ System.out.println(array[i][j]); } }
Arrays类
-
数组的工具类是java.utill,Arrays
-
由于数据对象本身并没有方法可以供我们使用,但是API提供了一个工具类Arrays供我们使用
-
Array类中的方法都是static修饰的静态方法,使用时直接使用类名进行调用,可以不用对象调用
-
常用功能
-
给数组赋值:fill方法
-
排序:sort方法,升序
-
比较数组:equals方法比较数组中元素值是否相等
-
查找数组元素:binarySearch对排序号的数组进行二分法查找操作
int [] array={3,5,4,6,3,1,2,0,5,9,8,7}; //填充数组 Arrays.fill(array,2,4,0); //打印数组 System.out.println(Arrays.toString(array)); //排序数组 Arrays.sort(array); System.out.println(Arrays.toString(array)); //二分查找 返回的是值的下标 System.out.println(Arrays.binarySearch(array,0));
-
冒泡排序
-
冒泡排序是八大排序最出名的排序算法。
-
代码:两层循环,外层冒泡轮数,里层依次比较。
-
当我们看到嵌套循环,应该立马就可以得出这个算法的时间复杂度为O(n2)。
稀疏数组

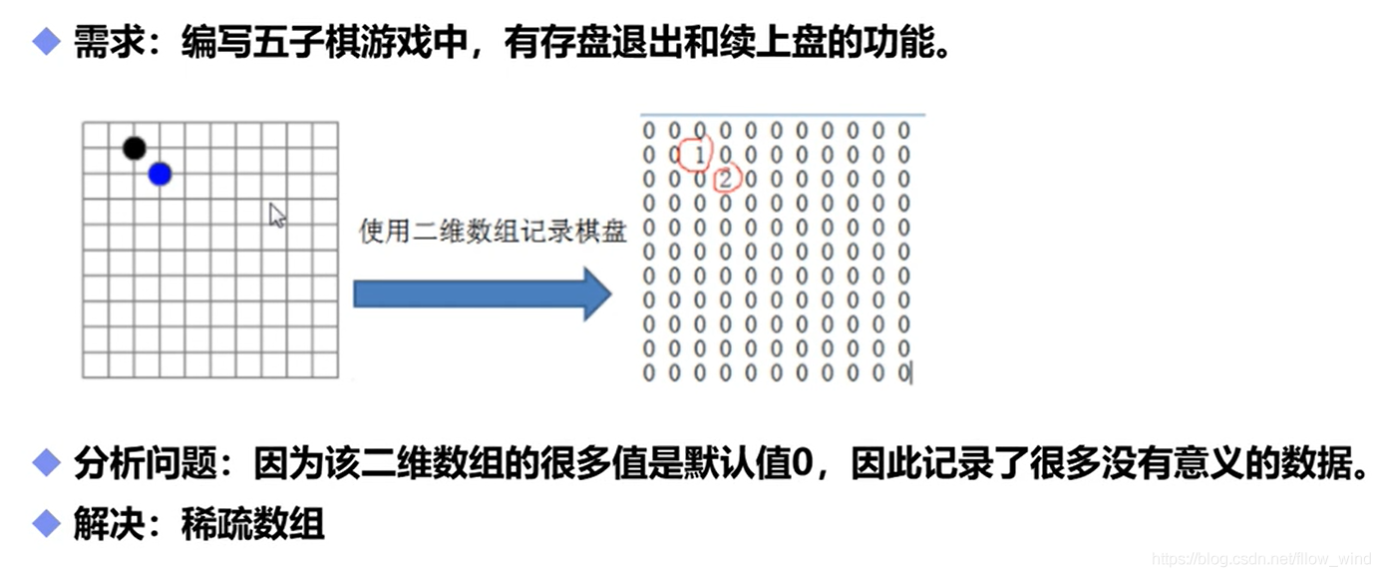
//创建一个二维数组 11*11 0:没有妻子 1:黑子 2:白字public static void main(String[] args) {int[][] array = new int[11][11];array[1][2] = 1;array[2][3] = 2;System.out.println("输出原始的数组");for (int[] ints : array) {for (int anInt : ints) {System.out.print(anInt + "\t");}System.out.println();}//转换为稀疏数组保存//1.获取有效值的个数int sum = 0;for (int i = 0; i < 11; i++) {for (int j = 0; j < 11; j++) {if (array[i][j] != 0) {sum++;}}}System.out.println("=================");System.out.println("有效值的个数 " + sum);//2.创建一个稀疏数组的数组int[][] array2 = new int[sum + 1][3];array2[0][0] = 11;array2[0][1] = 11;array2[0][2] = sum;//3.遍历二维数组,将非零的值,存放在稀疏数组中int count = 0;for (int i = 0; i < array.length; i++) {for (int j = 0; j < array[i].length; j++) {if (array[i][j] != 0) {count++;array2[count][0] = i;array2[count][1] = j;array2[count][2] = array[i][j];}}}//4.输出稀疏数组System.out.println("稀疏数组");for (int i = 0; i < array2.length; i++) {System.out.println(array2[i][0] + "\t"+ array2[i][1] + "\t"+ array2[i][2] + "\t");}System.out.println("==============");System.out.println("还原");//1.读取稀疏数组int [][]array3=new int[array2[0][0]][array2[0][1]];//2.给其中的元素还原他的值for (int i=1;i< array2.length;i++){//注意从1开始,0是头部信息array3[array2[i][0]][array2[i][1]]=array2[i][2];}//3.打印System.out.println("输出还原的数组");for (int [] ints:array3){for (int anInt:ints){System.out.print(anInt+"\t");}System.out.println();}}
Java中的方法
语法格式:
修饰符 返回值类型 **方法名(参数列表)*{
方法体语句;(Java语句)
}
说明:修饰符:public,private,protected等。
返回值类型:return语句传递返回值,void语句没有返回值。
return是用来终止方法的
方法的调用
-
注意:
-
没有具体返回值的情况,返回值类型用关键字void表示,那么该函数中的return语句如果在最后一行,可以省略不写。
-
定义方法时,方法的结果应该返回给调用者,交由调用者处理。
-
**方法中只能调用方法,不可以在方法内部定义方法。**在Java语言中 ,方法要生效 就必须要调用!
方法名
- 方法名要见名知意。(使用小驼峰命名)
- 方法名在标识符命名规范当中,要求首字母小写,其他区字母大写。
- 只要合法的标识符就可以。
形式参数列表
-
简称 :形参
-
注意 :形式参数列表中的每一个参数,都是局部变量,方法结束后内存会释放。
形参的个数是 :0~N个
public static void sumInt(){} public static void sumInt(int x,int y){} public static void sumInt(int x){} public static void sumInt(double x,double y,String s){}- 形参有多个的话,要用”逗号隔开“,必须是英文状态下的逗号。
- 形参的数据类型起决定性作用,形参对应的变量名是随意的。
方法体
- 由Java语句构成的,Java语句是由“ ;”构成的。
- 方法体中的编写的是业务逻辑代码,是要完成某种特定的功能的。
- 在方法体中的代码遵循自上而下依次进行。
- 在方法体中处理业务逻辑代码时需要处理数据,这些数据就是来源于形参的。
**注意:**main方法结束后 ,不会给JVM任何值。
方法定义之后的调用
public class Demo01 {//主方法 入口public static void main(String[] args) {
// 程序自上而下的执行sumInt(22,89);sumInt(223,8549);sumInt(2,4);}/*** 1. 专门在这个类体中定义方法 完成某种特定的功能.* 2. 局部变量特点 :每一个方法结束后,局部变量占用的内存都会释放掉。*/public static void sumInt(int a,int b) {int z =a +b;System.out.println(a + "+" + b + "=" + z );}
}
计算两个int 类型数据的和
public class Demo02 {public static void main(String[] args){int i = Demo02.sumInt(6,89);int c = Demo02.sumInt(9,1);System.out.println(i);System.out.println(c);}public static int sumInt(int a ,int b){return a+b;}
}break语句与return语句的区别
- break :用来终止Switch和理他最近的循环。
- return : 用来终止理他最近的方法。
- return语句后买能不能有代码。
- 两者没有关系 ,并且差别很大。
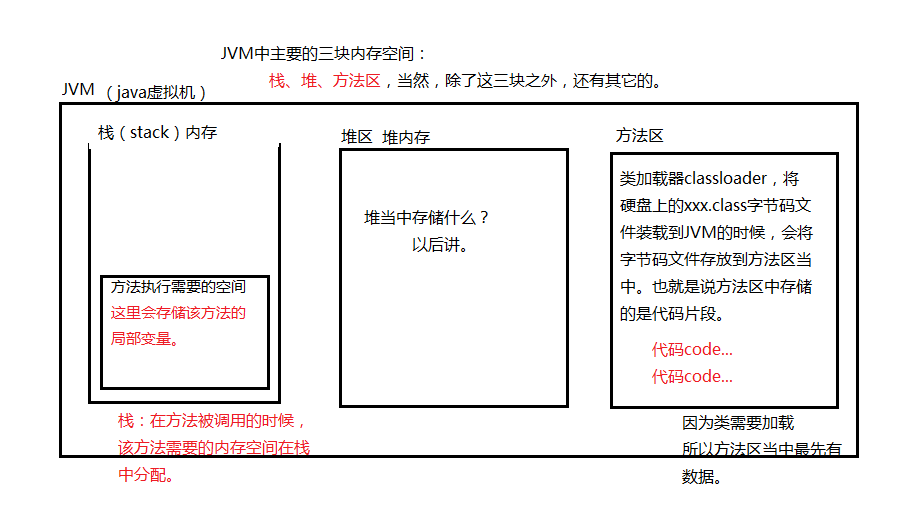
JVM的内存结构
栈数据结构
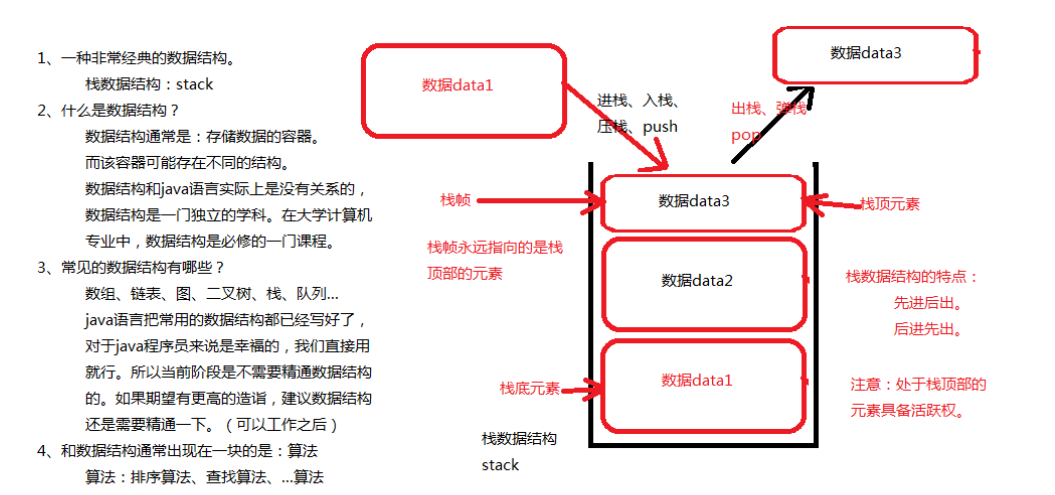
数据结构的定义:
数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的学科。
基本概念与术语:
数据
何为数据:它是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。这里的数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。
数据元素
何为数据元素:是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理。也被称为记录。
数据项
何为数据项:一个数据元素可以由若干个数据项组成。
数据项是数据不可分割的最小单位。
数据对象
何为数据对象:是性质相同的数据元素的集合,是数据的子集。
性质相同是指,数据元素具有相同数量和类型的数据项。
通常情况下,将数据对象简称为数据。
数据,数据元素,数据项,数据对象之间的关系见下图:

数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
方法执行时内存变化
public static void main(String[] args){// main方法,这是入口Syetem.out.println("main begin");int x =1;m1(x);Syetem.out.println("main over");
}
public static void m1(int i ){//i是局部变量Syetem.out.println("main begin");m2(i);Syetem.out.println("main over");
}
public static void m2(int i){Syetem.out.println("main begin");m3(i);Syetem.out.println("main over");
}public static void m3(int i){Syetem.out.println("main begin");System.out.println(i);yetem.out.println("main over");}
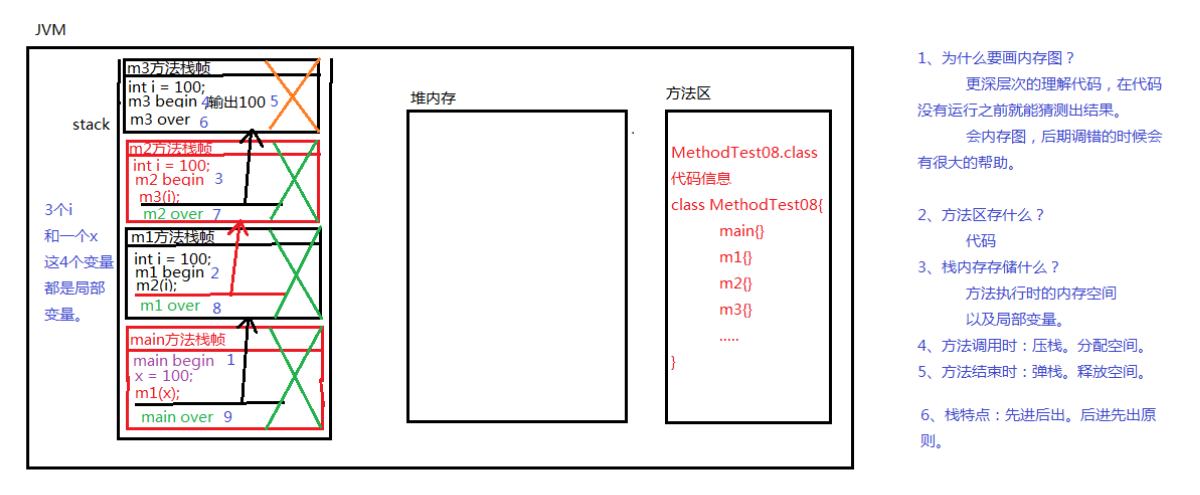
- 局部变量 :只有在方法体中有效,方法结束之后,局部变量的内存就会释放。
- JVM最主要的三块内存 :栈 , 堆内存 , 方法区。
- 方法区最先有数据 :方法区放代码片段 ,存放class字节码文件。
- 栈内存 :方法调用的时候,该方法需要的内存会在栈空间进行分配。
- 方法只有在调用的时候才会在栈内存中分配空间,此时发生压栈动作。
- 方法执行结束之后,该方法所分配的空间就会被释放,此时发生弹栈动作。
方法的重载
什么是方法重载呢?
方法重载(overload)是指在一个类中定义多个同名的方法,但要求每个方法具有不同的参数的类型或参数的个数。调用重载方法时,Java编译器能通过检查调用的方法的参数类型和个数选择一个恰当的方法。方法重载通常用于创建完成一组任务相似但参数的类型或参数的个数不同的方法。调用方法时通过传递给它们的不同个数和类型的实参来决定具体使用哪个方法。 什么情况下我们考虑使用方法重载呢?在同一个类当中,如果多个功能是相似的,可以考虑将它们的方法名定义的一致,使用方法重载机制,这样便于程序员的调用,以及代码美观,但相反,如果两个方法所完成的功能完全不同,那么方法名也一定要不一样,这样才是合理的。
在Java语言中,是怎么进行方法的区分?
- 首先Java编译器会进行区分。
- 但是在Java语言中允许方法名相同的情况存在。
- 如果方法名相同,编译器会根据形式参数列表进行区分。
什么时候考虑方法重载?
在同一类中,如果功能1跟功能2的功能是相似的,那么可以考虑他们的方法名一致,这样写起来代码更美观,有便于后期代码的编写。(容易记忆,方便使用)
注意 :方法重载(overload)不能随便使用,如果两个功能不相关 ,不相似,根本没有关系,此时将两个方法使用重载机制的话,会导致代码更麻烦。
代码满足什么条件的时候构成方法重载呢?
满足以下三个条件:
- 在同一个类当中。
- 方法名相同。
- 参数列表不同:个数不同算不同,顺序不同算不同,类型不同也算不同。
注意:方法的重载与方法的返回值类型以及修饰符列表无关
方法递归
方法递归的理解
-
方法自己调用自己,这就是方法递归。
-
当递归时程序没有结束条件时,一定会发生栈内存溢出错误:StackoverflowError。
-
所以递归一定要有结束条件。
eg:
public class Deemo{//程序入口public static void main(String[] args){doSome();}public static void doSome(){System.out.println("doSome begin!!");//这里自己调用自己 :方法递归doSome();System.out.println("doSome over!!");}System.out.println("doSome begin!!");//这里自己调用自己 :方法递归doSome();System.out.println("doSome over!!");}System.out.println("doSome begin!!");//这里自己调用自己 :方法递归doSome();System.out.println("doSome over!!");} System.out.println("doSome begin!!");//这里自己调用自己 :方法递归doSome();System.out.println("doSome over!!");} }
注意: 在实际的开发过程中,不建议轻易选择递归,能用for循环while循环代替的,尽量使用循环代替。因为循环的效率高,耗费的内存小。而递归耗费的内存大,另外递归的使用不当,会导致JVM死掉。(但在极少数的情况下,不适用递归程序可能无法使用)。JVM发生错误只有一个结果 :就是会退出JVM。
在实际开发过程中 ,如果遇到了StackoverflowError这个错误,有什么解决方案嘛?
解决思路:
- 首先第一步 :先检查递归条件是否正确,如果递归条件不对,则必须对递归条件进一步修改,知道正确为止。
- 第二步 :假设递归条件没有问题,这个时候需要手动调整JVM的栈内存初始化大小。可以将栈内存的空间调大一些。
- 调整了大小,如果运行时还是出现错误,没办法,只能继续扩大占内存空间。(继续扩大)
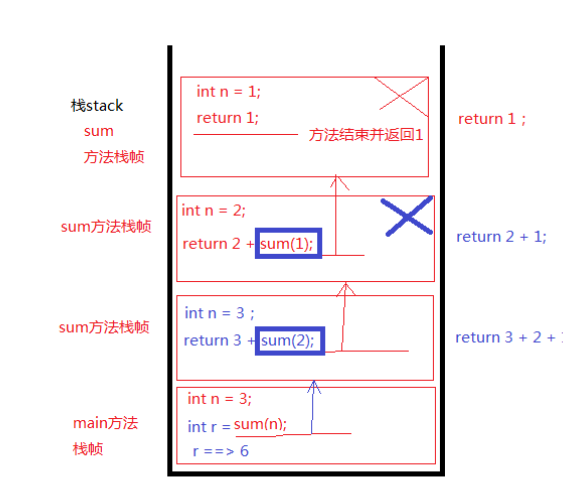
递归练习
//使用递归编写程序,计算1~n的和
public static void main(String[] args){int n = 3;int result = sum(n);System.out.println(result);
}//计算1~3的值public static void sum(int n){//n的初始值是3 然后使用if进行判断if(n==1){return 1;}//程序到这一步说明 n不等于1//下一步使用return返回最终结果return n + sum(n-1);//逐步分解 3 + sum(2) sum(2)再进行判断//2 +sum(1) sum(1)回到上一步 程序直接返回1 //最后结果就是 return 3 + 2 + 1 =====> 6}
递归练习之递归内存图变化
6、IDEA集成开发工具
IDEA常用快捷键总结
1. 根据psvm或者main快速生成主函数**
我们可以在类中输入psvm 或者main
然后IDEA会自动提示main(),敲击回车即可自动生成~
2. 根据sout快速生成打印语句
我们可以在方法中输入sout
然后IDEA会自动提示打印语句,敲击回车即可自动生成~
3. 查找的快捷键
按Ctrl + F表示在当前页面中查找
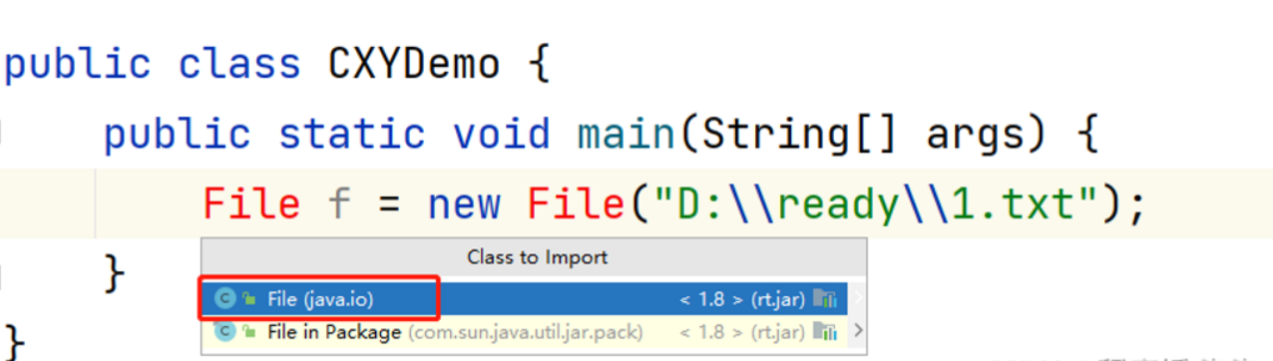
4. 万能键Alt+Enter
Alt+Enter是一个特别常用且好用的“万能键”
- 比如我们可以在类中导入需要导的包
- 再比如我们可以在类中快速生成方法的返回值和变量名
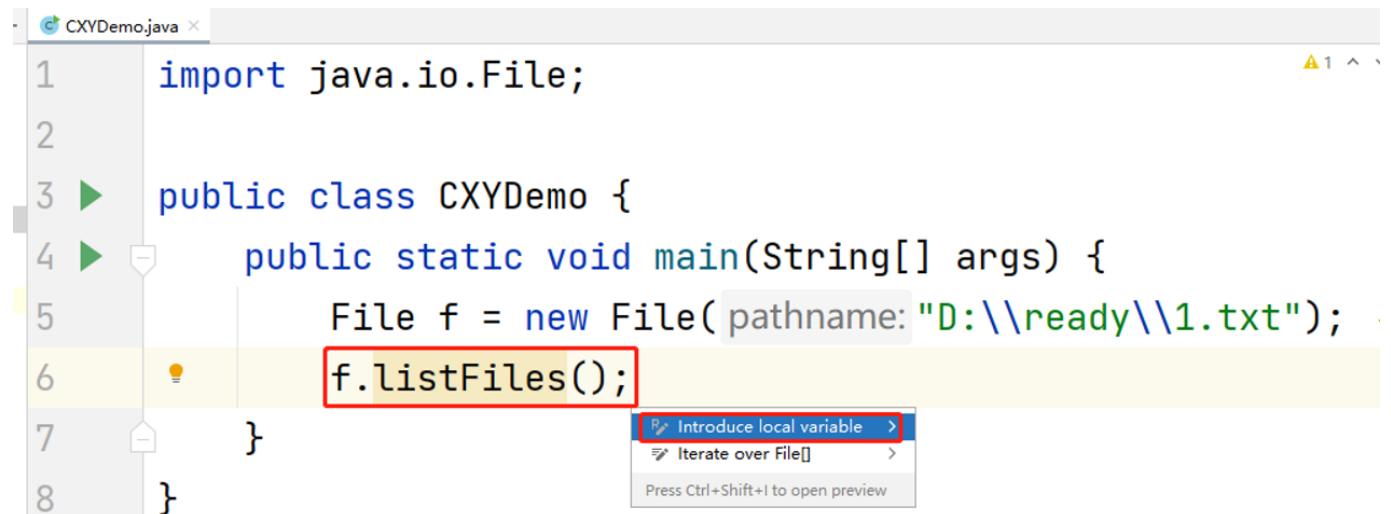
- 如果代码中需要处理异常,我们还可以快速选择是抛出还是捕获
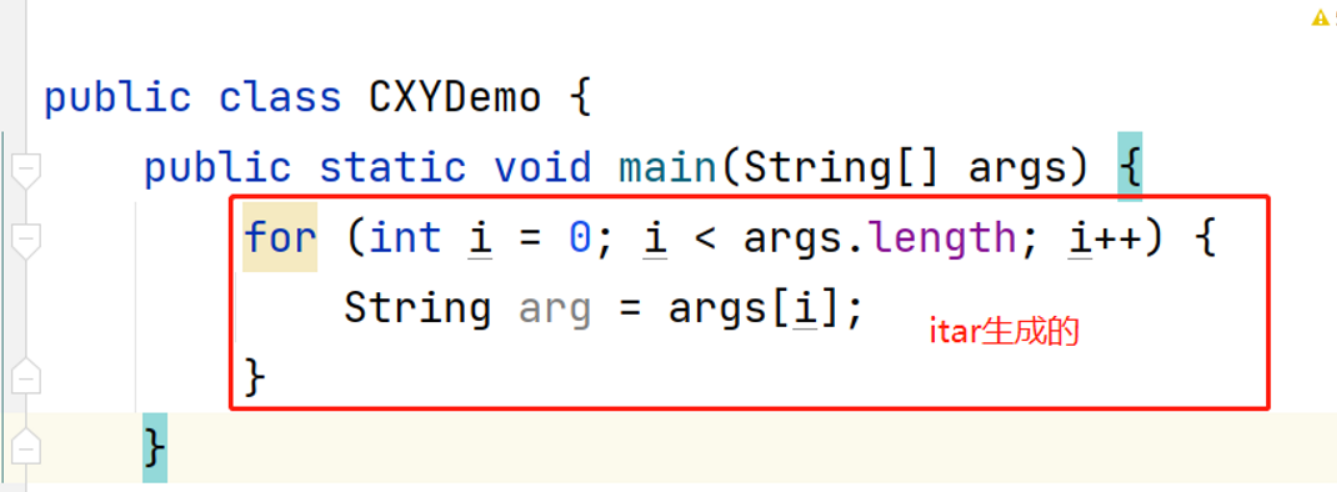
5. for循环的快捷键
itar : 生成普通的for循环
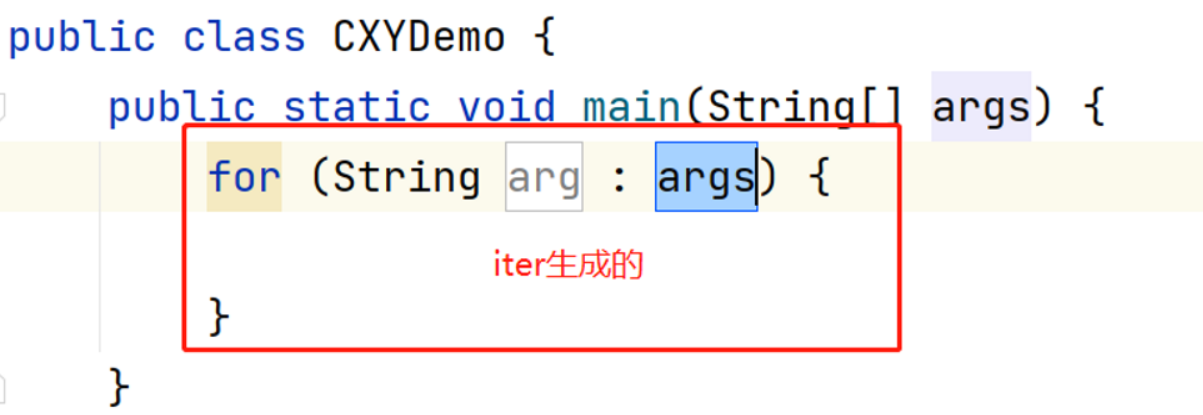
iter : 生成高效for循环
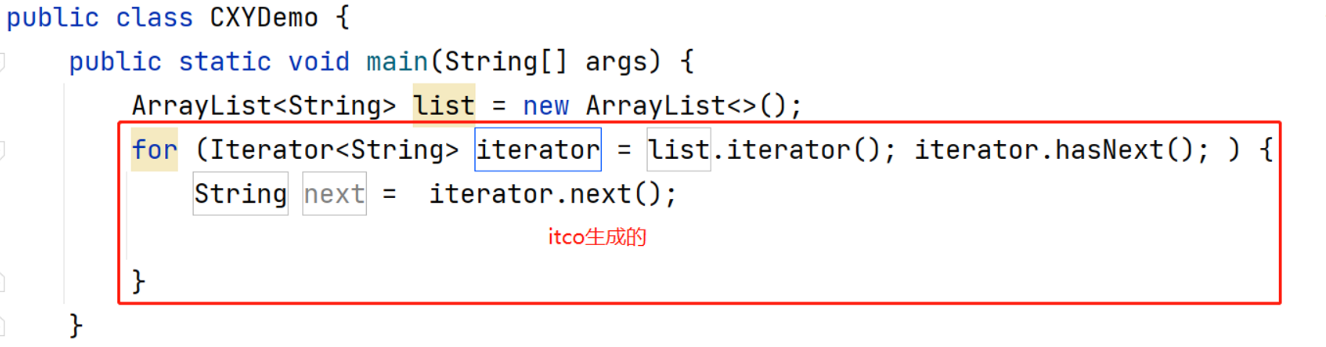
itco : 生成遍历集合的for循环
注意:这只是一种写法,具体根据自己的业务灵活使用哦~
6. Ctrl+N 搜索类
这个快捷键一般用来搜索源码
7. Ctrl+Shift+N 强力搜索
我们一般用这个快捷键查找自己所需的资源
8. Ctrl+H 查看类的继承关系
注意:查看的时候需要先选中自己想看的类名哦
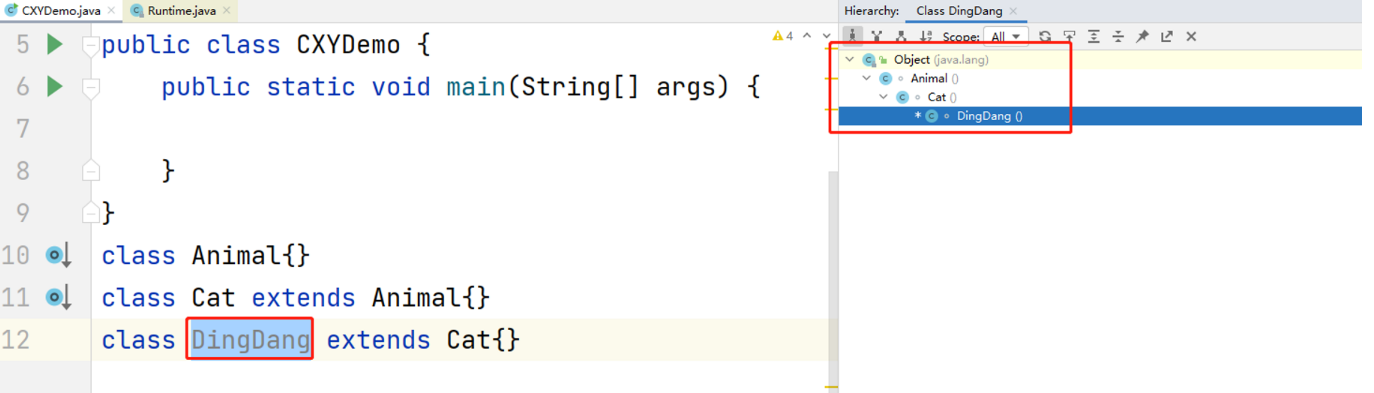
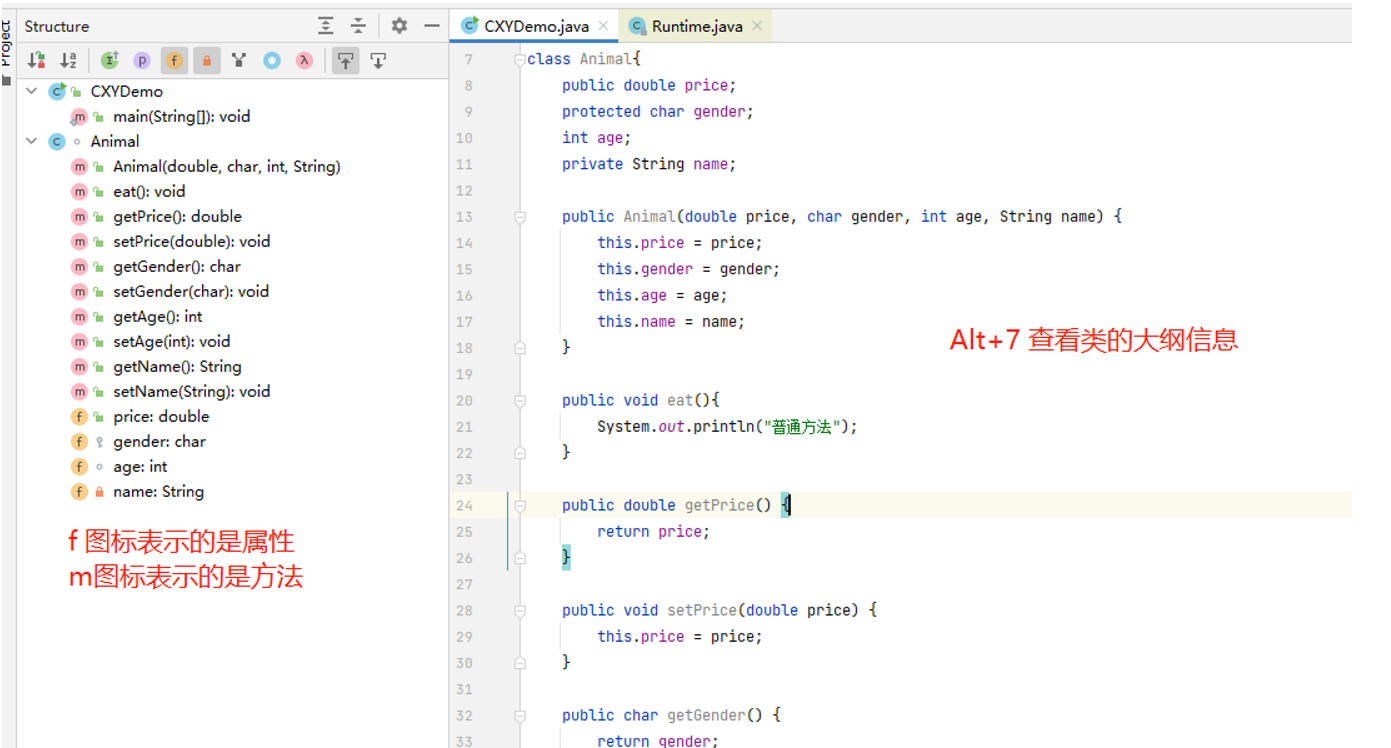
9. Alt+7 快速查看类的结构信息
额外其他快捷键
下面总结一下IDEA其他的快捷键
Ctrl系列
-
Ctrl + Y 删除光标所在行的所有内容,Ctrl+X也可以
-
Ctrl + D 快速向下复制当前行的内容
-
Ctrl + W 递进式选中代码可以先选中光标所在的一部分代码,连续按这个快捷键会在原来的基础上继续扩展被选中的内容
-
Ctrl + E 显示最近打开的文件记录列表
-
Ctrl + G 在当前文件跳转到指定位置处
-
Ctrl + Q 光标所在的变量 / 类名 / 方法名等上面(也可以在提示补充的时候按),显示文档内容
-
Ctrl + U 前往当前光标所在的方法的父类的方法 / 接口定义Ctrl + B 进入光标所在的方法/变量的接口或是定义处,等效于 Ctrl + 左键单击(必备)
-
Ctrl + O 选择可重写的方法
-
Ctrl + I 选择可继承的方法
-
Ctrl + / 注释光标所在行代码,会根据当前不同文件类型使用不同的注释符号 (必备)
-
Ctrl + F1 在光标所在的错误代码处显示错误信息
-
Ctrl + F3 调转到所选中的词的下一个引用位置
-
Ctrl + F4 关闭当前编辑文件
-
Ctrl + - 折叠代码
-
Ctrl + + 展开代码
-
Ctrl + Tab 编辑窗口切换,如果在切换的过程又加按上delete,则是关闭对应选中的窗口
-
Ctrl + Enter 智能分隔行
-
Ctrl + Delete 删除光标后面的单词或是中文句
-
Ctrl + BackSpace 删除光标前面的单词或是中文句
-
Ctrl + End 跳到文件尾
-
Ctrl + Home 跳到文件头
-
Ctrl + [ 移动光标到当前所在代码的花括号开始位置
-
Ctrl + ] 移动光标到当前所在代码的花括号结束位置
-
Ctrl + 左方向键 光标跳转到当前单词 / 中文句的左侧开头位置
-
Ctrl + 右方向键 光标跳转到当前单词 / 中文句的右侧开头位置
-
Ctrl + 前方向键 等效于鼠标滚轮向前效果
-
Ctrl + 后方向键 等效于鼠标滚轮向后效果
Alt系列
-
Alt+Shift+向上 向上移动选中的代码
-
Alt + Insert 代码自动生成,如生成对象的 set / get 方法,构造函数,toString() 等
-
Alt + 左方向键 按左方向切换当前已打开的文件视图
-
Alt + 右方向键 按右方向切换当前已打开的文件视图
-
Alt + 前方向键 当前光标跳转到当前文件的前一个方法名位置
-
Alt + 后方向键 当前光标跳转到当前文件的后一个方法名位置
Shift系列
-
Ctrl + Shift + Alt + V 无格式黏贴
-
Ctrl + Shift + Alt + N 前往指定的变量 / 方法
-
Ctrl + Shift + Alt + S 打开当前项目设置
-
Ctrl + Shift + - 折叠所有代码
-
Ctrl + Shift + + 展开所有代码
-
Ctrl + Shift + F12 编辑器最大化
Ctrl+ Shift 系列
-
Ctrl + Alt + S 打开设置
-
Ctrl + Alt + L 格式化代码,可以对当前文件和整个包目录使用
-
Ctrl + Alt + O 优化导入的类,可以对当前文件和整个包目录使用
-
Ctrl + Alt + I 光标所在行 或 选中部分进行自动代码缩进,有点类似格式化
7、 面向对象编程(OOP)
Java面向对象三大特性(基础篇)
面向对象简称 OO(Object Oriented),20 世纪 80 年代以后,有了面向对象分析(OOA)、 面向对象设计(OOD)、面向对象程序设计(OOP)等新的系统开发方式模型的研究。
对语言来说,一切皆是对象。把现实世界中的对象抽象地体现在编程世界中,一个对象代表了某个具体的操作。一个个对象最终组成了完整的程序设计,这些对象可以是独立存在的,也可以是从别的对象继承过来的。对象之间通过相互作用传递信息,实现程序开发。
对象的概念
Java 是面向对象的编程语言,对象就是面向对象程序设计的核心。所谓对象就是真实世界中的实体,对象与实体是一一对应的,也就是说现实世界中每一个实体都是一个对象,它是一种具体的概念。对象有以下特点:
-
对象具有属性和行为。
-
对象具有变化的状态。
-
对象具有唯一性。
-
对象都是某个类别的实例。
-
一切皆为对象,真实世界中的所有事物都可以视为对象。
面向对象和面向过程的区别
-
面向过程:
一种较早的编程思想,顾名思义就是该思想是站着过程的角度思考问题,强调的就是功能行为,功能的执行过程,即先后顺序,而每一个功能我们都使用函数(类似于方法)把这些步骤一步一步实现。使用的时候依次调用函数就可以了。 -
面向过程的设计:
最小的程序单元是函数,每个函数负责完成某一个功能,用于接受输入数据,函数对输入数据进行处理,然后输出结果数据,整个软件系统由一个个的函数组成,其中作为程序入口的函数称之为主函数,主函数依次调用其他函数,普通函数之间可以相互调用,从而实现整个系统功能。
面向过程最大的问题在于随着系统的膨胀,面向过程将无法应付,最终导致系统的崩溃。为了解决这一种软件危机,我们提出面向对象思想。 -
面向过程的缺陷:
是采用自顶而下的设计模式,在设计阶段就需要考虑每一个模块应该分解成哪些子模块,每一个子模块又细分为更小的子模块,如此类推,直到将模块细化为一个个函数。 -
存在的问题
设计不够直观,与人类的思维习惯不一致
系统软件适应新差,可拓展性差,维护性低 -
面向对象:
一种基于面向过程的新编程思想,顾名思义就是该思想是站在对象的角度思考问题,我们把多个功能合理放到不同对象里,强调的是具备某些功能的对象。
具备某种功能的实体,称为对象。面向对象最小的程序单元是:类。面向对象更加符合常规的思维方式,稳定性好,可重用性强,易于开发大型软件产品,有良好的可维护性。
在软件工程上,面向对象可以使工程更加模块化,实现更低的耦合和更高的内聚。
面向对象的三大核心特性简介
面向对象开发模式更有利于人们开拓思维,在具体的开发过程中便于程序的划分,方便程序员分工合作,提高开发效率。
该开发模式之所以使程序设计更加完善和强大,主要是因为面向对象具有继承、封装和多态 3 个核心特性。
1、继承的概念
继承是java面向对象编程技术的一块基石,因为它允许创建分等级层次的类。
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
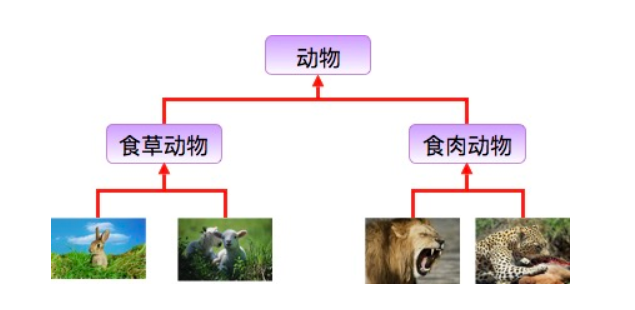
兔子和羊属于食草动物类,狮子和豹属于食肉动物类。
食草动物和食肉动物又是属于动物类。
所以继承需要符合的关系是:is-a,父类更通用,子类更具体。
虽然食草动物和食肉动物都是属于动物,但是两者的属性和行为上有差别,所以子类会具有父类的一般特性也会具有自身的特性。
2、Java 多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作,如图所示:
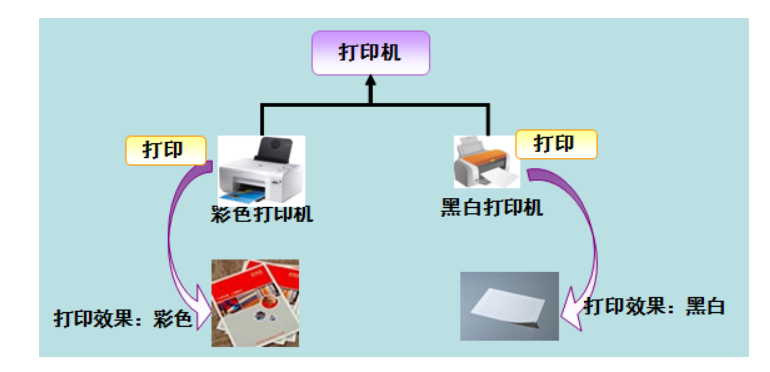
多态性是对象多种表现形式的体现。
现实中,比如我们按下 F1 键这个动作:
如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档;
如果当前在 Word 下弹出的就是 Word 帮助;
在 Windows 下弹出的就是 Windows 帮助和支持。
同一个事件发生在不同的对象上会产生不同的结果。
3、Java 封装
在面向对象程式设计方法中,封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部份包装、隐藏起来的方法。
封装可以被认为是一个保护屏障,防止该类的代码和数据被外部类定义的代码随机访问。
要访问该类的代码和数据,必须通过严格的接口控制。
封装最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。
适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性。
面向对象编程三大特性详解
面向对象编程是利用 类和对象编程的一种思想。万物可归类,类是对于世界事物的高度抽象 ,不同的事物之间有不同的关系 ,一个类自身与外界的封装关系,一个父类和子类的继承关系, 一个类和多个类的多态关系。万物皆对象,对象是具体的世界事物,面向对象的三大特征封装,继承,多态,封装,封装说明一个类行为和属性与其他类的关系,低耦合,高内聚;继承是父类和子类的关系,多态说的是类与类的关系。
一、继承
1、继承的概念
如同生活中的子女继承父母拥有的所有财产,程序中的继承性是指子类拥有父类数据结构的方法和机制,这是类之间的一种关系;继承只能是单继承。
例如定义一个语文老师类和数学老师类,如果不采用继承方式,那么两个类中需要定义的属性和方法如图 1 所示。

图1 语文老师类和数学老师类中的属性和方法
从图 1 能够看出,语文老师类和数学老师类中的许多属性和方法相同,这些相同的属性和方法可以提取出来放在一个父类中,这个父类用于被语文老师类和数学老师类继承。当然父类还可以继承别的类,如图 2 所示。
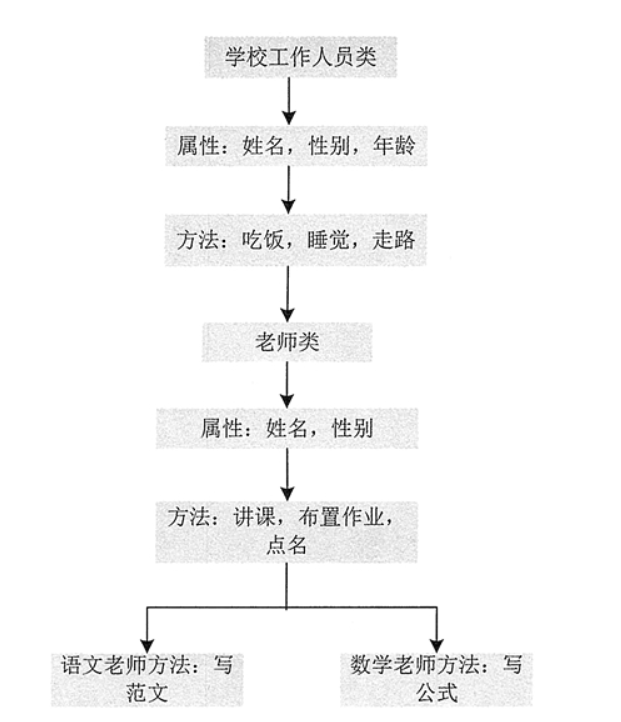
图2 父类继承示例图
总结图 2 的继承关系,可以用概括的树形关系来表示,如图 3 所示。
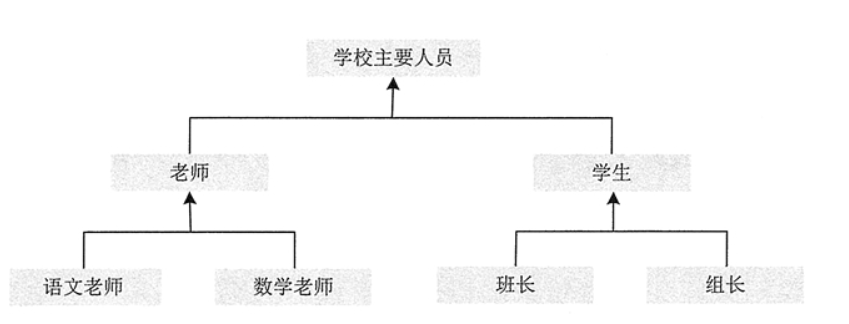
图3 类继承示例图
从图 3 中可以看出,学校主要人员是一个大的类别,老师和学生是学校主要人员的两个子类,而老师又可以分为语文老师和数学老师两个子类,学生也可以分为班长和组长两个子类。
使用这种层次形的分类方式,是为了将多个类的通用属性和方法提取出来,放在它们的父类中,然后只需要在子类中各自定义自己独有的属性和方法,并以继承的形式在父类中获取它们的通用属性和方法即可。
继承是类与类的一种关系,是一种“is a”的关系。比如“狗”继承“动物”,这里动物类是狗类的父类或者基类,狗类是动物类的子类或者派生类。如下图所示:
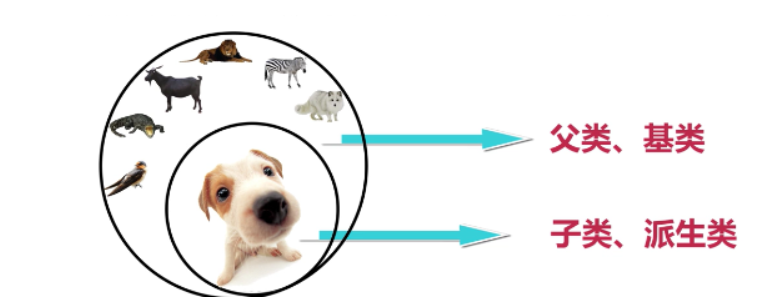
注:java中的继承是单继承,即一个类只有一个父类。
补充:Java中的继承只能单继承,但是可以通过内部类继承其他类来实现多继承。
public class Son extends Father{
public void go () {
System.out.println("son go");
}
public void eat () {
System.out.println("son eat");
}
public void sleep() {
System.out.println("zzzzzz");
}
public void cook() {
//匿名内部类实现的多继承
new Mother().cook();
//内部类继承第二个父类来实现多继承
Mom mom = new Mom();
mom.cook();
}
private class Mom extends Mother {
@Override
public void cook() {
System.out.println("mom cook");
}
}
}
2、继承的好处
子类拥有父类的所有属性和方法(除了private修饰的属性不能拥有)从而实现了实现代码的复用;
3、语法规则

A、方法的重写
子类如果对继承的父类的方法不满意(不适合),可以自己编写继承的方法,这种方式就称为方法的重写。当调用方法时会优先调用子类的方法。
重写要注意:
a、返回值类型
b、方法名
c、参数类型及个数
都要与父类继承的方法相同,才叫方法的重写。
重载和重写的区别:
方法重载:在同一个类中处理不同数据的多个相同方法名的多态手段。
方法重写:相对继承而言,子类中对父类已经存在的方法进行区别化的修改。
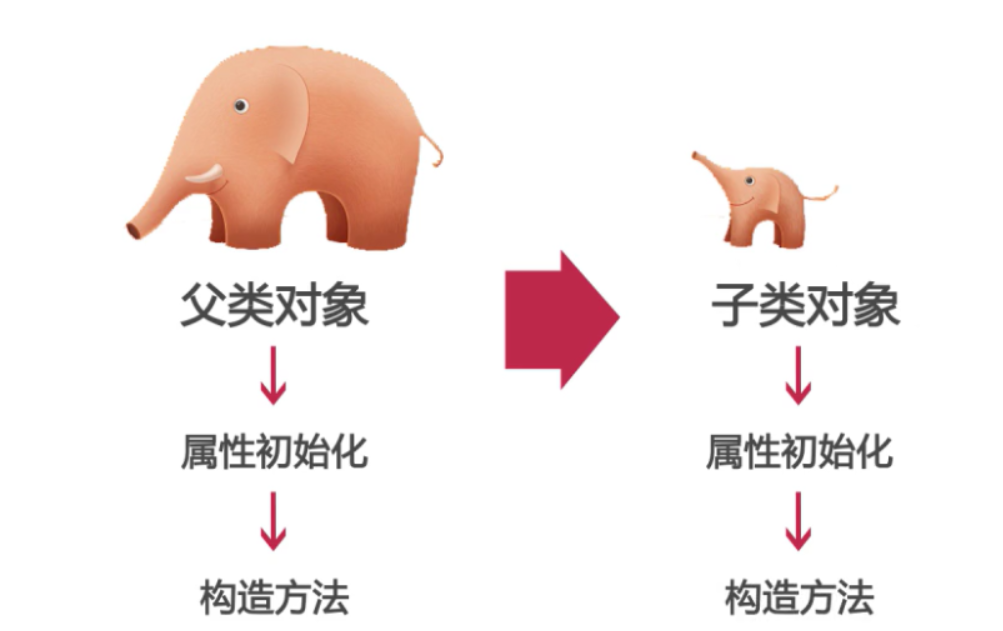
B、继承的初始化顺序
1、初始化父类再初始化子类
2、先执行初始化对象中属性,再执行构造方法中的初始化。
基于上面两点,我们就知道实例化一个子类,java程序的执行顺序是:
父类对象属性初始化---->父类对象构造方法---->子类对象属性初始化—>子类对象构造方法
下面有个形象的图:
C、final关键字
使用final关键字做标识有“最终的”含义。
1. final 修饰类,则该类不允许被继承。
2. final 修饰方法,则该方法不允许被覆盖(重写)。
3. final 修饰属性,则该类的该属性不会进行隐式的初始化,所以 该final 属性的初始化属性必须有值,或在**构造方法中赋值(但只能选其一,且必须选其一,因为没有默认值!),**且初始化之后就不能改了,只能赋值一次。
4. final 修饰变量,则该变量的值只能赋一次值,在声明变量的时候才能赋值,即变为常量。
D、super关键字
在对象的内部使用,可以代表父类对象。
1、访问父类的属性:super.age
2、访问父类的方法:super.eat()
super的应用:
首先我们知道子类的构造的过程当中必须调用父类的构造方法。其实这个过程已经隐式地使用了我们的super关键字。
这是因为如果子类的构造方法中没有显示调用父类的构造方法,则系统默认调用父类无参的构造方法。
那么如果自己用super关键字在子类里调用父类的构造方法,则必须在子类的构造方法中的第一行。
要注意的是:如果子类构造方法中既没有显示调用父类的构造方法,而父类没有无参的构造方法,则编译出错。
(补充说明,虽然没有显示声明父类的无参的构造方法,系统会自动默认生成一个无参构造方法,但是,如果你声明了一个有参的构造方法,而没有声明无参的构造方法,这时系统不会动默认生成一个无参构造方法,此时称为父类有没有无参的构造方法。)
二、封装
1、封装的概念
封装是将代码及其处理的数据绑定在一起的一种编程机制,该机制保证了程序和数据都不受外部干扰且不被误用。封装的目的在于保护信息,使用它的主要优点如下。
-
保护类中的信息,它可以阻止在外部定义的代码随意访问内部代码和数据。
-
隐藏细节信息,一些不需要程序员修改和使用的信息,比如取款机中的键盘,用户只需要知道按哪个键实现什么操作就可以,至于它内部是如何运行的,用户不需要知道。
-
有助于建立各个系统之间的松耦合关系,提高系统的独立性。当一个系统的实现方式发生变化时,只要它的接口不变,就不会影响其他系统的使用。例如 U 盘,不管里面的存储方式怎么改变,只要 U 盘上的 USB 接口不变,就不会影响用户的正常操作。
-
提高软件的复用率,降低成本。每个系统都是一个相对独立的整体,可以在不同的环境中得到使用。例如,一个 U 盘可以在多台电脑上使用。
Java 语言的基本封装单位是类。由于类的用途是封装复杂性,所以类的内部有隐藏实现复杂性的机制。Java 提供了私有和公有的访问模式,类的公有接口代表外部的用户应该知道或可以知道的每件东西,私有的方法数据只能通过该类的成员代码来访问,这就可以确保不会发生不希望的事情。
2、封装的优点
在面向对象程式设计方法中,封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部份包装、隐藏起来的方法。
封装可以被认为是一个保护屏障,防止该类的代码和数据被外部类定义的代码随机访问。
要访问该类的代码和数据,必须通过严格的接口控制。
封装最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。
适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性。
封装的优点
-
良好的封装能够减少耦合。
-
类内部的结构可以自由修改。
-
可以对成员变量进行更精确的控制。
-
隐藏信息,实现细节。
Java 封装,说白了就是将一大坨公共通用的实现逻辑玩意,装到一个盒子里(class),出入口都在这个盒子上。你要用就将这个盒子拿来用,连接出入口,就能用了,不用就可以直接扔,对你代码没什么影响。
对程序员来说,使用封装的目的:
-
偷懒,辛苦一次,后面都能少敲很多代码,增强了代码得复用性
-
简化代码,看起来更容易懂
-
隐藏核心实现逻辑代码,简化外部逻辑,并且不让其他人修改,jar 都这么干
-
一对一,一个功能就只为这个功能服务;避免头发绳子一块用,导致最后一团糟
3、封装的实现步骤
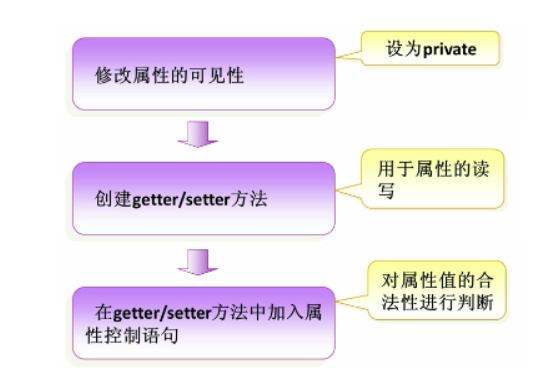
需要注意:对封装的属性不一定要通过get/set方法,其他方法也可以对封装的属性进行操作。当然最好使用get/set方法,比较标准。
A、访问修饰符
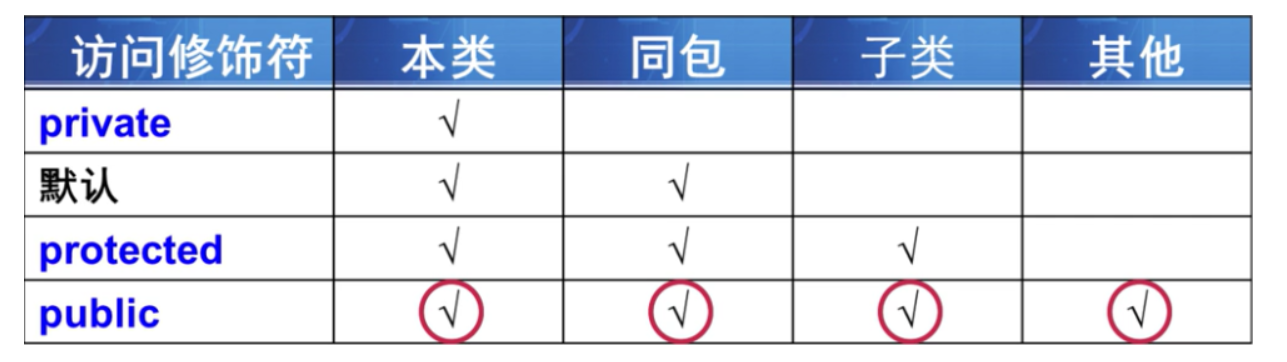
从表格可以看出从上到下封装性越来越差。
B、this关键字
1.this关键字代表当前对象
this.属性 操作当前对象的属性
this.方法 调用当前对象的方法。
2.封装对象的属性的时候,经常会使用this关键字。
3.当getter和setter函数参数名和成员函数名重合的时候,可以使用this****区别。如:

C、Java 中的内部类
内部类( Inner Class )就是定义在另外一个类里面的类。与之对应,包含内部类的类被称为外部类。
那么问题来了:那为什么要将一个类定义在另一个类里面呢?清清爽爽的独立的一个类多好啊!!
答:内部类的主要作用如下:
1. 内部类提供了更好的封装,可以把内部类隐藏在外部类之内,不允许同一个包中的其他类访问该类。
2. 内部类的方法可以直接访问外部类的所有数据,包括私有的数据。
3. 内部类所实现的功能使用外部类同样可以实现,只是有时使用内部类更方便。
内部类可分为以下几种:
-
成员内部类
-
静态内部类
-
方法内部类
-
匿名内部类
三、多态
1、多态的概念
面向对象的多态性,即“一个接口,多个方法”。多态性体现在父类中定义的属性和方法被子类继承后,可以具有不同的属性或表现方式。多态性允许一个接口被多个同类使用,弥补了单继承的不足。多态概念可以用树形关系来表示,如图 4 所示。
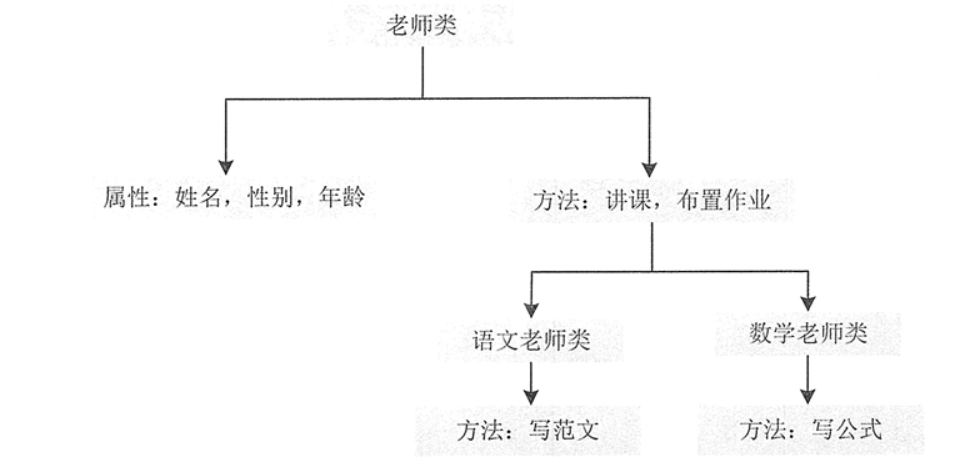
图4 多态示例图
从图 4 中可以看出,老师类中的许多属性和方法可以被语文老师类和数学老师类同时使用,这样也不易出错。
2、多态的好处
可替换性(substitutability)。多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。
可扩充性(extensibility)。多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如,在实现了圆锥、半圆锥以及半球体的多态基础上,很容易增添球体类的多态性。
接口性(interface-ability)。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的。
灵活性(flexibility)。它在应用中体现了灵活多样的操作,提高了使用效率。
简化性(simplicity)。多态简化对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。
子代父类实例化,然后就相当于一个父亲有很多儿子,送快递的给这个父亲的儿子送东西,他只需要送到父亲的家就行了,至于具体是那个儿子的,父亲还会分不清自己的儿子么,所以你就不用操心了。
使用多态是一种好习惯
多态方式声明是一种好的习惯。当我们创建的类,使用时,只用到它的超类或接口定义的方法时,我们可以将其索引声明为它的超类或接口类型。
它的好处是,如果某天我们对这个接口方法的实现方式变了,对这个接口又有一个新的实现类,我们的程序也需要使用最新的实现方式,此时只要将对象实现修改一下,索引无需变化。
比如Map< String,String> map = new HashMap < String,String>();
想换成HashTable实现,可以Map< String,String> map = new HashTable < String,String>();
比如写一个方法,参数要求传递List类型,你就可以用List list = new ArrayList()中的list传递,但是你写成ArrayList list = new ArrayList()是传递不进去的。尽管方法处理时都一样。另外,方法还可以根据你传递的不同list(ArrayList或者LinkList)进行不同处理。
3、Java中的多态
java里的多态主要表现在两个方面:
A、引用多态
父类的引用可以指向本类的对象;
父类的引用可以指向子类的对象;
这两句话是什么意思呢,让我们用代码来体验一下,首先我们创建一个父类Animal和一个子类Dog,在主函数里如下所示:

注意:我们不能使用一个子类的引用来指向父类的对象,如: 。
。
这里我们必须深刻理解引用多态的意义,才能更好记忆这种多态的特性。为什么子类的引用不能用来指向父类的对象呢?我在这里通俗给大家讲解一下:就以上面的例子来说,我们能说“狗是一种动物”,但是不能说“动物是一种狗”,狗和动物是父类和子类的继承关系,它们的从属是不能颠倒的。当父类的引用指向子类的对象时,该对象将只是看成一种特殊的父类(里面有重写的方法和属性),反之,一个子类的引用来指向父类的对象是不可行的!!
B、方法多态
根据上述创建的两个对象:本类对象和子类对象,同样都是父类的引用,当我们指向不同的对象时,它们调用的方法也是多态的。
创建本类对象时,调用的方法为本类方法;
创建子类对象时,调用的方法为子类重写的方法或者继承的方法;
使用多态的时候要注意:如果我们在子类中编写一个独有的方法(没有继承父类的方法),此时就不能通过父类的引用创建的子类对象来调用该方法!!!
注意: 继承是多态的基础。
C、引用类型转换
了解了多态的含义后,我们在日常使用多态的特性时经常需要进行引用类型转换。
引用类型转换:
1.向上类型转换(隐式/自动类型转换),是小类型转换到大类型
就以上述的父类Animal和一个子类Dog来说明,当父类的引用可以指向子类的对象时,就是向上类型转换。如:

2. 向下类型转换(强制类型转换),是大类型转换到小类型(有风险,可能出现数据溢出)。
将上述代码再加上一行,我们再次将父类转换为子类引用,那么会出现错误,编译器不允许我们直接这么做**,虽然我们知道这个父类引用指向的就是子类对象,但是编译器认为这种转换是存在风险的。**如:

那么我们该怎么解决这个问题呢,我们可以在animal前加上(Dog)来强制类型转换。如:
但是如果父类引用没有指向该子类的对象,则不能向下类型转换,虽然编译器不会报错,但是运行的时候程序会出错,如:

其实这就是上面所说的子类的引用指向父类的对象,而强制转换类型也不能转换!!
还有一种情况是父类的引用指向其他子类的对象,则不能通过强制转为该子类的对象。如:

这是因为我们在编译的时候进行了强制类型转换,编译时的类型是我们强制转换的类型,所以编译器不会报错,而当我们运行的时候,程序给animal开辟的是Dog类型的内存空间,这与Cat类型内存空间不匹配,所以无法正常转换。这两种情况出错的本质是一样的,所以我们在使用强制类型转换的时候要特别注意这两种错误!!下面有个更安全的方式来实现向下类型转换。。。。
3. instanceof运算符,来解决引用对象的类型,避免类型转换的安全性问题。
instanceof是Java的一个二元操作符,和==,>,<是同一类东东。由于它是由字母组成的,所以也是Java的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回boolean类型的数据。
我们来使用instanceof运算符来规避上面的错误,代码修改如下:

利用if语句和instanceof运算符来判断两个对象的类型是否一致。
**补充说明:**在比较一个对象是否和另一个对象属于同一个类实例的时候,我们通常可以采用instanceof和getClass两种方法通过两者是否相等来判断,但是两者在判断上面是有差别的。Instanceof进行类型检查规则是:你属于该类吗?或者你属于该类的派生类吗?而通过getClass获得类型信息采用==来进行检查是否相等的操作是严格的判断,不会存在继承方面的考虑;
**总结:**在写程序的时候,如果要进行类型转换,我们最好使用instanceof运算符来判断它左边的对象是否是它右边的类的实例,再进行强制转换。
D、重写和重载
多态一般可以分为两种,一个是重写override,一个是重载overload。
重写是由于继承关系中的子类有一个和父类同名同参数的方法,会覆盖掉父类的方法。重载是因为一个同名方法可以传入多个参数组合。注意,同名方法如果参数相同,即使返回值不同也是不能同时存在的,编译会出错。从jvm实现的角度来看,重写又叫运行时多态,编译时看不出子类调用的是哪个方法,但是运行时操作数栈会先根据子类的引用去子类的类信息中查找方法,找不到的话再到父类的类信息中查找方法。而重载则是编译时多态,因为编译期就可以确定传入的参数组合,决定调用的具体方法是哪一个了。
1. 向上转型和向下转型
public static void main(String[] args) {Son son = new Son();//首先先明确一点,转型指的是左侧引用的改变。//father引用类型是Father,指向Son实例,就是向上转型,既可以使用子类的方法,也可以使用父类的方法。//向上转型,此时运行father的方法Father father = son;father.smoke();//不能使用子类独有的方法。// father.play();编译会报错father.drive();//Son类型的引用指向Father的实例,所以是向下转型,不能使用子类非重写的方法,可以使用父类的方法。//向下转型,此时运行了son的方法Son son1 = (Son) father;//转型后就是一个正常的Son实例son1.play();son1.drive();son1.smoke();//因为向下转型之前必须先经历向上转型。//在向下转型过程中,分为两种情况://情况一:如果父类引用的对象如果引用的是指向的子类对象,//那么在向下转型的过程中是安全的。也就是编译是不会出错误的。//因为运行期Son实例确实有这些方法Father f1 = new Son();Son s1 = (Son) f1;s1.smoke();s1.drive();s1.play();//情况二:如果父类引用的对象是父类本身,那么在向下转型的过程中是不安全的,编译不会出错,//但是运行时会出现java.lang.ClassCastException错误。它可以使用instanceof来避免出错此类错误。//因为运行期Father实例并没有这些方法。Father f2 = new Father();Son s2 = (Son) f2;s2.drive();s2.smoke();s2.play();//向下转型和向上转型的应用,有些人觉得这个操作没意义,何必先向上转型再向下转型呢,不是多此一举么。其实可以用于方法参数中的类型聚合,然后具体操作再进行分解。//比如add方法用List引用类型作为参数传入,传入具体类时经历了向下转型add(new LinkedList());add(new ArrayList());//总结//向上转型和向下转型都是针对引用的转型,是编译期进行的转型,根据引用类型来判断使用哪个方法//并且在传入方法时会自动进行转型(有需要的话)。运行期将引用指向实例,如果是不安全的转型则会报错。//若安全则继续执行方法。}
public static void add(List list) {System.out.println(list);//在操作具体集合时又经历了向上转型
// ArrayList arr = (ArrayList) list;
// LinkedList link = (LinkedList) list;
}
总结:
向上转型和向下转型都是针对引用的转型,是编译期进行的转型,根据引用类型来判断使用哪个方法。并且在传入方法时会自动进行转型(有需要的话)。运行期将引用指向实例,如果是不安全的转型则会报错,若安全则继续执行方法。
2. 编译期的静态分派
其实就是根据引用类型来调用对应方法。
public static void main(String[] args) {Father father = new Son();静态分派 a= new 静态分派();//编译期确定引用类型为Father。//所以调用的是第一个方法。a.play(father);//向下转型后,引用类型为Son,此时调用第二个方法。//所以,编译期只确定了引用,运行期再进行实例化。a.play((Son)father);//当没有Son引用类型的方法时,会自动向上转型调用第一个方法。a.smoke(father);//
}
public void smoke(Father father) {System.out.println("father smoke");
}
public void play (Father father) {System.out.println("father");//father.drive();
}
public void play (Son son) {System.out.println("son");//son.drive();
}
3. 方法重载优先级匹配
public static void main(String[] args) {方法重载优先级匹配 a = new 方法重载优先级匹配();//普通的重载一般就是同名方法不同参数。//这里我们来讨论当同名方法只有一个参数时的情况。//此时会调用char参数的方法。//当没有char参数的方法。会调用int类型的方法,如果没有int就调用long//即存在一个调用顺序char -> int -> long ->double -> ..。//当没有基本类型对应的方法时,先自动装箱,调用包装类方法。//如果没有包装类方法,则调用包装类实现的接口的方法。//最后再调用持有多个参数的char...方法。a.eat('a');a.eat('a','c','b');
}
public void eat(short i) {System.out.println("short");
}
public void eat(int i) {System.out.println("int");
}
public void eat(double i) {System.out.println("double");
}
public void eat(long i) {System.out.println("long");
}
public void eat(Character c) {System.out.println("Character");
}
public void eat(Comparable c) {System.out.println("Comparable");
}
public void eat(char ... c) {System.out.println(Arrays.toString(c));System.out.println("...");
}// public void eat(char i) {
// System.out.println("char");
// }
初始面向对象
-
属性+方法=类
-
对于描述复杂的事物,为了从宏观上把握、从整体上合理分析,我们需要使用面向对象来分析整个系统。但是,具体到微观操作,仍然需要面向过程的思路去处理。
-
面现象对象比那晨光的本质就是:以类的方式组织代码,以对象的组织(封装)数据。
-
从认识论角度考虑是现有对象后有类。
回顾方法的定义以及调用
定义
-
main方法
//main 方法 public static void main(String[] args) { } /*修饰符 返回值类型 方法名(……){ //方法体 return 返回值; } */ public String sayhello(){ return "hello world"; } public void print(){ return; } public int max(int a,int b){ return a>b ?a :b; } -
方法的调用
Students students =new Students(); students.say(); -
注意值传递跟参数传递
public static void main(String[] args) {Person person= new Person();System.out.println(person.name); Demo05.change(person); System.out.println(person.name);} public static void change(Person person){ person.name="张三"; } }class Person{ String name;//null
类和对象的关系
-
类是一种冲向的数据类型,它对某一类事物整体描述/定义但是并不能代表某一个具体的事物,类是抽象的。
-
对象时抽象概念的具体实例
创建和初始化对象
-
使用new关键字初始化对象时,除了分配内存空间外,还会给创建好的对象,进行默认的初始化和类中构造器的使用。
-
一个类即使什么都不写,他也会存在一个方法
-
构造器
-
和类名相同
-
没有返回值
-
-
核心作用:
-
使用new关键字,本质在调用构造器
-
构造器来初始化值
-
-
在无参构造器中,无参构造器可以实例化初始值
//无参构造器 public Person(){ } //在main方法中 Person person=new Person();注意点:
-
有参构造器:一旦定义了有参构造,无参就必须显示定义
-
Alt+Inser
-
内存分析
//类:抽象的,实例化 //类实例化会返回一个自己的对象 //student对象就是一个Students类的具体实例
Students xiaoming =new Students(); xiaoming.name="小明"; xiaoming.age=3; xiaoming.study(); xiaoming.play(); System.out.println(xiaoming.name); System.out.println(xiaoming.age); Students xiaohong=new Students(); xiaohong.name="小红"; xiaohong.age=15; xiaohong.study();
System.out.println(xiaohong.name); System.out.println(xiaohong.age);- 对象通过引用类型来操作:栈 - - ->堆
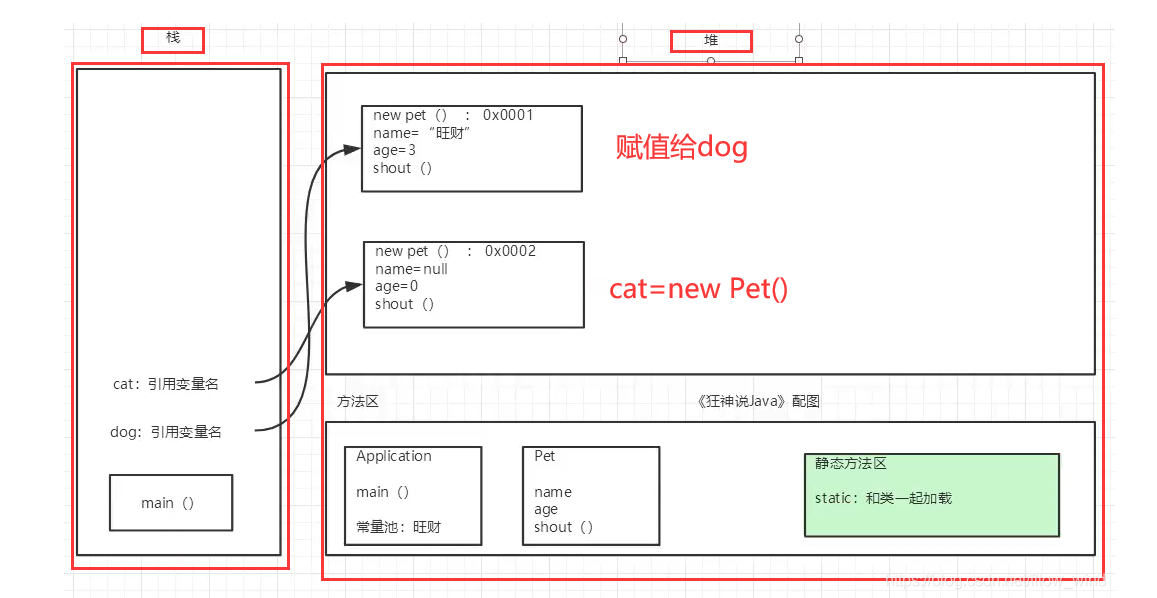
创建对象时JVM的内存变化
Java面向对象之各种变量详解
前言
在 Java语言中, 根据定义变量位置的不同,可以将变量分成两大类:
- 成员变量
- 局部变量
成员变量和局部变量的运行机制存在很大差异,下面我们看看差异在哪.
成员变量
成员变量指的是在类里定义的变量.
局部变量指的是在方法里定义的变量.下面我给出Java程序中的变量划分图:
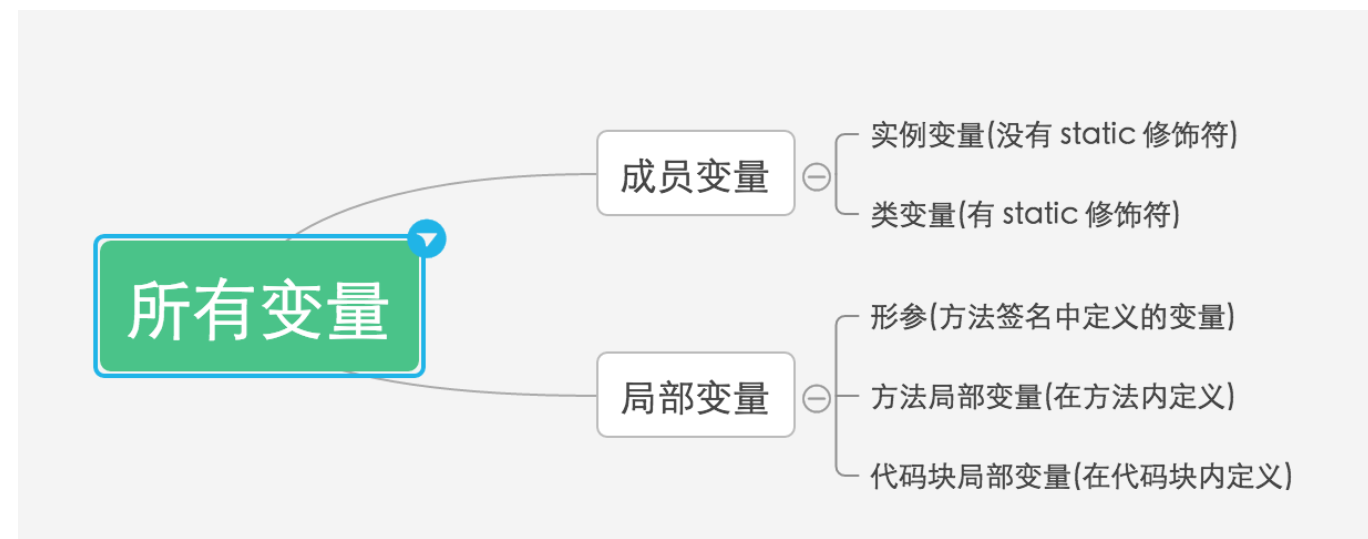
成员变量被分为类变量和实例变量两种.
定义成员变量时没有 static 修饰符的就是实例变量.
有static修饰符的就是类变量.
其中, 类变量从该类的准备阶段起开始存在.
直到系统完全销毁这个类,类变量的作用域与这个类的生存范围相同.
而实例变量则从该类的实例被创建起开始存在,知道系统完全销毁这个实例.
实例变量的作用域与对应实例的生存范围相同.
小知识: 一个类在使用之前需要经过 类加载 / 类验证 / 类准备 / 类解析 / 类初始化 等几个阶段.
正是基于以上原因, 可以把类变量和实例变量统称为成员变量.
其中, 类变量可以理解为 类成员变量, 它作为类本身的一个成员, 与类本身共存亡.
实例变量则可以理解为 实例成员变量, 它作为实例的一个成员, 与实例共存亡.
只要类存在, 程序就可以访问该类的类变量.
在程序中通过如下语法访问:
类.类变量
只要实例存在, 程序就可以访问该实例的实例变量.
在程序中通过如下语法访问:
实例.实例变量
当然, 类变量也可以让该类的实例来访问.
通过实例访问类变量的语法如下:
实例.类变量
但由于这个实例并不拥有这个类变量.
因此它访问的并不是这个实例的变量,依然是访问它对应类的类变量.
也就是说, 如果通过一个实例修改了类变量的值, 由于这个类变量并不属于它.
而是属于它对应的类. 因此, 修改的依然是类的类变量.
与通过该类来修改类变量的结果完全相同.
这会导致该类的其它实例来访问这个类变量时也获得这个被修改过的值.
下面我写个程序, 定义了一个 Person 类, 在这个 Person 类中定义两个成员变量.
一个类变量: eyeNum
一个实例变量: name
程序通过 PersonTest 类来创建 Person 实例.
并分别通过 Person 类 和 Person 实例来访问实例变量和类变量.
class Person
{//定义一个类变量public static int eyeNum;//定义一个实例变量public String name;
}public class PersonTest
{public static void main(String[] args){//第一次主动使用 Person 类, 该类自动初始化, 则 eyeNum 变量开始起作用, 输出 0System.out.println("Person 的 eyeNum 类变量的值:" + Person.eyeNum);//创建 Person 对象Person p = new Person();//通过 Person 对象的引用 p 来访问 Person 对象的 name 实例变量//并通过实例访问 eyeNum 类变量System.out.println("p 对象的 name 变量的值是:" + p.name + "p 对象的 eyeNum 变量的值是:" + p.eyeNum);//直接为 name 实例变量赋值p.name = "孙悟空";//通过 p 访问 eyeNum 类变量, 依然是访问 Person 的 eyeNum 类变量p.eyeNum = 2;//再次通过 Person 对象来访问 name 实例变量 和 eyeNum 类变量System.out.println("p 对象的 name 变量值是:" + p.name + "p 对象的 eyeNum 变量值是:" + p.eyeNum);//前面通过 p 修改了 Person 的 eyeNum, 此处的 Person.eyeNum 将输出 2System.out.println("Person 的 eyeNum 类变量值:" + Person.eyeNum);Person p2 = new Person();//p2 访问的 eyeNum 类变量依然引用 Person 类的, 因此依然输出 2System.out.println("p2 对象的 eyeNum 类变量值:" + p2.eyeNum);}
}从上面程序可以看出, 成员变量无须显式初始化.
只要为一个类定义了 类变量 或 实例变量.(类变量在程序开始之前,系统会自动初始化变量)
系统就会在这个类的准备阶段或创建该类的实例时进行默认初始化.
成员变量默认初始化的赋值规则与我们之前讲的 数组动态初始化 时数组元素的赋值规则完全相同.
我们还可以得知, 类变量的作用域 比 实例变量的作用域 更大.
实例变量随实例的存在而存在.
而类变量则随类的存在而存在.
实例也可以访问类变量, 同一个类的所有实例访问类变量时.
实际上访问的是该类本身的同一个变量, 也就是说, 访问了同一片内存区.
注意!!!
Java 允许实例访问 static 修饰的类变量本身就是一个错误.
因此建议你以后看到通过实例来访问 static 修饰的类变量时, 都可以将它替换成通过类本身来访问. 这样程序的可读性 / 明确性 都会大大提高!
局部变量
局部变量根据定义形式的不同, 可以分为如下三种:
-
形参:在方法定义签名时定义的变量,形参的作用域只在这个方法内有效。
-
方法的局部变量:在方法体内定义的局部变量,它的作用域就是从定义该变量的地方生效,直到方法结束时失效。
-
代码块局部变量:在代码块中定义的局部变量,这个局部变量的作用域从定义该变量的地方生效,直到该代码块结束时失效。
与成员变量不同的是, 局部变量除了形参之外, 都必需显式初始化.
也就是说, 必需先给方法局部变量和代码块局部变量指定初始值, 否则不可以访问它们.下面我写个定义代码块局部变量的程序.
public class BlockTest
{public static void main(String[] args){{//定义一个代码块局部变量 aint a;//下面代码将会出现错误, 因为 a 变量没有初始化System.out.println("代码块局部变量 a 的值:" + a);}//下面试图访问 a 变量, 但 a 变量的作用域根本无法涉及这里System.out.println(a);}
}上面的代码是一个错误示例, 如果你写出来还要运行的话, 只能说你 too yang to simple.
从上面代码可以看出, 只要离开了 代码块局部变量 所在的代码块, 这个局部变量就没法用了.
对于方法局部变量, 其作用域从定义该变量开始, 直到该方法结束.
下面我写个 方法局部变量的作用域 示例.
public class MethodLocalVariableTest
{public static void main(String[] args){//定义一个方法局部变量 aint a;//下面代码将会出现错误, 因为 a 变量没有初始化System.out.println("方法局部变量 a 的值:" + a);} 下面说说形参.
形参的作用域时整个方法体内有效, 而且形参也无须显式初始化.
形参的初始化在调用该方法时由系统完成, 形参的值由方法的调用者负责指定.
在同一个类里, 成员变量的作用域是整个类内有效.
一个类里不能定义两个同名的成员变量.
就算一个是类变量, 一个是实例变量也不行.
一个方法里不能定义两个同名的成员变量.
方法局部变量与形参名也不能同名.
同一个方法中不同代码块内的代码块局部变量可以同名.
如果先定义代码块局部变量, 后定义方法局部变量.
前面定义的代码块局部变量与后面定义的方法局部变量是可以同名的.
Java允许局部变量和成员变量同名.
如果方法里的局部变量和成员变量同名, 局部变量会覆盖成员变量.
如果需要在这个方法里引用被覆盖的成员变量.
可以使用 this (对于实例变量) 或 类名(对于类变量) 来作为调用者.
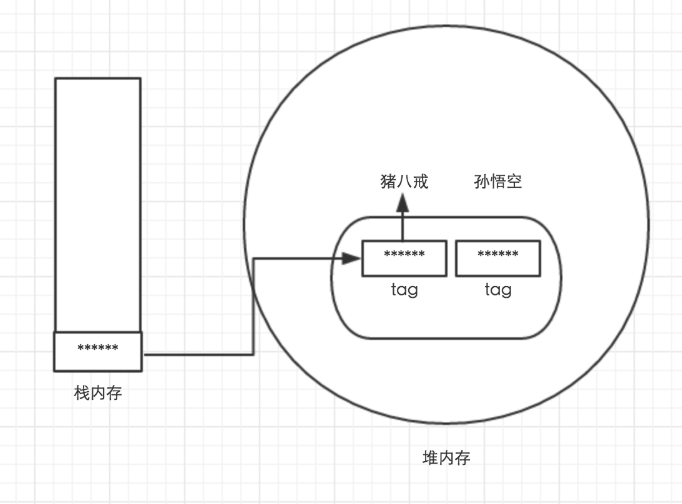
下面, 我写个程序.
public class VariableOverrideTest
{//定义一个 name 实例变量private String name = "猪八戒";//定义一个 price 类变量private static double price = 78.0;//主方法, 程序的入口public static void main(String[] args){//方法里的局部变量, 局部变量覆盖成员变量int price = 65;//直接访问 price 变量, 将输出 price 局部变量的值.System.out.println(price);//使用类名作为 price 变量的调用者, 访问被覆盖的 类变量System.out.println(VariableOverrideTest.price);//运行 info 方法new VariableOverrideTest().info();}public void info(){//方法里的局部变量, 局部变量覆盖成员变量String name = "孙悟空";//直接访问 name 变量, 将输出 孙悟空System.out.println(name);//使用 this 来作为 name 的调用者, 访问 实例变量System.out.println(this.name);}
}从上面代码可以看出, 当局部变量覆盖成员变量时.
依然可以在方法中显式指定 类名和this 作为调用者来访问被覆盖的成员变量, 这使得变成更加自由.
不过, 不过, 不过 . 你应该尽量避免这种局部变量和成员变量同名的情形. (想个名字真的有那么难么 - - )
成员变量(属性)和局部变量的区别?
-
成员变量:
-
成员变量定义在类中,在整个类中都可以被访问。
-
成员变量分为类成员变量和实例成员变量,实例变量存在于对象所在的堆内存中。
-
成员变量有默认初始值。
-
成员变量的权限修饰符可以根据需要,任意选择一个。
-
- 如,public,private。
-
局部变量:
-
局部变量只定义在局部范围内,如,方法内,代码块等。
-
局部变量存在于栈内存中。
-
作用的范围结束,变量的空间会自动释放。
-
局部变量没有默认初始值,每次必定显示初始值。
-
局部变量声明时不指定权限修饰符。
成员变量的初始化和内存中的运行机制
当系统加载类或创建该类的实例时.
系统将自动为成员变量分配内存空间.
并在分配内存空间后, 自动为成员变量指定初始值.下面通过代码来创建两个实例(非完整代码,能明白就行).
同时配合示意图来说明 Java 成员变量的初始化和内存中的运行机制.
//创建第一个 Person 对象
Person p1 = new Person();
//创建第二个 Person 对象
Person p2 = new Person();
//分别为两个 Person 对象的 name 实例变量赋值
p1.name = "孙悟空";
p2.name = "皮卡丘";
//分别为两个 Person 对象的 eyeNum 类变量赋值
p1.eyeNum = 2;
p2.eyeNum = 3;
下面开始解读:
当程序执行第一行代码 Person p1 = new Person(); 时
如果这行代码是第一次使用 Person 类.
则系统会加载并初始化这个类.
在类的准备阶段.
系统将会为该类的类变量分配内存空间,并指定默认初始值.
当 Person 类初始化完成后.
系统将在堆内存中为 Person 类分配一块内存区.
在这块内存区中, 包含了 保存 eyeNum 类变量的内存.
并设置 eyeNum 的默认初始值为: 0
系统接着创建了一个 Person 对象.
并把这个 Person 对象赋给 p1 变量.
Person 对象里包含了名为 name 的实例变量.
实例变量是在创建实例时分配内存空间并指定初始值的.
它是属于 Person 类的.
所以创建第一个 Person 对象时并不需要为 eyeNum 类变量分配内存(废话…)
系统只为 name 实例变量分配了内存空间.
并指定默认初始值: null
接着执行 Person p2 = new Person();
代码创建第二个 Person 对象.
此时因为 Person 类已经存在于堆内存了.
所以不需要对 Person 类进行初始化(废话…Java 会那么傻么…)
创建第二个 Person 对象 与 创建第一个 Person 对象并没有什么不同.
当程序执行 p1.name = “孙悟空”; 时
将为 p1 的 name 实例变量赋值.
也就是让堆内存中的 name 指向 “孙悟空” 字符串.
我们之前说过, 字符串也是一种引用变量. 所以你懂的.
执行完成后, 两个 Person 对象在内存中的存储示意图如下:
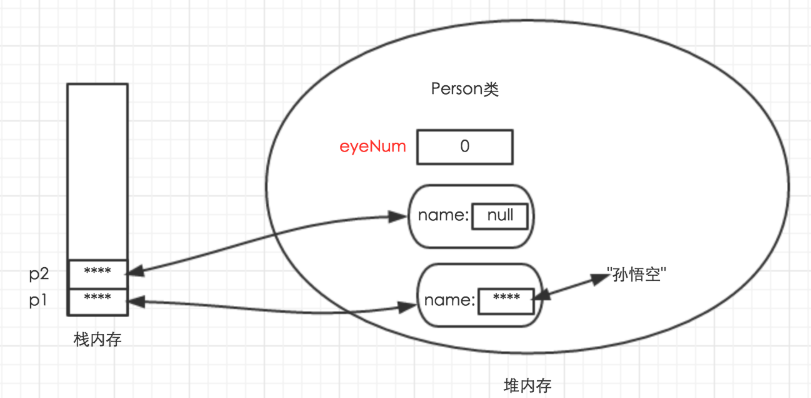
从上图可以看出, name 实例变量是属于单个 Person 实例的.
因此, 修改第一个 Person 对象的 name 实例变量时仅仅与 p1 对象有关.
与 Person 类和其它 Person 对象没有任何关联.
同理, 修改第二个 Person 对象 p2 的 name 实例变量时, 也与 Person 类和其它 Person 对象无关.
直到执行 p1.eyeNum = 2 时
此时呢, 就是犯大忌了. 你拿 对象来操作类变量了. 不过为了教学演示, 我拿自己当典型.
从我们看过的图当中, 可以知道.
Person 的对象根本没有保存 eyeNum 这个变量.
通过 p1 访问的 eyeNum 类变量.
其实还是 Person 类的 eyeNum 类变量.
因此, 此时修改的是 Person 类的 eyeNum 类变量.
修改成功后, 内存中的存储示意图如下:
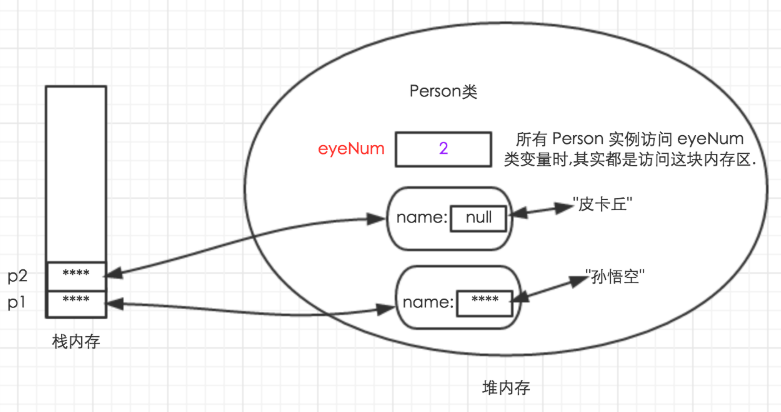
从上图可以看出.
不管通过哪个 Person 实例来访问 eyeNum 类变量.
它们访问的其实都是同一块内存.
所以就再次提醒你.
当程序需要访问 类变量时.
尽量使用类作为主调, 而不要使用对象作为主调.
这样可以避免歧义, 提高程序的可读性.
局部变量的初始化和内存中的运行机制
局部变量定义后.
必需经过显式初始化后才能使用.
系统不会为局部变量执行初始化.
这意味着,定义局部变量之后,系统并未为这个变量分配内存控件.
直到等程序为这个变量赋初始值时.
系统才会为局部变量分配内存,并将初始值保存到这块内存中去.
与成员变量不同,局部变量不属于任何类或实例.
因此它总是保存在其所在的方法的栈内存中.
如果局部变量是基本类型变量,则直接把这个变量的值保存在该变量对应的内存中.
如果局部变量是引用类型的变量,则这个变量里存放的就是地址.
通过该地址引用到该变量实际引用的对象或数组.
变量的使用规则
对于新手来说.
什么时候使用类变量?
什么时候使用实例变量?
什么时候使用方法局部变量?
什么时候使用代码块局部变量?
这种选择比较困难,如果仅仅从程序的运行结果来看,大部分时候都可以直接使用类变量或实例变量来解决问题.无须使用局部变量.
但实际上这种做法非常错误.
因为定义一个成员变量时,成员变量将被放置到堆内存中.
成员变量的作用域将扩大到类存在范围或对象存在范围,这种返回的扩大有两个害处.
小结类与对象
-
类与对象
- 类是一个模板:抽象,对象是一个具体的实例。
-
方法
- 定义:是通用的
-
对象的引用
-
引用类型:8个基本数据类型
-
对象时通过引用来操作的
-
-
属性:字段Field的成员变量
-
默认初始化:
-
数字:0 0.0
-
char u0000
-
boolean:false
-
引用:null
-
-
修饰符 属性类型 属性名 =属性值
-
-
对象的创建和使用
-
必须使用new关键字来创建对象,构造器Person person = new Person ();
-
对象的属性 :person.name
-
对象的方法 : person.walk();
-
-
类
- 静态的属性是属性
-
动态的行为是方法
构造器
-
构造器的特征 :
-
它具有与类相同的名称
-
它不声明返回值类型(跟声明void不同)
-
不能被static ,final , abstract ,native 修饰 ,不能有return语句返回值
-
-
构造器的作用 :创建对象,给对象进行初始化
-
Order o = new Order**()****; Person p = new Person(peter,15);**
构造器:
- 语法格式:
修饰符 类名 (参数列表)****{
初始化语句;
}
-
根据参数不同,构造器可以分为以下两个种类:
-
隐式无参构造器(系统默认)
-
显示定义一个或多个(无参,有参)
注意 :
-
Java语言中,每个类至少有一个构造器。
-
默认构造器的修饰符和所属类的修饰符相同。
-
一旦显示定义了构造器 ,系统则不会提供默认的构造器。
-
一个类可以创造多个重载的构造器。
-
父类的构造器不可以被子类继承。
5、构造方法。
5.1、当一个类中没有提供任何构造方法,系统默认提供一个无参数的构造方法。
这个无参数的构造方法叫做缺省构造器。5.2、当一个类中手动的提供了构造方法,那么系统将不再默认提供无参数构造方法。 建议将无参数构造方法手动的写出来,这样一定不会出问题。5.3、无参数构造方法和有参数的构造方法都可以调用。Student x = new Student();Student y = new Student(123);5.4、构造方法支持方法重载吗?构造方法是支持方法重载的。在一个类当中构造方法可以有多个。并且所有的构造方法名字都是一样的。方法重载特点:在同一个类中,方法名相同,参数列表不同。5.5、对于实例变量来说,只要你在构造方法中没有手动给它赋值, 统一都会默认赋值。默认赋系统值。
封装
有了封装,才有继承,有了继承,才能说多态。1. 面向对象的首要特征:封装 。什么是封装?有什么用?现实生活中有很多现实的例子都是封装的,例如:手机,电视机,笔记本电脑,照相机,这些都是外部有一个坚硬的壳儿。封装起来,保护内部的部件。保证内部的部件是安全的。另外封装了之后,对于我们使用者来说,我们是看不见内部的复杂结构的,我们也不需要关心内部有多么复杂,我们只需要操作外部壳儿上的几个按钮就可以完成操作。那么封装,你觉得有什么用呢?封装的作用有两个:第一个作用:保证内部结构的安全。第二个作用:屏蔽复杂,暴露简单。在代码级别上,封装有什么用?一个类体当中的数据,假设封装之后,对于代码的调用人员来说,不需要关心代码的复杂实现,只需要通过一个简单的入口就可以访问了。另外,类体中安全级别较高的数据封装起来,外部人员不能随意访问,来保证数据的安全性。2.怎么进行封装,代码怎么实现?第一步:属性私有化(使用private关键字进行修饰。)第二步:对外提供简单的操作入口。(提供set/get方法)
-
该露的露,该藏的藏
- 我们程序设计要追求“高内聚,低耦合”。高内聚就是类的内部数据细节由自己完成,不允许外部干涉;低耦合:仅暴露少量的方法给外部使用。
-
封装 (数据的隐藏)
- 通常,应禁止直接访问一个对象的实际表示,而应该通过操作来访问,这就是数据的隐藏,简称信息隐藏。
-
应属于私有的,get/set
//名字private String name;//学号private int id;//性别private char sex;//年龄private int age;public int getAge() {if (age>120 || age<0){this.age=3;}else{this.age=age;}return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public char getSex() {return sex;}public void setSex(char sex) {this.sex = sex;} Students s1 = new Students(); s1.setAge(1200); System.out.println(s1.getAge());- 作用
1. 提高程序的安全性,保护数据
2. 隐藏代码的实现细节
3. 统一接口
4. 系统可维护性增强了
静态代码块
静态代码块:执行优先级高于非静态的初始化块,它会在类初始化的时候执行一次,执行完成便销毁,它仅能初始化类变量,即
static修饰的数据成员。
静态代码块在类加载时执行
静态代码块语法:
static{
java语法;
java语法;
}
对应的扩展下非静态代码块
总结
到目前为止:你所遇到的有顺序要求的java程序有哪些?
- 对于一个方法来说,方法体中的代码的是有顺序的,是遵循自上而下的顺序。
- 静态代码块1和静态代码块2是有先后顺序的。
- 静态代码块和静态变量是有先后顺序的。
4. 只要是构造方法执行,实例语句块必定会在构造方法之前执行。
this关键字
this
- this是一个关键字,是一个引用,保存内存地址指向自身。
- this可以使用在实例方法中,也可以使用在构造方法中。
- this出现在实例方法中其实代表的是当前对象。
- this不能使用在静态方法中。
- this. 大部分情况下可以省略,但是用来区分局部变量和实例变量的时候不能省略。
- this() 这种语法只能出现在构造方法第一行,表示当前构造方法调用本类其他的构造方法,目的是代码复用。
作用
this.属性名称
指的是访问类中的成员变量,用来区分成员变量和局部变量(重名问题)
下面我写了一个关于this的例子,大家看一下:
package com.manman.base;/*** @author 满满* createDate 2022/2/17 16:00*/
public class Person {public static void main(String[] args) {Food f1 = new Food("Java基础",345);System.out.println(f1.getPageNum());f1.detail();Food f2 = new Food();}
}
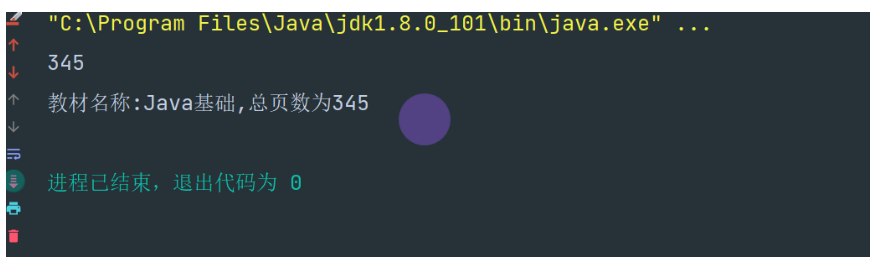
class Food{/*** 封装 进行属性私有化*/private String title;private int pageNum;//定义无参构造public Food() {title = "未知";pageNum = 200;}public Food(String title, int pageNum) {this.title = title;if (pageNum < 200) {System.out.println("本书最少为200页,若不符合,则赋默认值200!");} else {this.pageNum = pageNum;}}//定义getter and setter 方法public String getTitle() {return title;}public void setTitle(String title) {if (pageNum < 200) {System.out.println("本书最少为200页,若不符合,则赋默认值200!");} else {this.pageNum = pageNum;}this.title = title;}public int getPageNum() {return pageNum;}public void setPageNum(int pageNum) {this.pageNum = pageNum;}public void detail(){System.out.println("教材名称:" + title + ",总页数为" + pageNum);}}
运行结果如下:
this.方法名称
用来访问本类的成员方法
this(); 访问本类的构造方法()中可以有参数的 如果有参数 就是调用指定的有参构造注意事项:1.this() 不能使用在普通方法中 只能写在构造方法中2.必须是构造方法中的第一条语句
继承
-
继承的本质是对某一批类的抽象,从而实现对美好的世界的构建
-
extends的意思是“扩展”。子类是父类的扩展,使用extends来表示
-
Java中只有单继承,没有多继承,一个类只能继承一个父类
-
继承是类与类之间的关系,此外还有依赖,组合,聚合等等。
-
继承关系的两个类,一个是子类(派生类),一个是父类(基类),子类继承父类
-
在Java中,所有的类,都默认直接或间接继承Object类(Ctrl + H 可以查看类关系)
-
被final修饰的类,无法被继承(俗称断子绝孙)
继承的特点
Java的继承通过extends关键字实现.
实现继承的类被称为子类.
被继承的类被称为父类.
父类和子类的关系, 是一种一般和特殊的关系.
例如水果和苹果的关系, 苹果继承了水果, 苹果是水果的子类, 水果是苹果的父类.Java里子类继承父类的语法格式如下:
修饰符 class SubClass extends SuperClass
{//类定义部分
}
从上面的语法格式来看, 定义子类的语法非常简单, 只需要在原来的类定义上增加 extends SuperClass 即可.
即表明该类是 SuperClass 的子类.为什么国内把 extends 翻译为 继承 而不是 扩展呢?
除了历史原因, 还有一点.
子类继承了父类, 也将获得父类的全部成员变量和方法.
这与我们现实中子辈从父辈那里获得一笔财富的继承关系很像.
但是, Java的子类不能继承父类的构造器.
下面写个程序示范子类继承父类
public class Fruit
{public double weight;public void info(){System.out.println("我是一个水果! 重:" + weight + "g!");}
}
接下来定义该Fruit类的子类Apple
public class Apple extends Fruit
{public static void main(String[] args){//创建Apple对象Apple a = new Apple();//Apple 对象本身没有 weight 成员变量//因为Apple 父类有 weight 成员变量, 所以也可以访问 Apple 对象的 weight 成员变量.a.weight = 56;//调用 Apple 对象的 info() 方法a.info();}
}
上面的 Apple 类只是一个空类, 它只包含了一个 main() 方法.
但程序中创建了 Apple 对象之后, 可以访问该 Apple 对象的 weight 实例变量和info()方法, 这表明 Apple 对象也具有了 weight 实例变量和 info() 方法, 这就是继承的作用.
Java类虽然只能有一个直接父类, 但它可以有无限多个间接父类.
例如:
class Fruit extends Plant{...}
class Apple extends Fruit{...}
......
上面类定义中, Fruit 是 Apple 类的父类.
Plant 类也是 Apple 类的父类.
区别是 Fruit 是 Apple 的直接父类, 而 Plant 则是 Apple 类的间接父类.如果定义一个 Java类时, 并未显式指定这个类的直接父类.
则这个类默认继承 java.lang.Object 类.
因此可以得出, java.lang.Object 类时所有类的父类.
要么是直接父类, 要么是其间接父类.
因此, 所有的Java对象都可以调用 java.lang.Object 类所定义的实例方法.
方法的重写
子类继承了父类, 所以说子类是一个特殊的父类.
大部分时候, 子类总是以父类为基础.
额外增加新的成员变量和方法.
但有一种情况例外: 子类需要重写父类的方法.
例如鸟类都包含了飞翔的方法, 但其中的鸵鸟并不会飞, 因为鸵鸟是鸟的子类, 因此它将从鸟类中获得飞翔的方法, 但这个飞翔的方法显然不适合鸵鸟, 所以鸵鸟这个子类需要重写鸟类(父类)的方法.
下面先定义一个 Bird 类
public class Bird
{//Bird 类的 fly() 方法public void fly(){System.out.println("我在天空自由自在的飞翔...啦啦啦");}
}
下面定义一个 Ostrich 类, 这个类继承了 Bird 类, 同时重写 Bird 类的 fly() 方法.
public class Ostrich
{//重写 Bird 类的 fly() 方法public void fly(){System.out.println("NND, 我可飞不了, 虽然我有双翅膀, 啦啦啦");}public static void main(String[] args){//创建 Ostrich 对象Ostrich os = new Ostrich();//执行 Ostrich 对象的 fly() 方法, 将会输出 "...飞不了..."os.fly();}
}
执行上面的程序, 将看到执行 os.fly() 时执行的不是 Bird 类的 fly() 方法.
而是执行 Ostrich 类的 fly() 方法.这种子类包含与父类同名方法的现象称为方法重写(Override). 也被称为方法覆盖.
可以说子类重写了父类的方法, 也可以说子类覆盖了父类的方法, 都行.方法的重写要遵循两同两小一大规则.
- 两同: 方法名相同 / 形参列表相同
- 两小: 子类方法返回值类型应比父类方法返回值类型小或相等. / 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等.
- 一大: 子类方法的访问权限应比父类方法的访问权限大或相等.
尤其需要指出, 覆盖方法和被覆盖方法要么都是类方法, 要么都是实例方法.
不能一个是类方法, 一个是实例方法, 例如下面代码就会报错.
class BaseClass
{public static void test(){...}
}
class SubClass extends BaseClass
{public void test(){...}
}
当子类覆盖了父类方法后, 子类的对象将无法访问父类中被覆盖的方法.
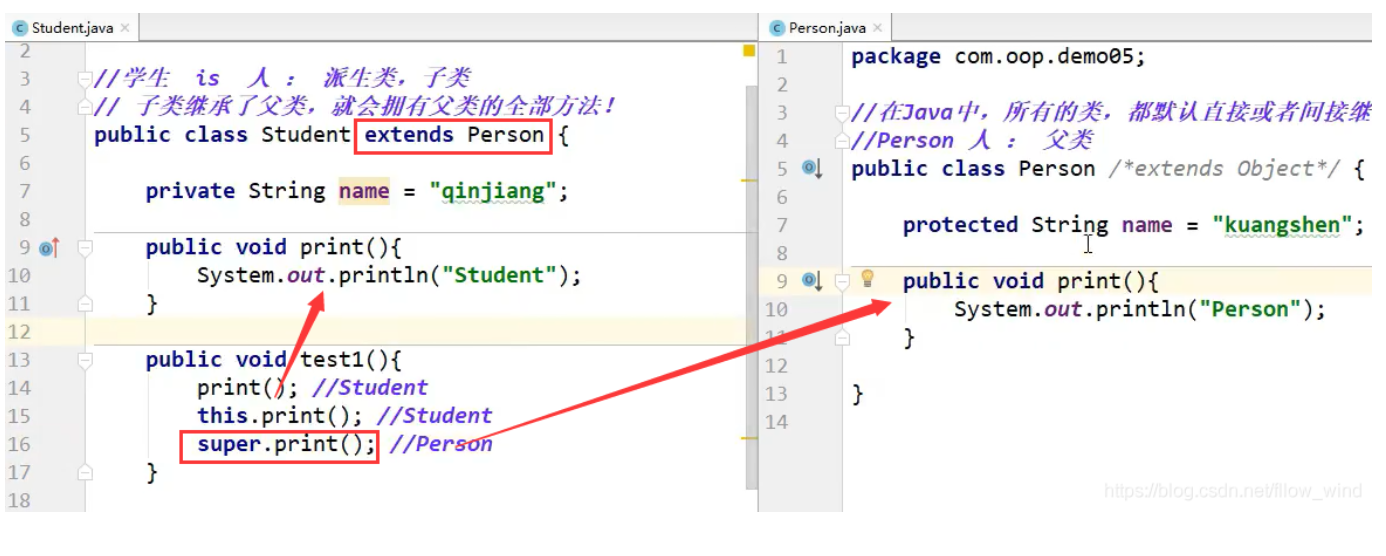
但可以在子类方法中调用父类中被覆盖的方法.
如果需要在子类方法中调用父类中被覆盖的方法, 则可以使用super(被覆盖的是实例方法) 或者 父类类名(被覆盖的是类方法) 来作为调用者, 调用父类中被覆盖的方法.
如果父类方法具有 private 访问权限, 则该方法对其子类是隐藏的.
因此子类无法访问该方法, 也就无法重写该方法.
如果子类中定义了一个与父类 private 方法具有相同的方法名 / 相同的形参列表 / 相同的返回值类型的方法, 依然不是重写.
这只是在子类中重新定义了一个新的方法.
例如下面代码时完全正确的。
class BaseClass
{//test() 方法是 private 访问权限, 子类不可访问该方法private void test(){...}
}
class SubClass extends BaseClass
{//此处并不是方法重写, 所以可以增加 static 关键字public static void test(){...}
}
涨姿势:
方法重载和方法重写在英文中分别是 overload 和 override
重载和重写 并不是同一种东西, 虽然二者都是发生在方法之间, 并要求方法名相同之外, 并没有太大相似之处.
因为重载主要发生在同一个类的多个同名方法之间.
而重写发生在子类和父类的同名方法之间.
当然, 父类方法和子类方法之间也有可能发生重载, 因为子类会获得父类方法.
如果子类定义了一个与父类方法有相同方法名, 但参数列表不同的方法, 就会形成父类方法和子类方法的重载.
继承中方法的重写的细节
-
子类的方法必须与父类的方法一致,方法体不同。
-
参数列表必须相同
-
修饰符可以扩大,但是不可以缩小
- public > protected >default >private
-
抛出的异常范围可以缩小,但是不能扩大 : ClassNotFoundException–>Exception(大)
-
重写是方法的重写,与属性无关
-
重写方法只与非静态方法有关,与静态方法无关(静态方法不能被重写)
-
被 **static(属于类 ,不属于实例),final(常量方法),private(私有的)**修饰的方法不能被重写
public class B {public static void test(){ //静态方法System.out.println("B==>test()");}
}public class A extends B{ //继承public static void test(){System.out.println("A==>test()");}
}public class Application {public static void main(String[] args) {//方法的调用之和左边定义的类型有关A a = new A();a.test(); //打印 A==>test()//父类的引用指向了子类,但静态方法没有被重写B b = new A();b.test(); //打印 B==>test()}
}public class B { public void test(){//非静态方法 System.out.println("B==>test()");
}}
public class A extends B{ @Override //重写了B的方法 public void test() { System.out.println("A==>test()"); }
}//父类的引用指向了子类B b = new A();
//子类重写了父类的方法,执行子类的方法b.test();
//打印变成了
A==>test()/* 静态方法是类的方法,非静态方法是对象的方法有static时,b调用了B类的方法,因为b是b类定义的没有static时,b调用的是对象的方法,而b是A类new出来的对象,调用A的方法*/重写:子类的方法必须跟父类保持一致 :方法体不同
被**static(属于类,不属于实例),final(常量方法),private(私有)**修饰的方法不能重写
为什么重写?
重写:子类继承父类以后,可以对父类中同名同参数的方法进行覆盖操作。
应用:重写以后,当创建子类对象以后,通过子类对象调用父类中同名同参数的方法时,实际上执行的是子类重写父类的方法。
面试题目 :如何区分方法的重写跟重载 ?
方法重载:
在同一个类中
方法名相同,但是行参列表不同
方法的返回值,访问修饰符任意
与方法参数名无关
方法的重写:
有继承关系的子类中
方法名相同,参数列表相同(参数顺序,类型,个数),方法的返回值要相同
访问修饰符,访问范围子类需要大于父类的访问范围
与方法的参数名无关
方法重写的更多理解(override/overwrite)
方法重写 :子类继承父类以后,可以对父类同名同参数的方法进,行覆盖操作
应用: 重写以后,当创建子类对象时,通过子类对象调用父类同名同参数的方法时,实际执行的是子类重写父类的方法
重写的规定 :
权限修饰符 返回值类型 类名(行参列表 )throws 异常的类型{
//方法体
}
约定俗称:子类中叫重写的方法,父类中叫被重写的方法。
①子类重写的方法名和行参列表和父类被重写的方法名和行参列表相同。
②子类重写的方法的权限修饰符不小于父类被重写的方法的权限修饰符。
子类不能重写父类中声明为private的权限的方法。
③返回值类型:
父类被重写的方法的返回值是void,则子类中重写的方法的返回值也是void。
父类被重写的方法的返回值是A类型,则子类中重写的方法的返回值类型是A类型或者是A类的子类。
父类被重写的方法的返回值是基本数据类型(比如double),则子类重写的方法的返回值必须是相同的。
④子类重写的方法抛出的异常类型不大于父类被重写的方法抛出的异常。(具体细节在异常处理)
⑤子类和父类中同名同参数的方法要么都声明为非static(考虑重写),要么都声明为static(不考虑重写)
多态
-
即同一方法可以根据发送对象的不同而采用不同的行为方式
-
一个对象的实际类型是确定的,但可以指向对象的引用可以有很多
-
多态存在条件
- 有继承关系
- 子类重写父类方法
- 父类引用指向子类对象
注意点:
- 多态是方法的多态,没有属性的多态
- 父类和子类,有联系 类型转换异常: ClassCastException
- 存在条件:继承关系,方法需要重写,父类引用指向子类对象!
instanceof和类型转换
- instanceof 引用类型比较,判断一个对象是什么类型
Object object = new Student(); System.out.println(object instanceof Student); System.out.println(object instanceof Person); System.out.println(object instanceof Object); System.out.println(object instanceof Teacher); System.out.println(object instanceof String); System.out.println("======================"); Person person = new Student(); System.out.println(person instanceof Student); System.out.println(person instanceof Person); System.out.println(person instanceof Object); System.out.println(person instanceof Teacher);// System.out.println(person instanceof String); System.out.println("======================="); Student student = new Student(); System.out.println(student instanceof Student); System.out.println(student instanceof Person); System.out.println(student instanceof Object);// System.out.println(student instanceof Teacher);// System.out.println(student instanceof String);,- 类型转换
- 父类引用指向子类的对象
- 把子类转换为父类,向上转型,会丢失自己原来的一些方法
- 把父类转换为子类,向下转型,强制转换,才调用子类方法
- 方便方法的调用(转型),减少重复的代码,简洁
多态性:
-
理解多态性:可以理解为一种事物的多种形态
-
何为多态性:
-
对象的多态性:父类的引用指向子类的对象(或者子类的对象赋给父类的引用)
-
-
多态的使用:
-
有了多态的使用以后,我们在编译器只能调用父类声明的方法,但是在运行期,我们实际执行的是子类的重写父类的方法
-
-
分析 s. move();
-
java程序分为编译阶段 和 运行阶段
-
首先来分析编译阶段:
- 对于编译器来说,编译器只知道s的类型是Animal,所以编译器在检查语法的时候,会去Animal.class字节码文件中找move()方法,找到的话,就进行绑定move(),此时编译通过,静态绑定成功。(编译阶段属于静态绑定阶段)
2.继续分析运行阶段:
-
-
-
- 运行阶段的时候 ,实际上在堆内存创建的 java对象 是Cat对象,所以在move()的时候, 实际上真正参与move()对象的是一只猫 ,所以运行阶段会动态执行Cat对象的move()方法 .(运行阶段属于动态绑定)
- 但是运行的时候和底层堆存中的实际对象有关 ,真正执行的时候会调用真实对象的相关方法 .
-
总结:编译,看左边。执行(运行),看右边。
-
对象的多态性:只适用于方法,不适用于属性。
-
多态性的使用前提:①类的继承关系 ② 方法的重写
-
instanceof 关键字的使用:
-
- a instanceof A :判断对象a 是否为A类的实例,如果是,则返回true,如果不是,则返回false
- 使用情景:为了避免在向下转型时出现ClassCastException的异常,所以我们在向下转型之前,我们进行instanceof的判断,一旦返回true,就立即向下转型,如果返回false,就停止向下转型。
- 如果a instanceof A 返回true, 则 a instanaceof B也会返回true。
练习注意:
- 若子类重写了父类的方法,则就意味着子类定义的方法彻底覆盖了父类里同名同参数的方法,系统将不可能把父类里面的方法转移到子类中
- 对于实例变量则不存在这样的现象,即使子类里定义了与父类完全相同的实例变量,这个实例变量依然不可能覆盖父类中定义的实例变量:即编译看左边,运行看右边。
有了对象的多态性以后,内存实际上加载了子类特有的属性和方法。但是由于变量声明为父亲类型
导致了编译时,只能调用父类中声明的属性和方法,。子类特有的属性和方法就不能调用。
如何才能调用子类中的属性和方法?*
向下转型:使用强制类型转化,缺点:会有精度的损失
super限定
如果需要在子类方法中调用父类被覆盖的实例方法.
则可以使用 super 限定来调用父类被覆盖的实例方法.
为上面的 Ostrich 类添加一个方法, 在这个方法中调用 Bird 类中被覆盖的 fly 方法.
public void callOverrideMethod()
{//在子类方法中通过 super 显式调用父类被覆盖的实例方法super.fly();
}
super 是 Java提供的一个关键字, super 用于限定该对象调用它从父类继承得到的实例变量或方法.
正如 this 不能出现在 static 修饰的方法中一样, super 也不能出现在 static 修饰的方法中.
static 修饰的方法是属于类的.
该方法的调用者可能是一个类, 而不是对象, 因而 super 限定也就失去了意义.
如果在构造器中使用 super
则 super 用于限定该构造器初始化的是该对象从父类继承得到的实例变量, 而不是该类自己定义的实例变量.
如果子类定义了和父类同名的实例变量.
则会发生子类实例变量隐藏父类实例变量的情形.
在正常情况下, 子类里定义的方法直接访问该实例变量默认会访问到子类中定义的实例变量.
无法访问到父类中被隐藏的实例变量.
在子类定义的实例方法中可以通过 super 来访问父类中被隐藏的实例变量.
如下代码所示:
class BaseClass
{public int a = 5;
}
public class SubClass extends BaseClass
{public int a = 7;public void accessOwner(){System.out.println(a);}public void accessBase(){//通过使用 super 来限定访问从父类继承得到的 a 的实例变量System.out.println(super.a);}public static void main(String[] args){SubClass sc = new SubClass();sc.accessOwner(); //输出 7sc.accessBase(); //输出 5}
}
上面程序的 BaseClass 和 SubClass 中都定义了名为 a 的实例变量.
则 SubClass 的 a 实例变量将会隐藏BaseClass 的 a 实例变量.
当系统创建了 SubClass 对象时, 实际上会为 SubClass 对象分配两块内存.
如果子类里没有包含和父类同名的成员变量.
那么在子类实例方法中访问该成员变量时, 则无需显式使用 super 或 父类名作为调用者.
如果在某个方法中访问名为 a 的成员变量, 但没有显式指定调用者, 则系统查找 a 的顺序为:
- 查找该方法是否有名为a的局部变量。
- 查找当前;类是否包含名为a的成员变量。
- 查找a的直接父类是否含有名为a的成员变量, 依次上溯 a 的所有父类. 直到 java.lang.Object 类.
- 如果最终不能找到名为 a 的成员变量, 则系统出现编译错误.
如果被覆盖的是类变量, 在子类的方法中则可以通过父类名作为调用者来访问被覆盖的类变量.
涨姿势:
当程序创建一个子类对象时.
系统不仅会为该类中定义的实例变量分配内存.
也会为它从父类继承得到的所有实例变量分配内存.
即使子类定义了与父类中同名的实例变量.
也就是说, 当系统创建一个 java 对象时.
如果该 java 类有两个父类(一个直接父类 A / 一个间接父类 B)
假设 A 类中定义了 2 个实例变量, B 类中定义了 3 个实例变量.
当前类中定义了 2 个实例变量, 那么这个 java 对象会保存 2 + 3 + 2 个实例变量.
因为子类中定义与父类中同名的实例变量并不会完全覆盖父类中定义的实例变量, 它只是简单的隐藏了父类中实例变量, 所以会出现如下特殊情况:
class Parent
{public String tag = "孙悟空";
}
class Derived extends Parent
{//定义一个私有的 tag 实例变量来隐藏父类的 tag 实例变量private String tag = "猪八戒";
}
public class HideTest
{public static void main(String[] args){Derived d = new Derived();//程序不可访问 d 的私有变量 tag , 所以下面语句将引起编译错误//System.out.println(d.tag);//将 d 变量显式的向上转型为 Parent 后, 即可访问 tag 实例变量//程序将输出 孙悟空System.out.println(((Parent)d).tag);}
}
上面程序父类 Parent 定义了一个 tag 实例变量.
其子类 Derived 定义了一个 private 的 tag 实例变量.
子类中定义的这个实例变量将会隐藏父类中定义的 tag 实例变量.
程序的入口 main() 方法中先创建了一个 Derived 对象.
这个 Derived 对象将会保存两个 tag 实例变量.
一个是在 Parent 中定义的 tag 实例变量.
一个是在 Derived 类中定义的 tag 实例变量.
此时程序中包括了一个 d 变量.
它引用一个 Derived 对象, 内存中的存储示意图如下:
接着, 程序将 Derived 对象赋给 d 变量.
接着, 程序试图通过 d 来访问 tag 实例变量, 程序将提示访问权限不允许.
接着, 将 d 变量强制向上转型为 Parent 类型.
再通过它来访问 tag 实例变量是允许的.
调用父类构造器
子类不会获得父类的构造器。
但子类构造器里可以调用父类构造器的初始化代码。
类似于前面介绍的一个构造器可以调用另一个重载构造器。
在一个构造器中调用另一个重载的构造器使用this来调用完成。
在子类构造器中调用父类构造器使用super调用来完成。
看下面程序定义了 Base 类 和 Sub 类, 其中 Sub 类是 Base 类的子类.
程序在 Sub 类的构造器中使用 super 来调用 Base 类的构造器初始化代码.
class Base
{public double size;public String name;public Base(double size, String name){this.size = size;this.name = name;}
}
public class Sub extends Base
{public String color;public Sub(double size, String name, String color){//通过 super 调用来调用父类构造器的初始化过程super(size, name);this.color = color;}public static void main(String[] args){Sub s = new Sub(5.6, "皮卡丘", "黄色");//输出 Sub 对象的 三个实例变量System.out.println(s.size + "--" + s.name + "--" + s.color);}
}
从上面程序中不难看出, 使用 super 调用和使用 this 调用也很像.
区别在于 super 调用的是其父类的构造器, 而 this 调用的是同一个类中重载的构造器.
因此, 使用 super 调用父类构造器也必需出现在子类构造器执行体的第一行.
所以 this 调用 和 super 调用不会同时出现.
不管是否使用 super 调用来执行父类构造器的初始化代码.
子类构造器总会调用父类构造器一次.
子类构造器调用父类构造器分如下几种情况:
- 子类构造器执行体的第一行使用 super 显式调用父类构造器.系统将根据 super 调用里传入的实参列表调用父类对应的构造器.
- 子类构造器执行体的第一行代码使用 this 显式调用本类中重载的构造器,系统将根据 this 调用里传入的实参列表调用本类中的另一个构造器.执行本类中另一个构造器时即会调用父类构造器.
- 子类构造器执行体中既没有 super 调用, 也没有 this 调用, 系统将会在执行子类构造器之前, 隐式调用父类无参数的构造器.
不管上面哪种情况, 当调用子类构造器来初始化子类对象时.
父类构造器总会在子类构造器之前执行:
不仅如此, 执行父类构造器时, 系统会再次上溯执行其父类构造器……以此类推.
创建任何 Java对象, 最先执行的总是 java.lang.Object 类的构造器.
对于如下图所示的继承树.
如果创建 ClassB 的对象, 系统将先执行 java.lang.Object 类的构造器.
再执行 ClassA 类的构造器.
然后才执行 ClassB 类的构造器.
这个执行过程还是最基本的情况.
如果 ClassB 显式调用 ClassA 的构造器, 而该构造器又调用了 ClassA 类中重载的构造器, 则会看到 ClassA 两个构造器先后执行的情形.
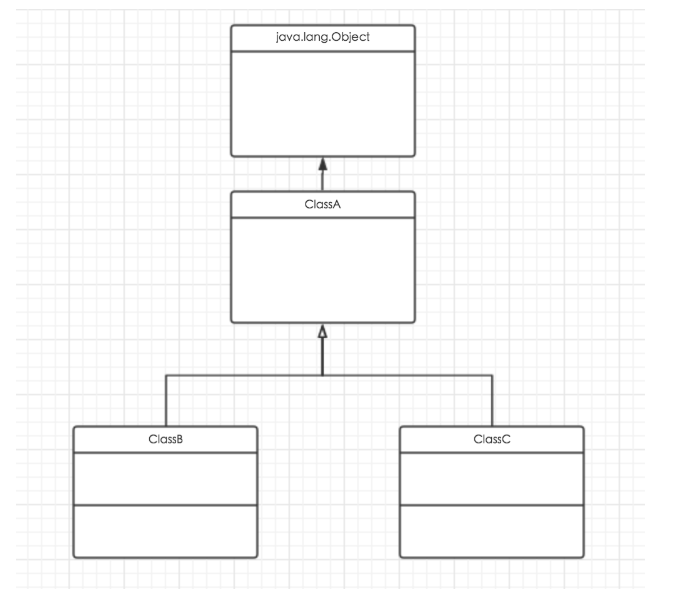
下面程序定义了三个类, 它们之间有严格的继承关系.
通过这种继承关系来让你看看构造器之间的调用关系.
class Creature
{public Creature(){System.out.println("Creature 无参数的构造器");}
}class Animal extends Creature
{public Animal(String name){System.out.println("Animal 带一个参数的构造器," + "该动物的 name 为:" + name);}public Animal(String name, int age){//使用 this 调用同一个重载的构造器this(name);System.out.println("Animal 带两个参数的构造器," + "其 age 为:" + age);}
}public class Wolf extends Animal
{public Wolf(){//显式调用父类有两个参数的构造器super("大灰狼", 3);System.out.println("Wolf 无参数的构造器");}public static void main(String[] args){new Wolf();}
}
上面程序的 main 方法只创建了一个 Wolf 对象.
但系统在底层完成了复杂的操作.
运行上面的程序, 看到如下运行结果:
Creature 无参数的构造器
Animal 带一个参数的构造器, 该动物的 name 为大灰狼
Animal 带两个参数的构造器, 其 age 为 3
Wolf 无参数的构造器
从上面的运行过程来看.
创建任何对象总是从该类所在继承树最顶层的类的构造器开始执行.
然后依次向下执行.
最后才执行本类的构造器.
如果某个父类通过 this 调用了 同类中重载的构造器.
就会依次执行此父类的多个构造器
super&this
super注意点:
-
super调用父类的构造方法,必须在构造方法的第一个
-
super必须只能出现在子类的方法或者构造方法中
-
super和this不能通知调用构造方法
-
我们可以在子类的方法或构造器中。通过使用“super.属性”或”super.方法“,显示的调用父类中的属性和方法,但是在通常情况下,通常省略“super"关键字。
-
特殊情况下,当子类或父类中定义了同名的属性时,我们想要在子类中调用父类声明的属性,则必须显示的使用“super.属性”的方式,表明调用的是父类中声明的属性
-
特殊情况,当子类重写了父类的方法以后,我们想要在子类中调用父类被重写的方法时,则必须显示的使用”super.方法“的方式,表明调用的是父类中的方法。
VS this:
-
代表的对象不同
-
this : 本身调用者这个对象
-
super :只能在继承条件下可以试用
-
-
构造方法
-
this() :本类的构造
-
super():父类的构造
-
我们可以在子类的构造器中显示的适用”super.(行参列表)“的方式,调用父类中声明的指定构造器
-
”super.(行参列表)“的使用,必须声明在子类构造器的首行!
-
我们在类的构造器中,针对”this.(行参列表)“或”super.(行参列表)“只能二选一。
-
在构造器的首行,没有显示的声明”this.(行参列表)“或”super.(行参列表)“,则默认的调用的是父类中的空参的构造器。
-
super 不是引用 ,super也不保存内存地址 ,super也不指向任何对象
-
super只是代表当前对象内部的那一块父类的特征.
-
-
super与this的区别 :super代表父类对象的引用,只能继承条件下使用,this调用自身的对象,没有继承关系也可以使用
super(); //隐藏代码,默认调用了父类的无参构造,要写只能写第一行
小结:方法的重载和重写
-
从编译和运行的角度来讲:
-
- 重载,是允许多个同名的方法,而这些方法的参数不同,编译器根据方法不同的参数表,对同名方法的名称进行修饰。对于编译器而言,这些同名的方法就成了不同的方法。他们的调用地址在编译期就绑定了。Java的重载是可以包括父类和子类的,即子类可以重载父类同名不同参数的方法。
- 所以对于重载而言,在方法调用之前,就已经确定了所要调用的方法,这称为“早绑定”或”静态绑定“
- 而对于多态,只有等到方法调用的那一刻,编译器才会确定所调用的具体方法,这称为“晚绑定”或“动态绑定”
- “不要犯傻,只要确定他是不是晚绑定,那他就不是多态!”
拓展知识
JavaBean
-
所谓的JavaBean,就是指符合如下的Java类:
-
类是公共的
-
有一个无参的构造器
-
有属性,且有相应的set,get方法。
-
用户可以使用JavaBean将功能,处理,数据库访问和其他任何可以用Java代码创造的对象进行打包,并且其他的开发者可以通过内部的JSP页面,Servlet其他JavaBean程序或者应用来使用这些对象。用户可以认为JavaBean提供了一种随时随地的复制和粘贴的功能,而不用关心任何变化。
面向对象阶段其他细节问题
什么时候变量声明为实例的,什么时候变量声明为静态的?
如果这个类型的所有对象的属性值都是一样的,不建议定义为实例变量,浪费内存空间. 建议定义为类级别特征 ,定义为静态变量 ,在方法区中只保留一份,节省内存开销.
一个对象一份的是实例变量
所有对象一份的是静态变量
8、Java进阶
final使用
final变量
final变量有成员变量或者是本地变量(方法内的局部变量),在类成员中final经常和static一起使用,作为类常量使用。其中类常量必须在声明时初始化,final成员常量可以在构造函数初始化。
public class Main {public static final int i; //报错,必须初始化 因为常量在常量池中就存在了,调用时不需要类的初始化,所以必须在声明时初始化public static final int j;Main() {i = 2;j = 3;}
}
就如上所说的,对于类常量,JVM会缓存在常量池中,在读取该变量时不会加载这个类。
public class Main {public static final int i = 2;Main() {System.out.println("调用构造函数"); // 该方法不会调用}public static void main(String[] args) {System.out.println(Main.i);}
}
final修饰基本数据类型变量和引用
@Test
public void final修饰基本类型变量和引用() {final int a = 1;final int[] b = {1};final int[] c = {1};
// b = c;报错b[0] = 1;final String aa = "a";final Fi f = new Fi();//aa = "b";报错// f = null;//报错f.a = 1;
}
final方法表示该方法不能被子类的方法重写,将方法声明为final,在编译的时候就已经静态绑定了,不需要在运行时动态绑定。final方法调用时使用的是invokespecial指令。
class PersonalLoan{public final String getName(){return"personal loan”;}
}class CheapPersonalLoan extends PersonalLoan{@Overridepublic final String getName(){return"cheap personal loan";//编译错误,无法被重载}public String test() {return getName(); //可以调用,因为是public方法}
}
final类
final类不能被继承,final类中的方法默认也会是final类型的,java中的String类和Integer类都是final类型的。
class Si{//一般情况下final修饰的变量一定要被初始化。//只有下面这种情况例外,要求该变量必须在构造方法中被初始化。//并且不能有空参数的构造方法。//这样就可以让每个实例都有一个不同的变量,并且这个变量在每个实例中只会被初始化一次//于是这个变量在单个实例里就是常量了。final int s ;Si(int s) {this.s = s;}
}
class Bi {final int a = 1;final void go() {//final修饰方法无法被继承}
}
class Ci extends Bi {final int a = 1;
// void go() {
// //final修饰方法无法被继承
// }
}
final char[]a = {'a'};
final int[]b = {1};
final class PersonalLoan{}class CheapPersonalLoan extends PersonalLoan { //编译错误,无法被继承
}
@Test
public void final修饰类() {//引用没有被final修饰,所以是可变的。//final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。//虽然内存地址不可变,但是可以对内部的数据做改变。Fi f = new Fi();f.a = 1;System.out.println(f);f.a = 2;System.out.println(f);//改变实例中的值并不改变内存地址。Fi ff = f;//让引用指向新的Fi对象,原来的f对象由新的引用ff持有。//引用的指向改变也不会改变原来对象的地址f = new Fi();System.out.println(f);System.out.println(ff);
}
final关键字的知识点
-
final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。final变量一旦被初始化后不能再次赋值。
-
本地变量必须在声明时赋值。 因为没有初始化的过程
-
在匿名类中所有变量都必须是final变量。
-
final方法不能被重写, final类不能被继承
-
接口中声明的所有变量本身是final的。类似于匿名类
-
final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
-
final方法在编译阶段绑定,称为静态绑定(static binding)。
-
将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
final方法的好处:
-
提高了性能,JVM在常量池中会缓存final变量
-
final变量在多线程中并发安全,无需额外的同步开销
-
final方法是静态编译的,提高了调用速度
-
final类创建的对象是只可读的,在多线程可以安全共享
final关键字的最佳实践
final的用法
1、final 对于常量来说,意味着值不能改变,例如 final int i=100。这个i的值永远都是100。
但是对于变量来说又不一样,只是标识这个引用不可被改变,例如 final File f=new File(“c:\test.txt”);
那么这个f一定是不能被改变的,如果f本身有方法修改其中的成员变量,例如是否可读,是允许修改的。有个形象的比喻:一个女子定义了一个final的老公,这个老公的职业和收入都是允许改变的,只是这个女人不会换老公而已。
关于空白final
final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。
另外,final变量定义的时候,可以先声明,而不给初值,这中变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。
但是,final空白在final关键字final的使用上提供了更大的灵活性,为此,一个类中的final数据成员就可以实现依对象而有所不同,却有保持其恒定不变的特征。
public class FinalTest {
final int p;
final int q=3;
FinalTest(){
p=1;
}
FinalTest(int i){
p=i;//可以赋值,相当于直接定义p
q=i;//不能为一个final变量赋值
}
}
final内存分配
刚提到了内嵌机制,现在详细展开。
要知道调用一个函数除了函数本身的执行时间之外,还需要额外的时间去寻找这个函数(类内部有一个函数签名和函数地址的映射表)。所以减少函数调用次数就等于降低了性能消耗。
final修饰的函数会被编译器优化,优化的结果是减少了函数调用的次数。如何实现的,举个例子给你看:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
func();
}}
经过编译器优化之后,这个类变成了相当于这样写:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
{System.out.println("g");}
}}
看出来区别了吧?编译器直接将func的函数体内嵌到了调用函数的地方,这样的结果是节省了1000次函数调用,当然编译器处理成字节码,只是我们可以想象成这样,看个明白。
不过,当函数体太长的话,用final可能适得其反,因为经过编译器内嵌之后代码长度大大增加,于是就增加了jvm解释字节码的时间。
在使用final修饰方法的时候,编译器会将被final修饰过的方法插入到调用者代码处,提高运行速度和效率,但被final修饰的方法体不能过大,编译器可能会放弃内联,但究竟多大的方法会放弃,我还没有做测试来计算过。
下面这些内容是通过两个疑问来继续阐述的
使用final修饰方法会提高速度和效率吗
见下面的测试代码,我会执行五次:
public class Test
{ public static void getJava() { String str1 = "Java "; String str2 = "final "; for (int i = 0; i < 10000; i++) { str1 += str2; } } public static final void getJava_Final() { String str1 = "Java "; String str2 = "final "; for (int i = 0; i < 10000; i++) { str1 += str2; } } public static void main(String[] args) { long start = System.currentTimeMillis(); getJava(); System.out.println("调用不带final修饰的方法执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间"); start = System.currentTimeMillis(); String str1 = "Java "; String str2 = "final "; for (int i = 0; i < 10000; i++) { str1 += str2; } System.out.println("正常的执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间"); start = System.currentTimeMillis(); getJava_Final(); System.out.println("调用final修饰的方法执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间"); }
} 结果为:
第一次:
调用不带final修饰的方法执行时间为:1732毫秒时间
正常的执行时间为:1498毫秒时间
调用final修饰的方法执行时间为:1593毫秒时间
第二次:
调用不带final修饰的方法执行时间为:1217毫秒时间
正常的执行时间为:1031毫秒时间
调用final修饰的方法执行时间为:1124毫秒时间
第三次:
调用不带final修饰的方法执行时间为:1154毫秒时间
正常的执行时间为:1140毫秒时间
调用final修饰的方法执行时间为:1202毫秒时间
第四次:
调用不带final修饰的方法执行时间为:1139毫秒时间
正常的执行时间为:999毫秒时间
调用final修饰的方法执行时间为:1092毫秒时间
第五次:
调用不带final修饰的方法执行时间为:1186毫秒时间
正常的执行时间为:1030毫秒时间
调用final修饰的方法执行时间为:1109毫秒时间 由以上运行结果不难看出,执行最快的是“正常的执行”即代码直接编写,而使用final修饰的方法,不像有些书上或者文章上所说的那样,速度与效率与“正常的执行”无异,而是位于第二位,最差的是调用不加final修饰的方法。
观点:加了比不加好一点。
使用final修饰变量会让变量的值不能被改变吗;
见代码:
public class Final
{ public static void main(String[] args) { Color.color[3] = "white"; for (String color : Color.color) System.out.print(color+" "); }
} class Color
{ public static final String[] color = { "red", "blue", "yellow", "black" };
} 执行结果:
red blue yellow white
看!,黑色变成了白色。
在使用findbugs插件时,就会提示public static String[] color = { “red”, “blue”, “yellow”, “black” };这行代码不安全,但加上final修饰,这行代码仍然是不安全的,因为final没有做到保证变量的值不会被修改!
原因是:final关键字只能保证变量本身不能被赋与新值,而不能保证变量的内部结构不被修改。例如在main方法有如下代码Color.color = new String[]{“”};就会报错了。
如何保证数组内部不被修改
那可能有的同学就会问了,加上final关键字不能保证数组不会被外部修改,那有什么方法能够保证呢?答案就是降低访问级别,把数组设为private。这样的话,就解决了数组在外部被修改的不安全性,但也产生了另一个问题,那就是这个数组要被外部使用的。
解决这个问题见代码:
import java.util.AbstractList;
import java.util.List; public class Final
{ public static void main(String[] args) { for (String color : Color.color) System.out.print(color + " "); Color.color.set(3, "white"); }
} class Color
{ private static String[] _color = { "red", "blue", "yellow", "black" }; public static List<String> color = new AbstractList<String>() { @Override public String get(int index) { return _color[index]; } @Override public String set(int index, String value) { throw new RuntimeException("为了代码安全,不能修改数组"); } @Override public int size() { return _color.length; } }; }
这样就OK了,既保证了代码安全,又能让数组中的元素被访问了。
final方法的三条规则
规则1:final修饰的方法不可以被重写。
规则2:final修饰的方法仅仅是不能重写,但它完全可以被重载。
规则3:父类中private final方法,子类可以重新定义,这种情况不是重写。
代码示例
规则1代码public class FinalMethodTest
{public final void test(){}
}
class Sub extends FinalMethodTest
{// 下面方法定义将出现编译错误,不能重写final方法public void test(){}
}规则2代码public class Finaloverload {//final 修饰的方法只是不能重写,完全可以重载public final void test(){}public final void test(String arg){}
}规则3代码public class PrivateFinalMethodTest
{private final void test(){}
}
class Sub extends PrivateFinalMethodTest
{// 下面方法定义将不会出现问题public void test(){}
}
抽象类与接口
抽象类和接口以及抽象类和接口的区别。
2.1、抽象类第一:抽象类怎么定义?在class前添加abstract关键字就行了。第二:抽象类是无法实例化的,无法创建对象的,所以抽象类是用来被子类继承的。第三:final和abstract不能联合使用,这两个关键字是对立的。第四:抽象类的子类可以是抽象类。也可以是非抽象类。第五:抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法是供子类使用的。第六:抽象类中不一定有抽象方法,抽象方法必须出现在抽象类中。第七:抽象方法怎么定义?public abstract void doSome();第八:一个非抽象的类,继承抽象类,必须将抽象类中的抽象方法进行覆盖/重写/实现。到目前为止,只是学习了抽象类的基础语法,一个类到底声明为抽象还是非抽象,面试题(判断题):java语言中凡是没有方法体的方法都是抽象方法。不对,错误的。Object类中就有很多方法都没有方法体,都是以“;”结尾的,但他们都不是抽象方法,例如:public native int hashCode();这个方法底层调用了C++写的动态链接库程序。前面修饰符列表中没有:abstract。有一个native。表示调用JVM本地程序。2.2、接口的基础语法。1、接口是一种“引用数据类型”。2、接口是完全抽象的。3、接口怎么定义:[修饰符列表] interface 接口名{}4、接口支持多继承。5、接口中只有常量+抽象方法。6、接口中所有的元素都是public修饰的7、接口中抽象方法的public abstract可以省略。8、接口中常量的public static final可以省略。9、接口中方法不能有方法体。
抽象类
一、抽象类的基本概念
普通类是一个完善的功能类,可以直接产生实例化对象,并且在普通类中可以包含有构造方法、普通方法、static方法、常量和变量等内容。而抽象类是指在普通类的结构里面增加抽象方法的组成部分。
那么什么叫抽象方法呢?在所有的普通方法上面都会有一个“{}”,这个表示方法体,有方法体的方法一定可以被对象直接使用。而抽象方法,是指没有方法体的方法,同时抽象方法还必须使用关键字abstract做修饰。
而拥有抽象方法的类就是抽象类,抽象类要使用abstract关键字声明。
下面我写一个关于抽象类的例子:
abstract class A{//定义一个抽象类public void fun(){//普通方法System.out.println("存在方法体的方法");}public abstract void print();//抽象方法,没有方法体,有abstract关键字做修饰}二、抽象类的使用
我们看一下下面这个例子:
abstract class A{//定义一个抽象类public void fun(){//普通方法System.out.println("存在方法体的方法");}public abstract void print();//抽象方法,没有方法体,有abstract关键字做修饰}public class TestDemo {public static void main(String[] args) {A a = new A();}
}运行结果:
Exception in thread "main" java.lang.Error: Unresolved compilation problem: Cannot instantiate the type Aat com.wz.abstractdemo.TestDemo.main(TestDemo.java:15)从上可知,A是抽象的,无法直接进行实例化操作。为什么不能直接实例化呢?当一个类实例化之后,就意味着这个对象可以调用类中的属性或者放过了,但在抽象类里存在抽象方法,而抽象方法没有方法体,没有方法体就无法进行调用。既然无法进行方法调用的话,又怎么去产生实例化对象呢。所以抽象类不能进行实例化对象。
- 抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public;
- 抽象类不能直接实例化,需要依靠子类采用向上转型的方式处理;
- 抽象类必须有子类,使用extends继承,一个子类只能继承一个抽象类;
- 子类(如果不是抽象类)则必须覆写抽象类之中的全部抽象方法(如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。)否则编译不通过;
abstract class A{//定义一个抽象类public void fun(){//普通方法System.out.println("存在方法体的方法");}public abstract void print();//抽象方法,没有方法体,有abstract关键字做修饰}
//单继承
class B extends A{//B类是抽象类的子类,是一个普通类@Overridepublic void print() {//强制要求重写(也叫”实现“)System.out.println("Hello World !");}}
public class TestDemo {public static void main(String[] args) {//多态A a = new B();//向上转型a.print();//被子类所覆写的过的方法}
}运行结果:
Hello World !
现在就可以清楚的发现:
- 抽象类继承子类里面有明确的方法覆写要求,而普通类可以有选择性的来决定是否需要覆写;
- 抽象类实际上就比普通类多了一些抽象方法而已,其他组成部分和普通类完全一样;
- 普通类对象可以直接实例化,但抽象类的对象必须经过向上转型之后才可以得到。
虽然一个类的子类可以去继承任意的一个普通类,可是从开发的实际要求来讲,普通 类尽量不要去继承另外一个普通类,而是去继承抽象类。
三、抽象类的使用限制
-
抽象类中有构造方法么?
由于抽象类里会存在一些属性,那么抽象类中一定存在构造方法,其存在目的是为了属性的初始化。
并且子类对象实例化的时候,依然满足先执行父类构造,再执行子类构造的顺序。下面我写一个例子:
package com.wz.abstractdemo;abstract class A{//定义一个抽象类public A(){System.out.println("*****A类构造方法*****");}public abstract void print();//抽象方法,没有方法体,有abstract关键字做修饰} //单继承 class B extends A{//B类是抽象类的子类,是一个普通类public B(){System.out.println("*****B类构造方法*****");}@Overridepublic void print() {//强制要求覆写System.out.println("Hello World !");}} public class TestDemo {public static void main(String[] args) {A a = new B();//向上转型}}执行结果:
*****A类构造方法***** *****B类构造方法*****
-
抽象类可以用final声明么?
不能,因为抽象类必须有子类,而final定义的类不能有子类;(final关键字规定不可以进行继承,因此final与abstract这两个关键字是冲突的)
-
抽象类能否使用static声明?
下面我写一个例子:static abstract class A{//定义一个抽象类public abstract void print();}class B extends A{public void print(){System.out.println("**********");} } public class TestDemo {public static void main(String[] args) {A a = new B();//向上转型a.print();}}执行结果:
Exception in thread "main" java.lang.Error: Unresolved compilation problem: Illegal modifier for the class A; only public, abstract & final are permittedat com.manman.abstractdemo.A.<init>(TestDemo.java:3)at com.manman.abstractdemo.B.<init>(TestDemo.java:9)at com.manman.abstractdemo.TestDemo.main(TestDemo.java:18)下面再看一个关于内部抽象类的:
abstract class A{//定义一个抽象类static abstract class B{//static定义的内部类属于外部类public abstract void print();}}class C extends A.B{public void print(){System.out.println("**********");} } public class TestDemo {public static void main(String[] args) {A.B ab = new C();//向上转型ab.print();}}执行结果:
**********由此可见,外部抽象类不允许使用static声明,而内部的抽象类运行使用static声明。使用static声明的内部抽象类相当于一个外部抽象类,继承的时候使用“外部类.内部类”的形式表示类名称。
-
可以直接调用抽象类中用static声明的方法么?
任何时候,如果要执行类中的static方法的时候,都可以在没有对象的情况下直接调用,对于抽象类也一样。下面我写个例子:
abstract class A{//定义一个抽象类public static void print(){System.out.println("Hello World !");}}public class TestDemo {public static void main(String[] args) {A.print();}}运行结果:
Hello World !
接口
一、基本概念
接口(Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合。接口 通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
如果一个类只由抽象方法和全局常量组成,那么这种情况下不会将其定义为一个抽象类。只会定义为一个接口,所以接口严格的来讲属于一个特殊的类,而这个类里面只有抽象方法和全局常量,就连构造方法也没有。
下面我写一个例子:
interface A{//定义一个接口public static final String MSG = "hello";//全局常量public abstract void print();//抽象方法
}二、接口的使用
1、由于接口里面存在抽象方法,所以接口对象不能直接使用关键字new进行实例化。接口的使用原则如下:
- 接口必须要有子类,但此时一个子类可以使用implements关键字实现多个接口;
- 接口的子类(如果不是抽象类),那么必须要覆写接口中的全部抽象方法;
- 接口的对象可以利用子类对象的向上转型进行实例化。
下面我用一个例子来说明:
package com.gzm.interfacedemo;interface A{//定义一个接口Apublic static final String MSG = "hello";//全局常量public abstract void print();//抽象方法
}interface B{//定义一个接口Bpublic abstract void get();
}class X implements A,B{//X类实现了A和B两个接口@Overridepublic void print() {System.out.println("接口A的抽象方法print()");}@Overridepublic void get() {System.out.println("接口B的抽象方法get()");}}public class TestDemo {public static void main(String[] args){X x = new X();//实例化子类对象A a = x;//向上转型B b = x;//向上转型a.print();b.get(); }}运行结果:
接口A的抽象方法print()
接口B的抽象方法get()
以上的代码实例化了X类的对象,由于X类是A和B的子类,那么X类的对象可以变为A接口或者B接口对象。我们把测试主类代码改一下:
public class TestDemo {public static void main(String[] args){A a = new X();B b = (B) a;b.get();}}
运行结果:
接口B的抽象方法get()
下面我们接着做一个测验:
public class TestDemo {public static void main(String[] args){A a = new X();B b = (B) a;b.get();System.out.println(a instanceof A);System.out.println(a instanceof B);}
运行结果:
接口B的抽象方法get()
true
true
我们发现,从定义结构来讲,A和B两个接口没有任何直接联系,但这两个接口却拥有同一个子类。我们不要被类型和名称所迷惑,因为实例化的是X子类,而这个类对象属于B类的对象,所以以上代码可行,只不过从代码的编写规范来讲,并不是很好。
2、对于子类而言,除了实现接口外,还可以继承抽象类。若既要继承抽象类,同时还要实现接口的话,使用一下语法格式:
class 子类 [extends 父类] [implemetns 接口1,接口2,...] {}
下面我用例子来说明一下:
interface A{//定义一个接口Apublic static final String MSG = "hello";//全局常量public abstract void print();//抽象方法
}interface B{//定义一个接口Bpublic abstract void get();
}abstract class C{//定义一个抽象类Cpublic abstract void change();
}class X extends C implements A,B{//X类继承C类,并实现了A和B两个接口@Overridepublic void print() {System.out.println("接口A的抽象方法print()");}@Overridepublic void get() {System.out.println("接口B的抽象方法get()");}@Overridepublic void change() {System.out.println("抽象类C的抽象方法change()");}}
对于接口,里面的组成只有抽象方法和全局常量,所以很多时候为了书写简单,可以不用写public abstract 或者public static final。并且,接口中的访问权限只有一种:public,即:定义接口方法和全局常量的时候就算没有写上public,那么最终的访问权限也是public,注意不是default。以下两种写法是完全等价的:
interface A{public static final String MSG = "hello";public abstract void print();
}
等价于:
interface A{String MSG = "hello";void print();
}
但是,这样会不会带来什么问题呢?如果子类子类中的覆写方法也不是public,我们来看:
package com.gzm.interfacedemo;interface A{String MSG = "hello";void print();
}class X implements A{//注意子类这里不是public 而是默认defaultvoid print() {System.out.println("接口A的抽象方法print()");}}public class TestDemo {public static void main(String[] args){A a = new X();a.print();}
}下面我们看看运行结果:
Exception in thread "main" java.lang.IllegalAccessError: com.wz.interfacedemo.X.print()Vat com.gzm.interfacedemo.TestDemo.main(TestDemo.java:22)
这是因为接口中默认是public修饰,若子类中没用public修饰,则访问权限变严格了,给子类分配的是更低的访问权限。所以,在定义接口的时候强烈建议在抽象方法前加上public ,子类也加上:
interface A{String MSG = "hello";public void print();
}class X implements A{public void print() {System.out.println("接口A的抽象方法print()");}}
3、在Java中,一个抽象类只能继承一个抽象类,但一个接口却可以使用extends关键字同时继承多个接口(但接口不能继承抽象类)。
下面我写一个例子:
interface A{public void funA();
}interface B{public void funB();
}//C接口同时继承了A和B两个接口
interface C extends A,B{//使用的是extendspublic void funC();
}class X implements C{@Overridepublic void funA() {}@Overridepublic void funB() {}@Overridepublic void funC() {}}
由此可见,从继承关系来说接口的限制比抽象类少:
- 一个抽象类只能继承一个抽象父类,而接口可以继承多个接口;
- 一个子类只能继承一个抽象类,却可以实现多个接口(在Java中,接口的主要功能是解决单继承局限问题)
4、从接口的概念上来讲,接口只能由抽象方法和全局常量组成,但是内部结构是不 受概念限制的,正如抽象类中可以定义抽象内部类一样,在接口中也可以定义普通内 部类、抽象内部类和内部接口(但从实际的开发来讲,用户自己去定义内部抽象类或 内部接口的时候是比较少见的)
下面我们看一个例子,在接口中定义一个抽象内部类:
interface A{public void funA();abstract class B{//定义一个抽象内部类public abstract void funB();}
}
在接口中如果使用了static去定义一个内接口,它表示一个外部接口:
interface A{public void funA();static interface B{//使用了static,是一个外部接口public void funB();}
}
class X implements A.B{@Overridepublic void funB() {}
}
三、接口的实际应用(标准定义)
在日常的生活之中,接口这一名词经常听到的,例如:USB接口、打印接口、充电接口等等。
如果要进行开发,要先开发出USB接口标准,然后设备厂商才可以设计出USB设备。
现在假设每一个USB设备只有两个功能:安装驱动程序、工作。
定义一个USB的标准:
interface USB { // 操作标准 public void install() ;public void work() ;
}
在电脑上应用此接口:
class Computer {public void plugin(USB usb) {usb.install() ;usb.work() ;}
}
定义USB设备—手机:
class Phone implements USB {public void install() {System.out.println("安装手机驱动程序。") ;}public void work() {System.out.println("手机与电脑进行工作。") ;}
}
四、接口的作用
规范性
接口的规范性体现在抽象方法中,因为子类实现接口,就必须全部重写接口中所有的抽象方法,而且方法声明一模一样,这就是强制性,也是规范性的体现。
拓展性
生活中的接口有很多,USB接口,插座孔,充电孔,等只要是按照接口的规则创建,就可以和接口对接,所有按照接口规范创建的都可以对接,所有的实现类只要实现接口重写接口中所有的抽象方法【规则】,就可以使用,这也就是接口的拓展性。
五、接口中的成员特点
接口中所有的变量都是被final修饰的,也就是只能赋值一次。所以接口中也没有变量这一说,都是常量。
-
接口中默认的常量使用final修饰的,只能赋值一次。
-
接口中默认的常量默认都是static修饰的,也就是说可以通过类名.调用。
-
接口中默认都是public修饰的,都是公开的。
接口中所有的方法都是抽象方法,所以都默认使用public abstract修饰
构造方法
因为接口不能创建对象,所以接口中也没有构造方法,没有构造代码块,没有静态代码块。
-
接口中没有构造方法
-
接口中没有构造代码块
-
接口中没有静态代码块
六、抽象类和接口有什么区别
- 抽象类是半抽象的,接口是完全抽象的。
- 抽象类中有构造方法,接口没有构造方法。
- 接口和接口之间支持多继承,类和类之间只能单继承。
- 一个类可以同时实现多个接口,一个抽象类只能继承一个类。
- 接口中只允许出现常量和抽象方法。
注:JDK 1.8 以后,接口里可以有静态方法和方法体了。
JDK 1.8 以后,接口允许包含具体实现的方法,该方法称为"默认方法",默认方法使用 default 关键字修饰。
JDK 1.9 以后,允许将方法定义为 private,使得某些复用的代码不会把方法暴露出去。
七、思维导图
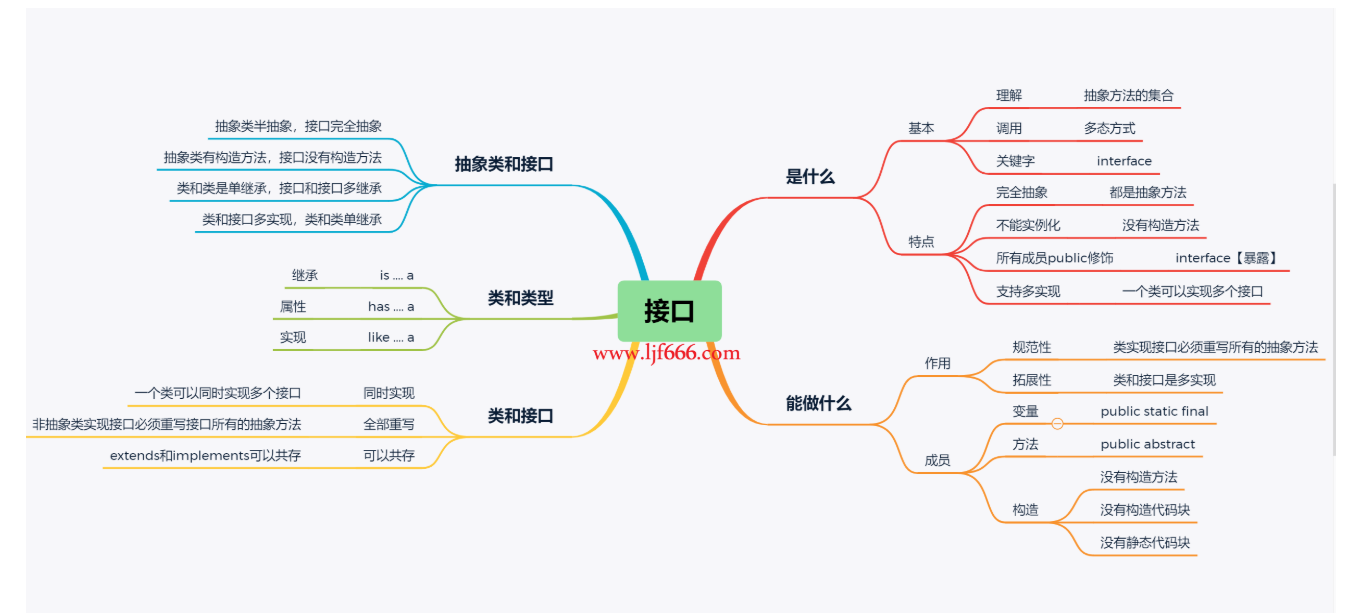
Object 类
一、Object类简介
Object类是Javajava.lang包下的核心类,Object类是所有类的父类,何一个类时候如果没有明确的继承一个父类的话,那么它就是Object的子类;
以下两种类的定义的最终效果是完全相同的:
class Person{
}
class Person extends Object{}
使用Object类型接收所有对象

Object 类属于
java.lang包,此包下的所有类在使用时无需手动导入,系统会在程序编译期间自动导入
Object 类的结构图(Object提供了11 个方法)

下面我们对这些方法一一分析,看看这些方法都有什么作用:
- clone()
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
- getClass()
final方法,返回Class类型的对象,反射来获取对象。
- toString()
该方法用得比较多,一般子类都有覆盖,来获取对象的信息。
- finalize()
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
- equals()
比较对象的内容是否相等
- hashCode()
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
- wait()
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
其他线程调用了该对象的notify方法。
其他线程调用了该对象的notifyAll方法。
其他线程调用了interrupt中断该线程。
时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
- notify()
该方法唤醒在该对象上等待的某个线程。
- notifyAll()
该方法唤醒在该对象上等待的所有线程。
二. Object类的常用方法
| 方法名称 | 类型 | 描述 |
|---|---|---|
| toString( ) | 普通 | 取得对象信息 |
| equals() | 普通 | 比较对象是否相等 |
- toString方法
toString():取得对象信息,返回该对象的字符串表示
下面我写一个例子:
public class ObjectTest01 {public static void main(String[] args) {Person person = new Person(20,"manamn");System.out.println(person);}
}
class Person{private int age;private String name;public Person() {}public Person(int age, String name) {this.age = age;this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}运行结果:
com.manman.javase.object.Person@4554617c
在使用对象直接输出的时候,默认输出的是一个对象在堆内存上的地址值;如若要输出该对象的内容,则要覆写toString()方法
覆写Person中的toString()方法
@Overridepublic String toString(){return "年龄为" + this.age + "名字为" + this.name; }
此时执行结果:
年龄:20名字:manamn
toString( )的核心目的在于取得对象信息
String作为信息输出的重要数据类型,在Java中所有的数据类型只要遇见String就执行了+,都要求其变为字符串后连接,而所有对象想要变为字符串就默认用toString( )方法
例如:
System.out.println("hello" + 123);>>> 输出:hello123为什么hello 和 123 (一个是字符串,一个是int类型的数据) 就可以直接拼接在一起呢?
因为字符串是爸爸,在这个拼爹的时代,他有一个万能的爸爸Object
换而言之,Object是所有类的父类,任意类都是继承Object类的。而Object中定义了 toString()方法,所以任意类中都包含了toString()方法,对象在实例化之后都可以调用。
所以任意对象转字符串的输出,是通过覆写 toString()方法实现的…
每一个类中都包含有toString(),但是并不是每一个类都覆写了toString()
-
quals方法
equals():对象比较
String类对象比较 使用的是 equals()方法,实际上String类的equals()方法就是覆写 Object类中的equals()方法
- 基本数据类型之间比较使用 “==”(如: a == 3,b == 4, a == b,比较的是值是否相等)
- 引用数据类型比较 : 调用equals()方法进行比较。
用equals()来比较两个对象内容是否相同:
package com.manman.javase.object;/*** @author 满满* createDate 2022/2/23 15:34*/ public class ObjectTest02 {public static void main(String[] args) {People people1 = new People(30,"zhangsan");People people2 = new People(30,"zhangsan");System.out.println(people1.equals(people2));} } class People{private int age;private String name;public People() {}public People(int age, String name) {this.age = age;this.name = name;}}执行结果:
false两个对象people1和people2的内容明明相等,应该是true呀?怎么会是false?
因为此时直接调用equals()方法默认进行比较的是两个对象的地址。
在源码中,传递来的Object对象和当前对象比较地址值,返回布尔值。

但是,new一下就会在堆上创建新空间,两个对象地址自然不会相同,所以为false。
但是在判断两个对象是否相等时,比如要判断一个Person类的两个对象的姓名是否相同时,此时要重新覆写
equals()还是上面的例子,覆写equals()方法:
/*** 这里重写父类Object 的equals方法* @param obj* @return*/@Overridepublic boolean equals(Object obj) {if (obj == null) {return false;}//判断内存地址是否相同 内存地址相同,则他们是同一个引用返回trueif (this == obj){return true;}if ( !(obj instanceof People)){return false;} // 程序进行到这里 说明 它不是空 且 是People对象 // 此时进行向下转型 将Object 强转为 Perple对象People p = (People)obj;return p.name.equals(this.name)&& p.age == this.age;}执行结果:
true所以,引用类型的数据在进行比较时,应该先覆写
equals()方法,不然比较的还是两个对象的堆内存地址值,必然不会相等.
String类
常用类
1、八种基本数据类型对应的包装类。
1.1、什么是自动装箱和自动拆箱,代码怎么写?
Integer x = 100; // x里面并不是保存100,保存的是100这个对象的内存地址。
Integer y = 100;
System.out.println(x == y); // true
Integer x = 128;Integer y = 128;System.out.println(x == y); // false1.2、Integer类常用方法。Integer.valueOf()Integer.parseInt("123")Integer.parseInt("中文") : NumberFormatException1.3、Integer String int三种类型互相转换。
2、日期类2.1、获取系统当前时间Date d = new Date();2.2、日期格式化:Date --> Stringyyyy-MM-dd HH:mm:ss SSSSimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss SSS");String s = sdf.format(new Date());2.3、String --> DateSimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss");Date d = sdf.parse("2008-08-08 08:08:08");2.4、获取毫秒数long begin = System.currentTimeMillis();Date d = new Date(begin - 1000 * 60 * 60 * 24);
3、数字类
3.1、DecimalFormat数字格式化
###,###.## 表示加入千分位,保留两个小数。
###,###.0000 表示加入千分位,保留4个小数,不够补0
3.2、BigDecimal
财务软件中通常使用BigDecimal
4、随机数
4.1、怎么产生int类型随机数。Random r = new Random();int i = r.nextInt();
4.2、怎么产生某个范围之内的int类型随机数。Random r = new Random();int i = r.nextInt(101); // 产生[0-100]的随机数。
5、枚举
5.1、枚举是一种引用数据类型。
5.2、枚举编译之后也是class文件。
5.3、枚举类型怎么定义?
enum 枚举类型名{
枚举值,枚举值2,枚举值3
}
5.4、当一个方法执行结果超过两种情况,并且是一枚一枚可以列举出来
的时候,建议返回值类型设计为枚举类型。
异常
异常处理机制
-
java中异常的作用是:增强程序健壮性。
-
java中异常以类和对象的形式存在。
1、java的异常处理机制
1.1、异常在java中以类和对象的形式存在。那么异常的继承结构是怎样的?
我们可以使用UML图来描述一下继承结构。
画UML图有很多工具,例如:Rational Rose(收费的)、starUML等....ObjectObject下有Throwable(可抛出的)Throwable下有两个分支:Error(不可处理,直接退出JVM)和Exception(可处理的)Exception下有两个分支:Exception的直接子类:编译时异常(要求程序员在编写程序阶段必须预先对这些异常进行处理,如果不处理编译器报错,因此得名编译时异常。)。RuntimeException:运行时异常。(在编写程序阶段程序员可以预先处理,也可以不管,都行。)1.2、编译时异常和运行时异常,都是发生在运行阶段。编译阶段异常是不会发生的。
编译时异常因为什么而得名?因为编译时异常必须在编译(编写)阶段预先处理,如果不处理编译器报错,因此得名。所有异常都是在运行阶段发生的。因为只有程序运行阶段才可以new对象。因为异常的发生就是new异常对象。1.3、编译时异常和运行时异常的区别?编译时异常一般发生的概率比较高。举个例子:你看到外面下雨了,倾盆大雨的。你出门之前会预料到:如果不打伞,我可能会生病(生病是一种异常)。而且这个异常发生的概率很高,所以我们出门之前要拿一把伞。“拿一把伞”就是对“生病异常”发生之前的一种处理方式。对于一些发生概率较高的异常,需要在运行之前对其进行预处理。运行时异常一般发生的概率比较低。举个例子:小明走在大街上,可能会被天上的飞机轮子砸到。被飞机轮子砸到也算一种异常。但是这种异常发生概率较低。在出门之前你没必要提前对这种发生概率较低的异常进行预处理。如果你预处理这种异常,你将活的很累。假设你在出门之前,你把能够发生的异常都预先处理,你这个人会更加的安全,但是你这个人活的很累。假设java中没有对异常进行划分,没有分为:编译时异常和运行时异常,所有的异常都需要在编写程序阶段对其进行预处理,将是怎样的效果呢?首先,如果这样的话,程序肯定是绝对的安全的。但是程序员编写程序太累,代码到处都是处理异常的代码。1.4、编译时异常还有其他名字:受检异常:CheckedException受控异常1.5、运行时异常还有其它名字:未受检异常:UnCheckedException非受控异常1.6、再次强调:所有异常都是发生在运行阶段的。1.7、Java语言中对异常的处理包括两种方式:第一种方式:在方法声明的位置上,使用throws关键字,抛给上一级。谁调用我,我就抛给谁。抛给上一级。第二种方式:使用try..catch语句进行异常的捕捉。这件事发生了,谁也不知道,因为我给抓住了。举个例子:我是某集团的一个销售员,因为我的失误,导致公司损失了1000元,“损失1000元”这可以看做是一个异常发生了。我有两种处理方式,第一种方式:我把这件事告诉我的领导【异常上抛】第二种方式:我自己掏腰包把这个钱补上。【异常的捕捉】张三 --> 李四 ---> 王五 --> CEO思考:异常发生之后,如果我选择了上抛,抛给了我的调用者,调用者需要对这个异常继续处理,那么调用者处理这个异常同样有两种处理方式。1.8、注意:Java中异常发生之后如果一直上抛,最终抛给了main方法,main方法继续
向上抛,抛给了调用者JVM,JVM知道这个异常发生,只有一个结果。终止java程序的执行。
异常体系图
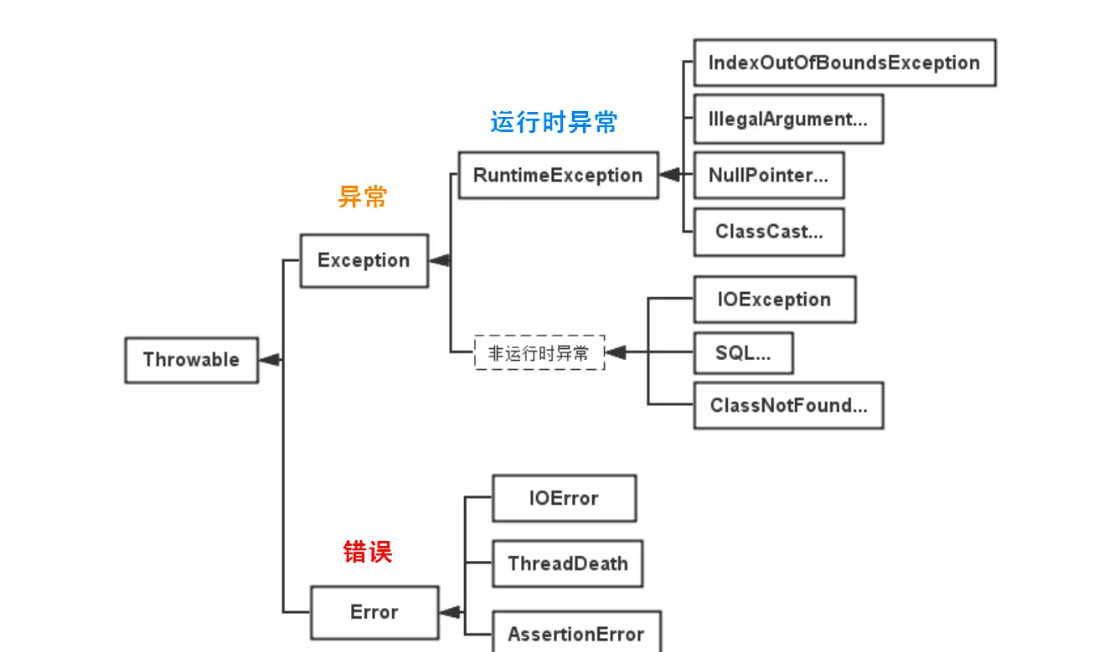
从上面这幅图可以看出,Throwable是java语言中所有错误和异常的超类(万物即可抛)。它有两个子类:Error、Exception。
Java标准库内建了一些通用的异常,这些类以Throwable为顶层父类。
Throwable又派生出Error类和Exception类。
错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。
总体上我们根据Javac对异常的处理要求,将异常类分为2类。
非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try…catch…finally)这样的异常,也可以不处理。
对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。
这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
需要明确的是:检查和非检查是对于javac来说的,这样就很好理解和区分了。
初识异常
异常是在执行某个函数时引发的,而函数又是层级调用,形成调用栈的,因为,只要一个函数发生了异常,那么他的所有的caller都会被异常影响。当这些被影响的函数以异常信息输出时,就形成的了异常追踪栈。
异常最先发生的地方,叫做异常抛出点。
public class 异常 {public static void main (String [] args ){System . out. println( "----欢迎使用命令行除法计算器----" ) ;CMDCalculate ();}public static void CMDCalculate (){Scanner scan = new Scanner ( System. in );int num1 = scan .nextInt () ;int num2 = scan .nextInt () ;int result = devide (num1 , num2 ) ;System . out. println( "result:" + result) ;scan .close () ;}public static int devide (int num1, int num2 ){return num1 / num2 ;}// ----欢迎使用命令行除法计算器----
// 1
// 0
// Exception in thread "main" java.lang.ArithmeticException: / by zero
// at com.javase.异常.异常.devide(异常.java:24)
// at com.javase.异常.异常.CMDCalculate(异常.java:19)
// at com.javase.异常.异常.main(异常.java:12)从上面的例子可以看出,当devide函数发生除0异常时,devide函数将抛出ArithmeticException异常,因此调用他的CMDCalculate函数也无法正常完成,因此也发送异常,而CMDCalculate的caller——main 因为CMDCalculate抛出异常,也发生了异常,这样一直向调用栈的栈底回溯。
这种行为叫做异常的冒泡,异常的冒泡是为了在当前发生异常的函数或者这个函数的caller中找到最近的异常处理程序。由于这个例子中没有使用任何异常处理机制,因此异常最终由main函数抛给JRE,导致程序终止。
上面的代码不使用异常处理机制,也可以顺利编译,因为2个异常都是非检查异常。但是下面的例子就必须使用异常处理机制,因为异常是检查异常。
代码中我选择使用throws声明异常,让函数的调用者去处理可能发生的异常。但是为什么只throws了IOException呢?因为FileNotFoundException是IOException的子类,在处理范围内。
异常和错误
下面看一个例子
//错误即error一般指jvm无法处理的错误
//异常是Java定义的用于简化错误处理流程和定位错误的一种工具。
public class 错误和错误 {Error error = new Error();public static void main(String[] args) {throw new Error();}//下面这四个异常或者错误有着不同的处理方法public void error1 (){//编译期要求必须处理,因为这个异常是最顶层异常,包括了检查异常,必须要处理try {throw new Throwable();} catch (Throwable throwable) {throwable.printStackTrace();}}//Exception也必须处理。否则报错,因为检查异常都继承自exception,所以默认需要捕捉。public void error2 (){try {throw new Exception();} catch (Exception e) {e.printStackTrace();}}//error可以不处理,编译不报错,原因是虚拟机根本无法处理,所以啥都不用做public void error3 (){throw new Error();}//runtimeexception众所周知编译不会报错public void error4 (){throw new RuntimeException();}
// Exception in thread "main" java.lang.Error
// at com.javase.异常.错误.main(错误.java:11)}异常的处理方式
在编写代码处理异常时,对于检查异常,有2种不同的处理方式:
使用try…catch…finally语句块处理它。
或者,在函数签名中使用throws 声明交给函数调用者caller去解决。
下面看几个具体的例子,包括error,exception和throwable
上面的例子是运行时异常,不需要显示捕获。 下面这个例子是可检查异常需,要显示捕获或者抛出
@Test
public void testException() throws IOException
{//FileInputStream的构造函数会抛出FileNotFoundExceptionFileInputStream fileIn = new FileInputStream("E:\\a.txt");int word;//read方法会抛出IOExceptionwhile((word = fileIn.read())!=-1){System.out.print((char)word);}//close方法会抛出IOExceptionfileIn.close();
}一般情况下的处理方式 try catch finally
public class 异常处理方式 {@Test
public void main() {try{//try块中放可能发生异常的代码。InputStream inputStream = new FileInputStream("a.txt");//如果执行完try且不发生异常,则接着去执行finally块和finally后面的代码(如果有的话)。int i = 1/0;//如果发生异常,则尝试去匹配catch块。throw new SQLException();//使用1.8jdk同时捕获多个异常,runtimeexception也可以捕获。只是捕获后虚拟机也无法处理,所以不建议捕获。}catch(SQLException | IOException | ArrayIndexOutOfBoundsException exception){System.out.println(exception.getMessage());//每一个catch块用于捕获并处理一个特定的异常,或者这异常类型的子类。Java7中可以将多个异常声明在一个catch中。//catch后面的括号定义了异常类型和异常参数。如果异常与之匹配且是最先匹配到的,则虚拟机将使用这个catch块来处理异常。//在catch块中可以使用这个块的异常参数来获取异常的相关信息。异常参数是这个catch块中的局部变量,其它块不能访问。//如果当前try块中发生的异常在后续的所有catch中都没捕获到,则先去执行finally,然后到这个函数的外部caller中去匹配异常处理器。//如果try中没有发生异常,则所有的catch块将被忽略。}catch(Exception exception){System.out.println(exception.getMessage());//...}finally{//finally块通常是可选的。//无论异常是否发生,异常是否匹配被处理,finally都会执行。//finally主要做一些清理工作,如流的关闭,数据库连接的关闭等。}一个try至少要跟一个catch或者finally
try {int i = 1;}finally {//一个try至少要有一个catch块,否则, 至少要有1个finally块。但是finally不是用来处理异常的,finally不会捕获异常。}
}异常出现时该方法后面的代码就不会再执行了,即使异常已经被捕获了。这里举一个不一样的例子,在catch语句块之后仍然可以试用 try catch finally
@Test
public void test() {try {throwE();System.out.println("我前面抛出异常了");System.out.println("我不会执行了");} catch (StringIndexOutOfBoundsException e) {System.out.println(e.getCause());}catch (Exception ex) {//在catch块中仍然可以使用try catch finallytry {throw new Exception();}catch (Exception ee) {}finally {System.out.println("我所在的catch块没有执行,我也不会执行的");}}
}
//在方法声明中抛出的异常必须由调用方法处理或者继续往上抛,
// 当抛到jre时由于无法处理终止程序
public void throwE (){
// Socket socket = new Socket("127.0.0.1", 80);//手动抛出异常时,不会报错,但是调用该方法的方法需要处理这个异常,否则会出错。
// java.lang.StringIndexOutOfBoundsException
// at com.javase.异常.异常处理方式.throwE(异常处理方式.java:75)
// at com.javase.异常.异常处理方式.test(异常处理方式.java:62)throw new StringIndexOutOfBoundsException();}"不负责任"的throws
throws是另一种处理异常的方式,它不同于try…catch…finally,throws仅仅是将函数中可能出现的异常向调用者声明,而自己则不具体处理。
采取这种异常处理的原因可能是:方法本身不知道如何处理这样的异常,或者说让调用者处理更好,调用者需要为可能发生的异常负责。
public void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN
{ //foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。
}纠结的finally
finally块不管异常是否发生,只要对应的try执行了,则它一定也执行。只有一种方法让finally块不执行:**System.exit()。**因此finally块通常用来做资源释放操作:关闭文件,关闭数据库连接等等。
良好的编程习惯是:在try块中打开资源,在finally块中清理释放这些资源。
需要注意的地方:
1、finally块没有处理异常的能力。处理异常的只能是catch块。
2、在同一try…catch…finally块中 ,如果try中抛出异常,且有匹配的catch块,则先执行catch块,再执行finally块。如果没有catch块匹配,则先执行finally,然后去外面的调用者中寻找合适的catch块。
3、在同一try…catch…finally块中 ,try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行:首先执行finally块,然后去外围调用者中寻找合适的catch块。
public class finally使用 {public static void main(String[] args) {try {throw new IllegalAccessException();}catch (IllegalAccessException e) {// throw new Throwable();//此时如果再抛异常,finally无法执行,只能报错。//finally无论何时都会执行//除非我显示调用。此时finally才不会执行System.exit(0);}finally {System.out.println("你真狠");}}
}throw : JRE也使用的关键字
throw exceptionObject
程序员也可以通过throw语句手动显式的抛出一个异常。throw语句的后面必须是一个异常对象。
throw 语句必须写在函数中,执行throw 语句的地方就是一个异常抛出点,它和由JRE自动形成的异常抛出点没有任何差别。
public void save(User user)
{if(user == null) throw new IllegalArgumentException("User对象为空");//......}自定义异常
如果要自定义异常类,则扩展Exception类即可,因此这样的自定义异常都属于检查异常(checked exception)。如果要自定义非检查异常,则扩展自RuntimeException。
按照国际惯例,自定义的异常应该总是包含如下的构造函数:
一个无参构造函数 一个带有String参数的构造函数,并传递给父类的构造函数。 一个带有String参数和Throwable参数,并都传递给父类构造函数 一个带有Throwable 参数的构造函数,并传递给父类的构造函数。 下面是IOException类的完整源代码,可以借鉴。
public class IOException extends Exception
{static final long serialVersionUID = 7818375828146090155L;public IOException(){super();}public IOException(String message){super(message);}public IOException(String message, Throwable cause){super(message, cause);}public IOException(Throwable cause){super(cause);}
}异常的注意事项
异常的注意事项
当子类重写父类的带有 throws声明的函数时,其throws声明的异常必须在父类异常的可控范围内——用于处理父类的throws方法的异常处理器,必须也适用于子类的这个带throws方法 。这是为了支持多态。
例如,父类方法throws 的是2个异常,子类就不能throws 3个及以上的异常。父类throws IOException,子类就必须throws IOException或者IOException的子类。
至于为什么?我想,也许下面的例子可以说明。
class Father
{public void start() throws IOException{throw new IOException();}
}class Son extends Father
{public void start() throws Exception{throw new SQLException();}
}/假设上面的代码是允许的(实质是错误的)*****/
class Test
{public static void main(String[] args){Father[] objs = new Father[2];objs[0] = new Father();objs[1] = new Son();for(Father obj:objs){//因为Son类抛出的实质是SQLException,而IOException无法处理它。//那么这里的try。。catch就不能处理Son中的异常。//多态就不能实现了。try {obj.start();}catch(IOException){//处理IOException}}}
}JAVA异常常见面试题
下面是我个人总结的在Java和J2EE开发者在面试中经常被问到的有关Exception和Error的知识。在分享我的回答的时候,我也给这些问题作了快速修订,并且提供源码以便深入理解。我总结了各种难度的问题,适合新手码农和高级Java码农。如果你遇到了我列表中没有的问题,并且这个问题非常好,请在下面评论中分享出来。你也可以在评论中分享你面试时答错的情况。
1) Java中什么是Exception?
这个问题经常在第一次问有关异常的时候或者是面试菜鸟的时候问。我从来没见过面高级或者资深工程师的时候有人问这玩意,但是对于菜鸟,是很愿意问这个的。
简单来说,异常是Java传达给你的系统和程序错误的方式。在java中,异常功能是通过实现比如Throwable,Exception,RuntimeException之类的类,然后还有一些处理异常时候的关键字,比如throw,throws,try,catch,finally之类的。 所有的异常都是通过Throwable衍生出来的。Throwable把错误进一步划分为 java.lang.Exception 和 java.lang.Error. java.lang.Error 用来处理系统错误,例如java.lang.StackOverFlowError 之类的。然后 Exception用来处理程序错误,请求的资源不可用等等。
2) Java中的检查型异常和非检查型异常有什么区别?
这又是一个非常流行的Java异常面试题,会出现在各种层次的Java面试中。
检查型异常和非检查型异常的主要区别在于其处理方式。检查型异常需要使用try, catch和finally关键字在编译期进行处理,否则会出现编译器会报错。对于非检查型异常则不需要这样做。Java中所有继承自java.lang.Exception类的异常都是检查型异常,所有继承自RuntimeException的异常都被称为非检查型异常。
3) Java中的NullPointerException和ArrayIndexOutOfBoundException之间有什么相同之处?
在Java异常面试中这并不是一个很流行的问题,但会出现在不同层次的初学者面试中,用来测试应聘者对检查型异常和非检查型异常的概念是否熟悉。顺便说一下,该题的答案是,
这两个异常都是非检查型异常,都继承自RuntimeException。该问题可能会引出另一个问题,即Java和C的数组有什么不同之处,因为C里面的数组是没有大小限制的,绝对不会抛出ArrayIndexOutOfBoundException。
4)在Java异常处理的过程中,你遵循的那些最好的实践是什么?
这个问题在面试技术经理是非常常见的一个问题。因为异常处理在项目设计中是非常关键的,所以精通异常处理是十分必要的。异常处理有很多最佳实践,下面列举集中,它们提高你代码的健壮性和灵活性:
- 调用方法的时候返回布尔值来代替返回null,这样可以 NullPointerException。由于空指针是java异常里最恶心的异常
- catch块里别不写代码。空catch块是异常处理里的错误事件,因为它只是捕获了异常,却没有任何处理或者提示。通常你起码要打印出异常信息,当然你最好根据需求对异常信息进行处理。
3)能抛受控异常(checked Exception)就尽量不抛受非控异常(checked Exception)。通过去掉重复的异常处理代码,可以提高代码的可读性。
- 绝对不要让你的数据库相关异常显示到客户端。由于绝大多数数据库和SQLException异常都是受控异常,在Java中,你应该在DAO层把异常信息处理,然后返回处理过的能让用户看懂并根据异常提示信息改正操作的异常信息。
- 在Java中,一定要在数据库连接,数据库查询,流处理后,在finally块中调用close()方法。
5) 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?
这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比Java更早编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限的系统资源(比如文件描述符)在你使用后尽早得到释放。 Joshua Bloch编写的 Effective Java 一书 中多处涉及到了该话题,值得一读。
6) throw 和 throws这两个关键字在java中有什么不同?
一个java初学者应该掌握的面试问题。 throw 和 throws乍看起来是很相似的尤其是在你还是一个java初学者的时候。尽管他们看起来相似,都是在处理异常时候使用到的。但在代码里的使用方法和用到的地方是不同的。throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常, 你也可以申明未检查的异常,但这不是编译器强制的。如果方法抛出了异常那么调用这个方法的时候就需要将这个异常处理。另一个关键字 throw 是用来抛出任意异常的,按照语法你可以抛出任意 Throwable (i.e. Throwable 或任何Throwable的衍生类) , throw可以中断程序运行,因此可以用来代替return . 最常见的例子是用 throw 在一个空方法中需要return的地方抛出
UnSupportedOperationException 代码如下 :
| 123 | private``static ````void show() {thrownew ``````UnsupportedOperationException(“Notyet implemented”`);``} ``` |
|---|---|
可以看下这篇 文章查看这两个关键字在java中更多的差异 。
7) 什么是“异常链”?
“异常链”是Java中非常流行的异常处理概念,是指在进行一个异常处理时抛出了另外一个异常,由此产生了一个异常链条。该技术大多用于将“ 受检查异常” ( checked exception)封装成为“非受检查异常”(unchecked exception)或者RuntimeException。顺便说一下,如果因为因为异常你决定抛出一个新的异常,你一定要包含原有的异常,这样,处理程序才可以通过getCause()和initCause()方法来访问异常最终的根源。
8) 你曾经自定义实现过异常吗?怎么写的?
很显然,我们绝大多数都写过自定义或者业务异常,像AccountNotFoundException。在面试过程中询问这个Java异常问题的主要原因是去发现你如何使用这个特性的。这可以更准确和精致的去处理异常,当然这也跟你选择checked 还是unchecked exception息息相关。通过为每一个特定的情况创建一个特定的异常,你就为调用者更好的处理异常提供了更好的选择。相比通用异常(general exception),我更倾向更为精确的异常。大量的创建自定义异常会增加项目class的个数,因此,在自定义异常和通用异常之间维持一个平衡是成功的关键。
9) JDK7中对异常处理做了什么改变?
这是最近新出的Java异常处理的面试题。JDK7中对错误(Error)和异常(Exception)处理主要新增加了2个特性,一是在一个catch块中可以出来多个异常,就像原来用多个catch块一样。另一个是自动化资源管理(ARM), 也称为try-with-resource块。这2个特性都可以在处理异常时减少代码量,同时提高代码的可读性。对于这些特性了解,不仅帮助开发者写出更好的异常处理的代码,也让你在面试中显的更突出。我推荐大家读一下Java 7攻略,这样可以更深入的了解这2个非常有用的特性。
10) 你遇到过 OutOfMemoryError 错误嘛?你是怎么搞定的?
这个面试题会在面试高级程序员的时候用,面试官想知道你是怎么处理这个危险的OutOfMemoryError错误的。必须承认的是,不管你做什么项目,你都会碰到这个问题。所以你要是说没遇到过,面试官肯定不会买账。要是你对这个问题不熟悉,甚至就是没碰到过,而你又有3、4年的Java经验了,那么准备好处理这个问题吧。在回答这个问题的同时,你也可以借机向面试秀一下你处理内存泄露、调优和调试方面的牛逼技能。我发现掌握这些技术的人都能给面试官留下深刻的印象。
11) 如果执行finally代码块之前方法返回了结果,或者JVM退出了,finally块中的代码还会执行吗?
这个问题也可以换个方式问:“如果在try或者finally的代码块中调用了System.exit(),结果会是怎样”。了解finally块是怎么执行的,即使是try里面已经使用了return返回结果的情况,对了解Java的异常处理都非常有价值。只有在try里面是有System.exit(0)来退出JVM的情况下finally块中的代码才不会执行。
12)Java中final,finalize,finally关键字的区别
这是一个经典的Java面试题了。我的一个朋友为Morgan Stanley招电信方面的核心Java开发人员的时候就问过这个问题。final和finally是Java的关键字,而finalize则是方法。final关键字在创建不可变的类的时候非常有用,只是声明这个类是final的。而finalize()方法则是垃圾回收器在回收一个对象前调用,但也Java规范里面没有保证这个方法一定会被调用。finally关键字是唯一一个和这篇文章讨论到的异常处理相关的关键字。在你的产品代码中,在关闭连接和资源文件的是时候都必须要用到finally块。
集合
一、集合大纲
Connection 集合:
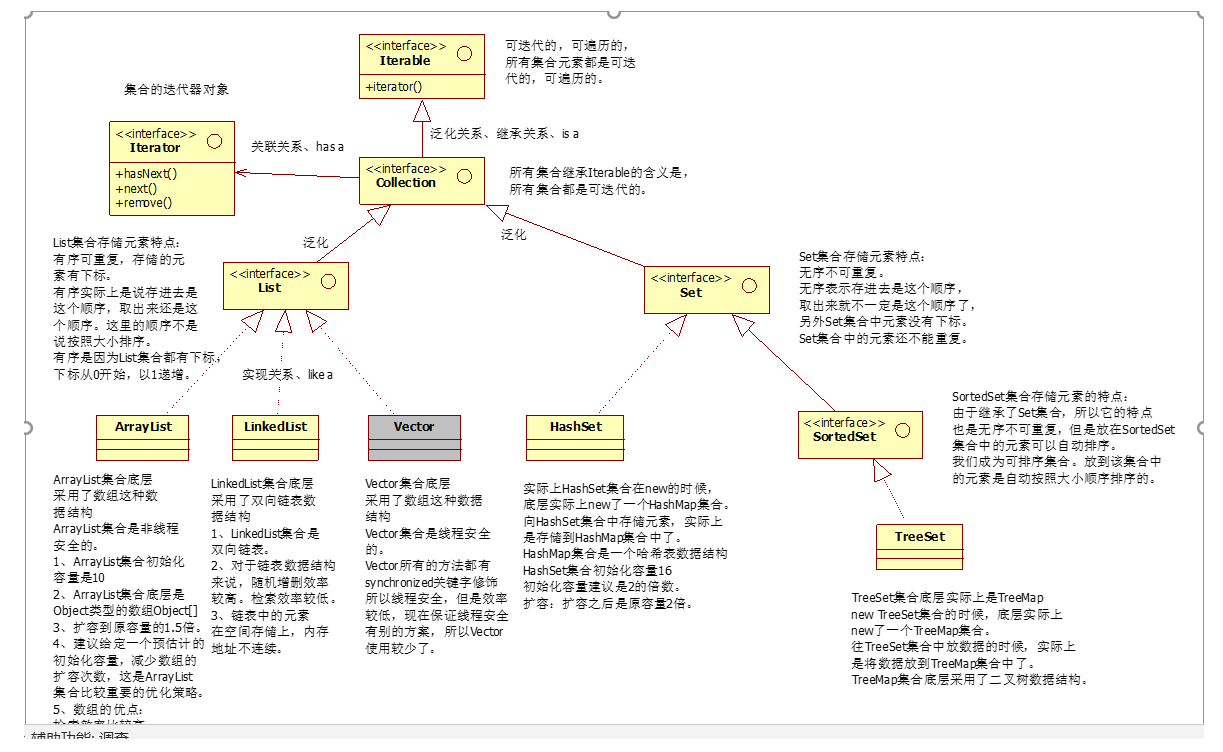
Map集合:
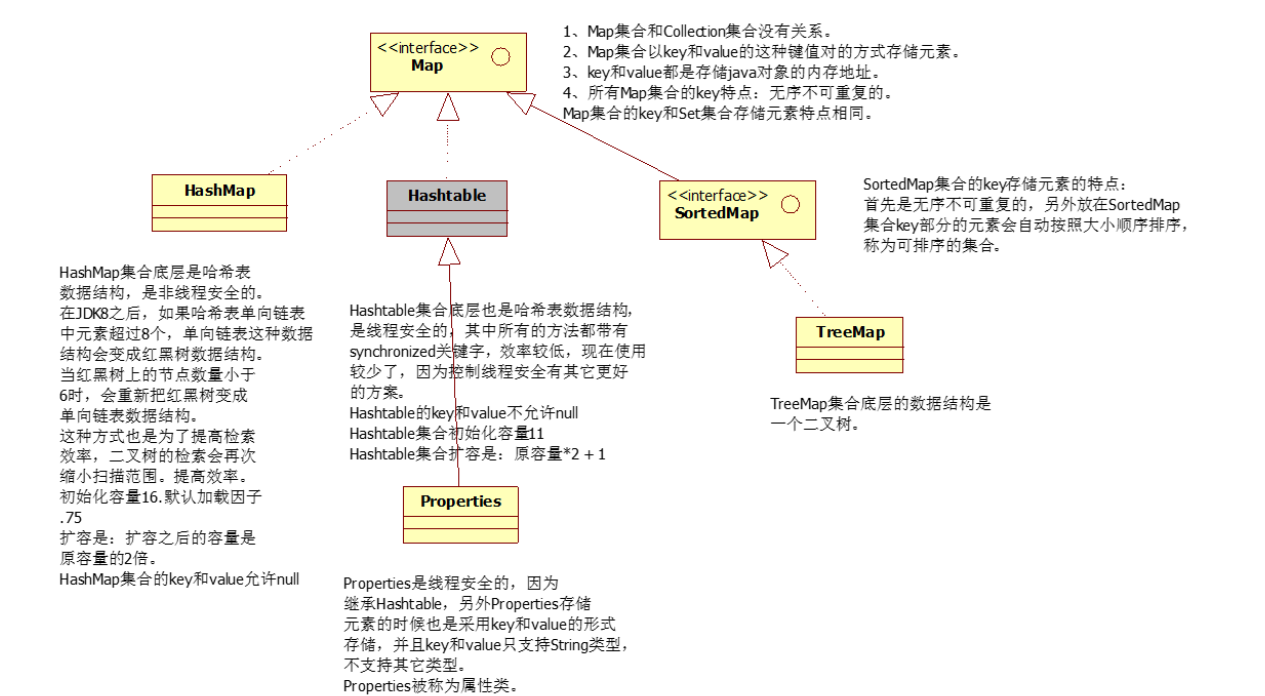
1. 集合和数组的区别
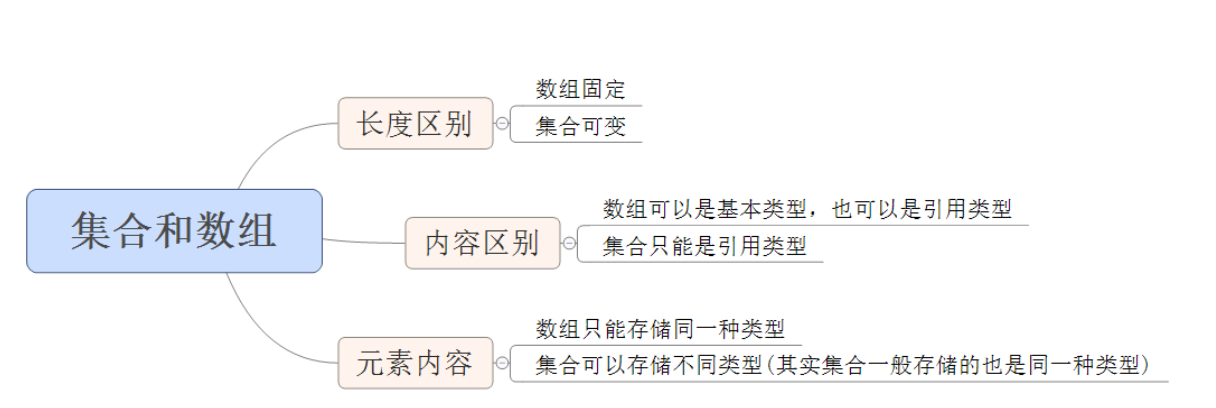
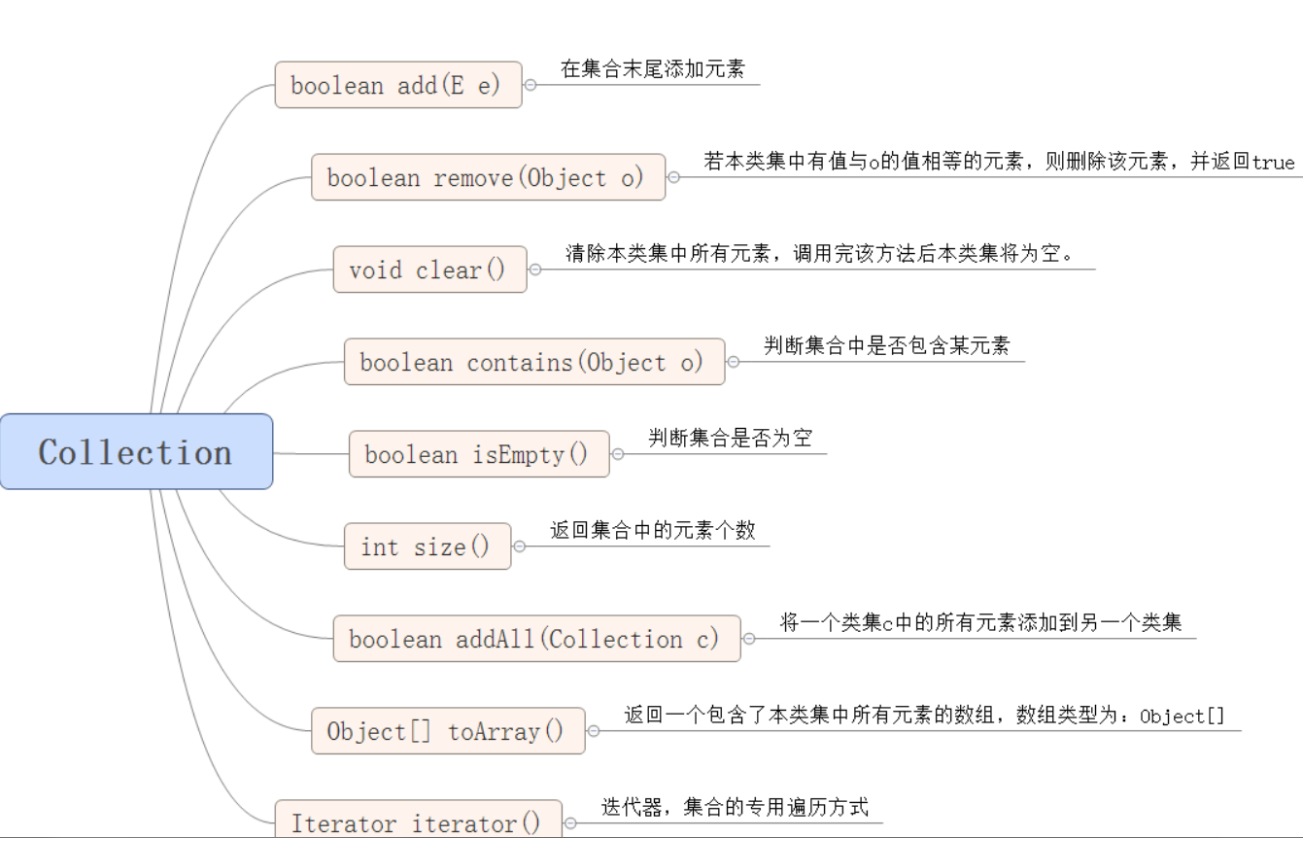
-
常用集合的分类:
Collection 接口的接口 对象的集合(单列集合)
——>>>List 接口:元素按进入先后有序保存,可重复
——>>> LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
——>>> ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
——>>> Vector 接口实现类 数组, 同步, 线程安全
——>>> Stack 是Vector类的实现类
——>>> Set 接口: 仅接收一次,不可重复,并做内部排序
——>>> └HashSet 使用hash表(数组)存储元素
——>>> LinkedHashSet 链表维护元素的插入次序
——>>> TreeSet 底层实现为二叉树,元素排好序Map 接口 键值对的集合 (双列集合)
——>>> Hashtable 接口实现类, 同步, 线程安全
——>>> HashMap 接口实现类 ,没有同步, 线程不安全-
——>>> LinkedHashMap 双向链表和哈希表实现
——>>> WeakHashMap
——>>> TreeMap 红黑树对所有的key进行排序
——>>> IdentifyHashMap
二、List和Set集合详解
1.list 和 set的区别:
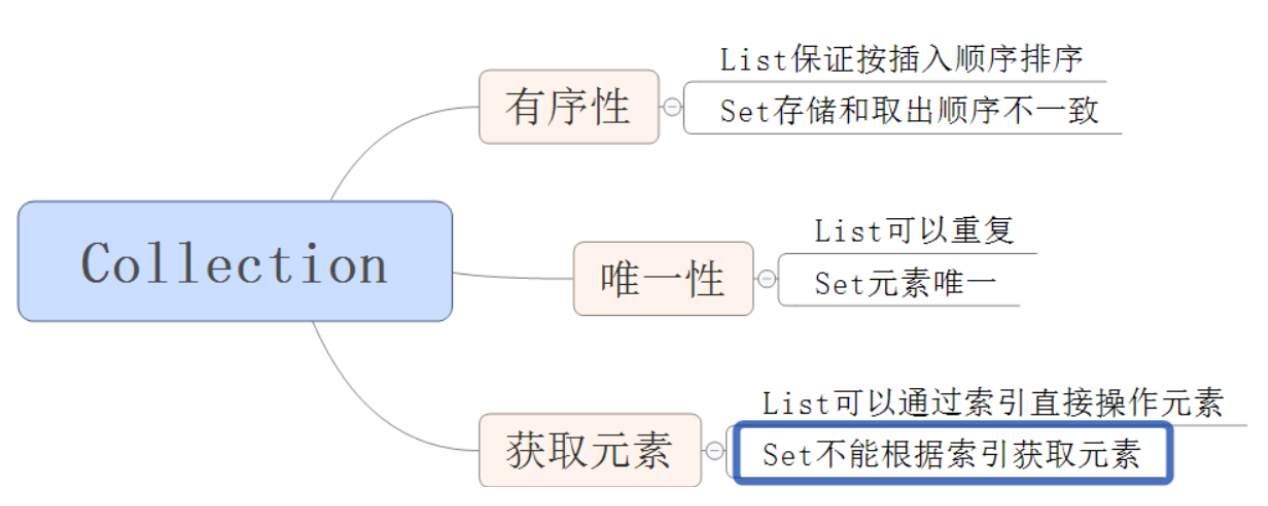
2.List:
- ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
- LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
- Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素

3.Set:
- HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
具体实现唯一性的比较过程:存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
Set的实现类的集合对象中不能够有重复元素,HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。
Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。
Hash算法是一种散列算法。
Set hs=new HashSet();
hs.add(o);
|
o.hashCode();
|
o%当前总容量 (0–15)
|
| 不发生冲突
是否发生冲突—————–直接存放
|
| 发生冲突
| 假(不相等)
o1.equals(o2)——————-找一个空位添加
|
| 是(相等)
不添加覆盖hashCode()方法的原则:
1、一定要让那些我们认为相同的对象返回相同的hashCode值
2、尽量让那些我们认为不同的对象返回不同的hashCode值,否则,就会增加冲突的概率。
3、尽量的让hashCode值散列开(两值用异或运算可使结果的范围更广)
HashSet 的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,我们应该为保存到HashSet中的对象覆盖hashCode()和equals(),因为再将对象加入到HashSet中时,会首先调用hashCode方法计算出对象的hash值,接着根据此hash值调用HashMap中的hash方法,得到的值& (length-1)得到该对象在hashMap的transient Entry[] table中的保存位置的索引,接着找到数组中该索引位置保存的对象,并调用equals方法比较这两个对象是否相等,如果相等则不添加,注意:所以要存入HashSet的集合对象中的自定义类必须覆盖hashCode(),equals()两个方法,才能保证集合中元素不重复。在覆盖equals()和hashCode()方法时, 要使相同对象的hashCode()方法返回相同值,覆盖equals()方法再判断其内容。为了保证效率,所以在覆盖hashCode()方法时, 也要尽量使不同对象尽量返回不同的Hash码值。如果数组中的元素和要加入的对象的hashCode()返回了相同的Hash值(相同对象),才会用equals()方法来判断两个对象的内容是否相同。
-
LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
-
TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
-
小结:Set具有与Collection完全一样的接口,因此没有任何额外的功能,不像前面有两个不同的List。实际上Set就是Collection,只 是行为不同。(这是继承与多态思想的典型应用:表现不同的行为。)Set不保存重复的元素。
Set 存入Set的每个元素都必须是唯一的,因为Set不保存重复元素。加入Set的元素必须定义equals()方法以确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。
4.List和Set总结:
-
List,Set都是继承自Collection接口,Map则不是
-
List特点:元素有放入顺序,元素可重复 ,Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法 ,另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。)
-
.Set和List对比:
Set:
检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:
和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
-
ArrayList与LinkedList的区别和适用场景
Arraylist:优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景
缺点:
因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
ArrayList与Vector的区别和适用场景
ArrayList有三个构造方法:
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。
public ArrayList() //默认构造一个初始容量为10的空列表。
public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表
Vector有四个构造方法:
public Vector()//使用指定的初始容量和等于0的容量增量构造一个空向量。
public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。
public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
ArrayList和Vector都是用数组实现的,主要有这么三个区别:
-
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
-
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
-
Vector可以设置增长因子,而ArrayList不可以。
-
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
适用场景分析:
-
Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
-
如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
-
TreeSet 是二差树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
-
HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束
-
HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例
适用场景分析:
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
5. 何时使用?
请看下面这个图具体分析
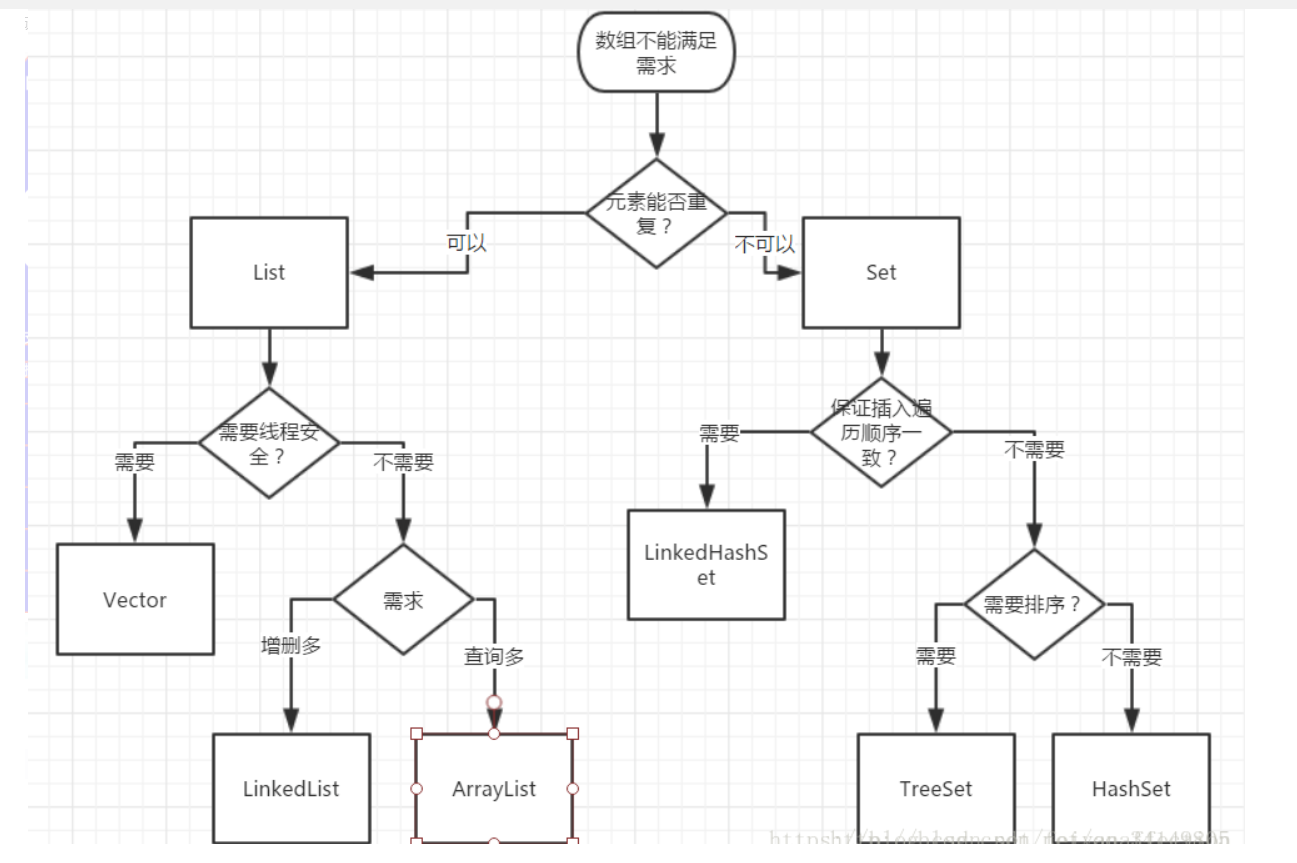
三、Map详解
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。
1. 注意事项:
Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射,你可以通过“键”查找“值”。一个 Map 中不能包含相同的 key ,每个 key 只能映射一个 value 。 Map 接口提供 3 种集合的视图, Map 的内容可以被当作一组 key 集合,一组 value 集合,或者一组 key-value 映射。
2.Map:
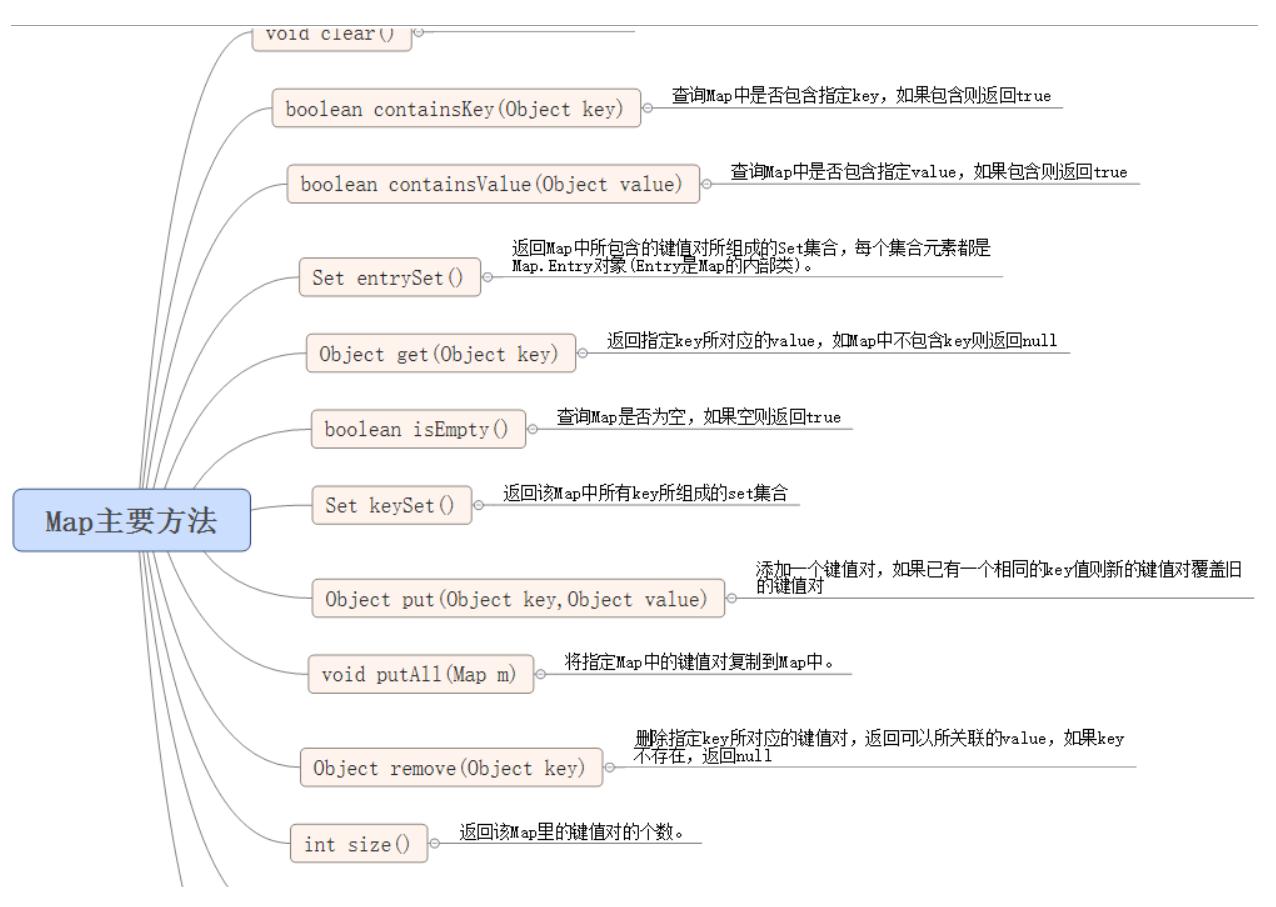
3. HashMap和HashTable的比较:
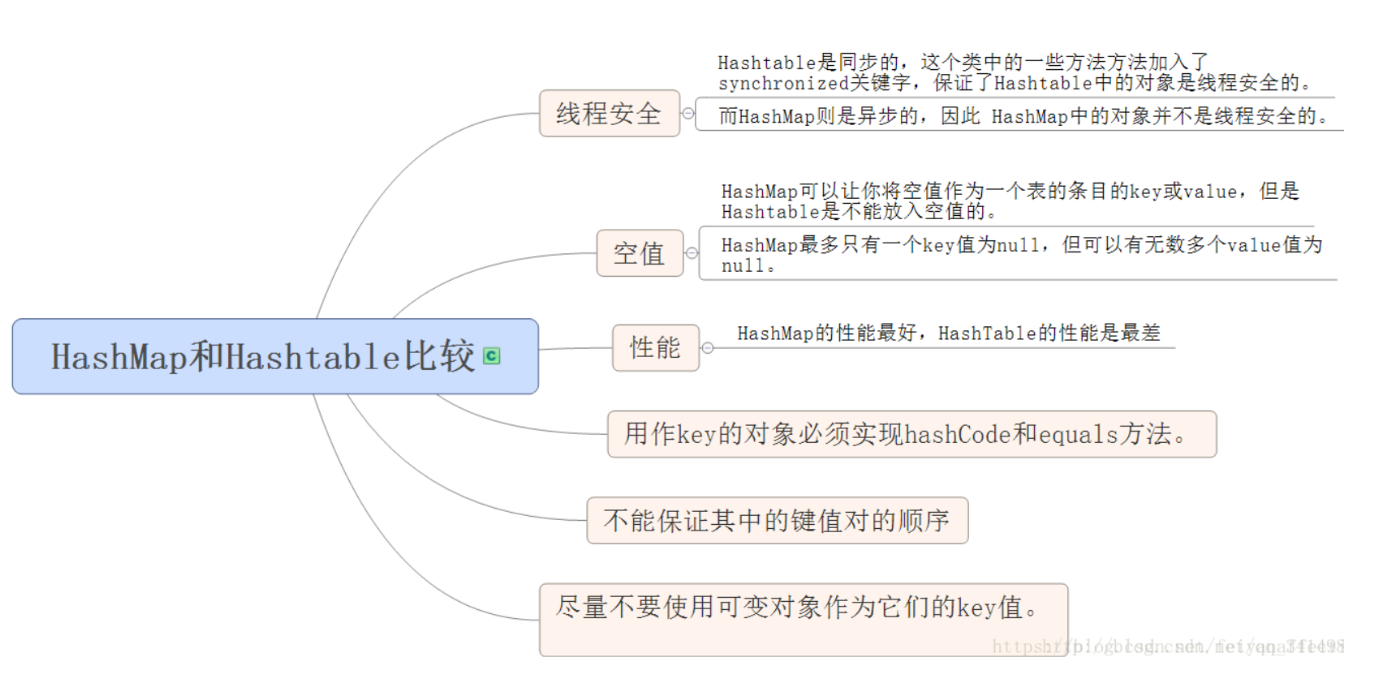
4. TreeMap:

5. Map的其他类:
IdentityHashMap和HashMap的具体区别,IdentityHashMap使用 == 判断两个key是否相等,而HashMap使用的是equals方法比较key值。有什么区别呢?
对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等; 如果作用于引用类型的变量,则比较的是所指向的对象的地址。
对于equals方法,注意:equals方法不能作用于基本数据类型的变量
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。

6. 小结:
HashMap 非线程安全
HashMap:基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
适用场景分析:
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
7. 其他小结:
线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
JavaIO流
一、初始IO流
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
Java 中是通过流处理IO 的,那么什么是流?
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
一般来说关于流的特性有下面几点:
-
先进先出:最先写入输出流的数据最先被输入流读取到。
-
顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外)
-
只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
IO流分类
IO流主要的分类方式有以下3种:
-
按数据流的方向:输入流、输出流
-
按处理数据单位:字节流、字符流
-
按功能:节点流、处理流
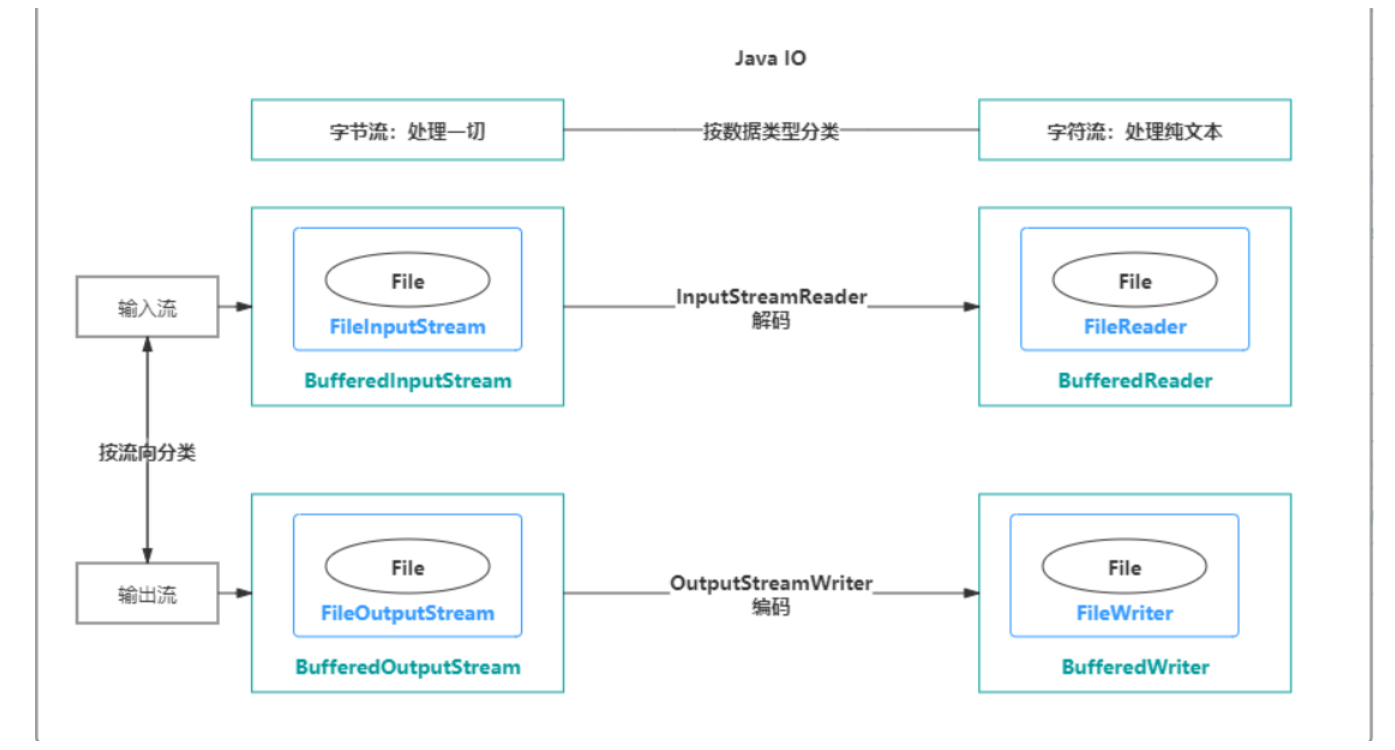
1. 输入输出流
输入与输出是相对于程序而言的,比如文件的读写,读取文件就是输入流 ;写文件就是输出流,这点很容易记混!

2. 字节流与字符流
字节流和字符流的用法几乎一样,区别于字节流和字符流的所操作的数据单元不一样,字节流操作的数据单元是8位的字节,而字符流操作的数据单元是16位的字符
为什么要有字符流?
Java中字符是采用Unicode标准,Unicode 编码中,一个英文字母或一个中文汉字为两个字节。
而在UTF-8编码中,一个中文字符是3个字节。例如下面图中,“云深不知处”5个中文对应的是15个字节:-28-70-111-26-73-79-28-72-115-25-97-91-27-92-124
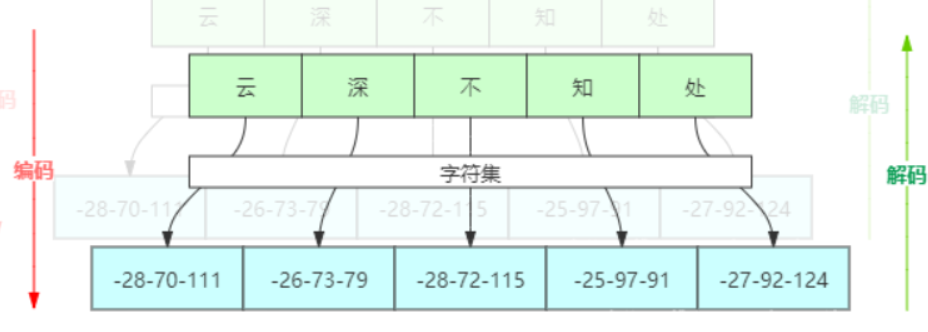
那么问题来了,如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java就推出了字符流。
字节流和字符流的其他区别:
-
字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
-
字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。详见文末效率对比。
以写文件为例,我们查看字符流的源码,发现确实有利用到缓冲区:
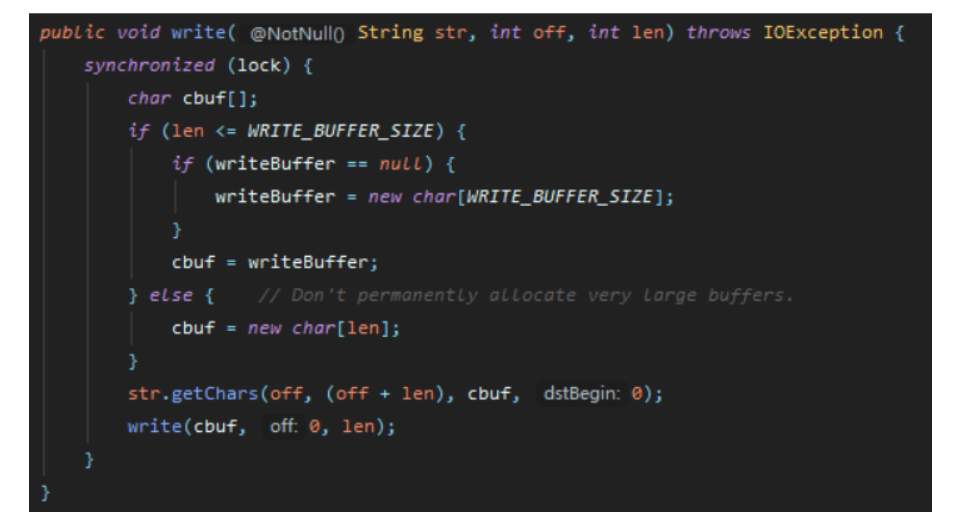
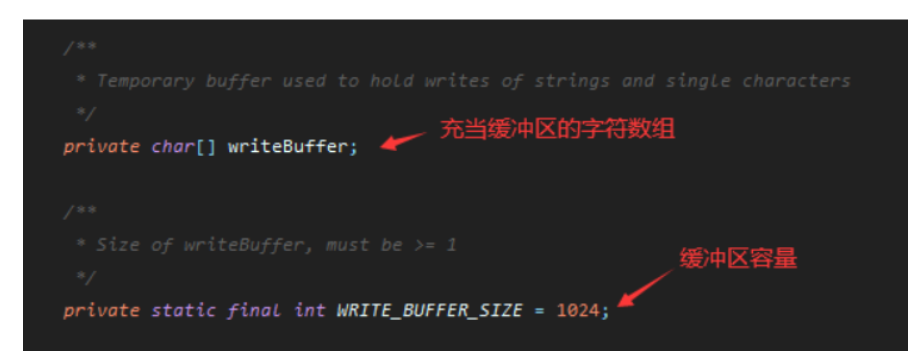
3、节点流和处理流
节点流:直接操作数据读写的流类,比如FileInputStream
处理流(也叫包装流):对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream(缓冲字节流)
处理流和节点流应用了Java的装饰者设计模式。
下图就很形象地描绘了节点流和处理流,处理流是对节点流的封装,最终的数据处理 还是由节点流完成的。
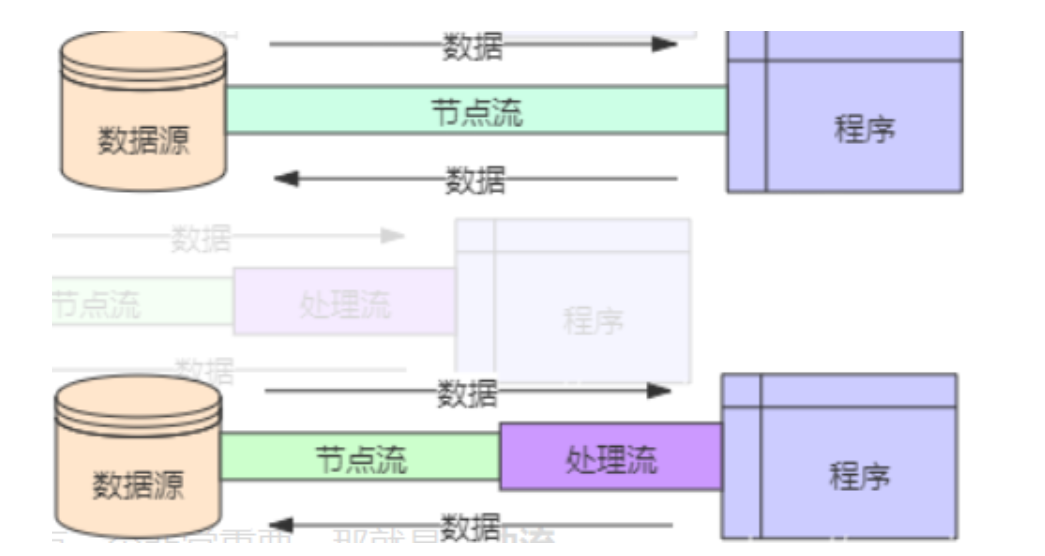
在诸多处理流中,有一个非常重要,那就是缓冲流。
我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过提高每次交互的数据量,减少了交互次数。
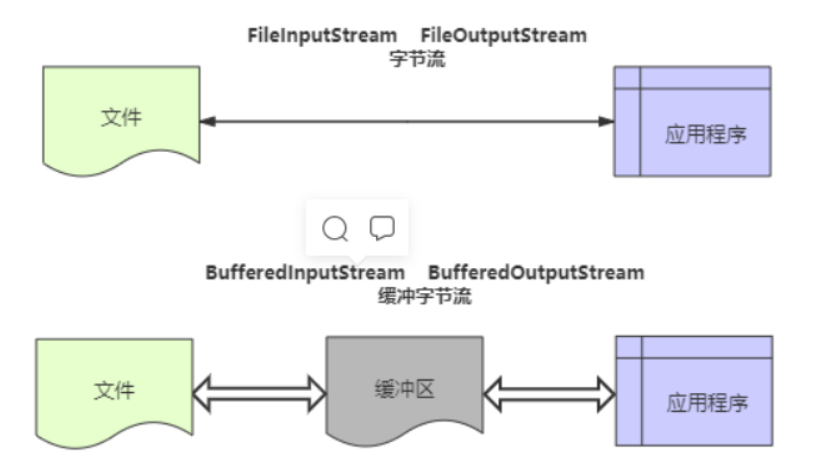
联想一下生活中的例子,我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。
需要注意的是,缓冲流效率一定高吗?不一定,某些情形下,缓冲流效率反而更低,具体请见IO流效率对比。
完整的IO分类图如下:
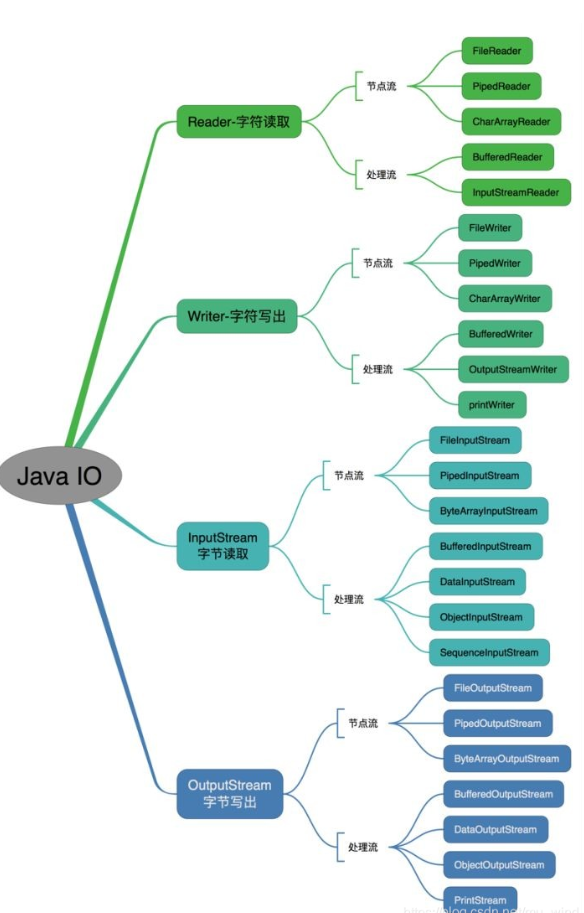
案例实操
接下来,我们看看如何使用Java IO。
文本读写的例子,也就是文章开头所说的,将“松下问童子,言师采药去。只在此山中,云深不知处。”写入本地文本,然后再从文件读取内容并输出到控制台。
1、FileInputStream、FileOutputStream(字节流)
字节流的方式效率较低,不建议使用
public class IOTest {public static void main(String[] args) throws IOException {File file = new File("D:/test.txt");write(file);System.out.println(read(file));}public static void write(File file) throws IOException {OutputStream os = new FileOutputStream(file, true);// 要写入的字符串String string = "松下问童子,言师采药去。只在此山中,云深不知处。";// 写入文件os.write(string.getBytes());// 关闭流os.close();}public static String read(File file) throws IOException {InputStream in = new FileInputStream(file);// 一次性取多少个字节byte[] bytes = new byte[1024];// 用来接收读取的字节数组StringBuilder sb = new StringBuilder();// 读取到的字节数组长度,为-1时表示没有数据int length = 0;// 循环取数据while ((length = in.read(bytes)) != -1) {// 将读取的内容转换成字符串sb.append(new String(bytes, 0, length));}// 关闭流in.close();return sb.toString();}
}2、BufferedInputStream、BufferedOutputStream(缓冲字节流)
缓冲字节流是为高效率而设计的,真正的读写操作还是靠
FileOutputStream和FileInputStream,所以其构造方法入参是这两个类的对象也就不奇怪了。
public class IOTest {public static void write(File file) throws IOException {// 缓冲字节流,提高了效率BufferedOutputStream bis = new BufferedOutputStream(new FileOutputStream(file, true));// 要写入的字符串String string = "松下问童子,言师采药去。只在此山中,云深不知处。";// 写入文件bis.write(string.getBytes());// 关闭流bis.close();}public static String read(File file) throws IOException {BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));// 一次性取多少个字节byte[] bytes = new byte[1024];// 用来接收读取的字节数组StringBuilder sb = new StringBuilder();// 读取到的字节数组长度,为-1时表示没有数据int length = 0;// 循环取数据while ((length = fis.read(bytes)) != -1) {// 将读取的内容转换成字符串sb.append(new String(bytes, 0, length));}// 关闭流fis.close();return sb.toString();}
}3、InputStreamReader、OutputStreamWriter(字符流)
字符流适用于文本文件的读写,
OutputStreamWriter类其实也是借助FileOutputStream类实现的,故其构造方法是FileOutputStream的对象
public class IOTest {public static void write(File file) throws IOException {// OutputStreamWriter可以显示指定字符集,否则使用默认字符集OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(file, true), "UTF-8");// 要写入的字符串String string = "松下问童子,言师采药去。只在此山中,云深不知处。";osw.write(string);osw.close();}public static String read(File file) throws IOException {InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");// 字符数组:一次读取多少个字符char[] chars = new char[1024];// 每次读取的字符数组先append到StringBuilder中StringBuilder sb = new StringBuilder();// 读取到的字符数组长度,为-1时表示没有数据int length;// 循环取数据while ((length = isr.read(chars)) != -1) {// 将读取的内容转换成字符串sb.append(chars, 0, length);}// 关闭流isr.close();return sb.toString()}
}
4、字符流便捷类
Java提供了
FileWriter和FileReader简化字符流的读写,new FileWriter等同于new OutputStreamWriter(new FileOutputStream(file, true))
public class IOTest {public static void write(File file) throws IOException {FileWriter fw = new FileWriter(file, true);// 要写入的字符串String string = "松下问童子,言师采药去。只在此山中,云深不知处。";fw.write(string);fw.close();}public static String read(File file) throws IOException {FileReader fr = new FileReader(file);// 一次性取多少个字节char[] chars = new char[1024];// 用来接收读取的字节数组StringBuilder sb = new StringBuilder();// 读取到的字节数组长度,为-1时表示没有数据int length;// 循环取数据while ((length = fr.read(chars)) != -1) {// 将读取的内容转换成字符串sb.append(chars, 0, length);}// 关闭流fr.close();return sb.toString();}
}5、BufferedReader、BufferedWriter(字符缓冲流)
public class IOTest {public static void write(File file) throws IOException {// BufferedWriter fw = new BufferedWriter(new OutputStreamWriter(new// FileOutputStream(file, true), "UTF-8"));// FileWriter可以大幅度简化代码BufferedWriter bw = new BufferedWriter(new FileWriter(file, true));// 要写入的字符串String string = "松下问童子,言师采药去。只在此山中,云深不知处。";bw.write(string);bw.close();}public static String read(File file) throws IOException {BufferedReader br = new BufferedReader(new FileReader(file));// 用来接收读取的字节数组StringBuilder sb = new StringBuilder();// 按行读数据String line;// 循环取数据while ((line = br.readLine()) != null) {// 将读取的内容转换成字符串sb.append(line);}// 关闭流br.close();return sb.toString();}
}二、IO流对象
第一节中,我们大致了解了IO,并完成了几个案例,但对IO还缺乏更详细的认知,那么接下来我们就对Java IO细细分解,梳理出完整的知识体系来。
Java种提供了40多个类,我们只需要详细了解一下其中比较重要的就可以满足日常应用了。
File类
File类是用来操作文件的类,但它不能操作文件中的数据。
public class File extends Object implements Serializable, Comparable<File>
File类实现了Serializable、 Comparable<File>,说明它是支持序列化和排序的。
File类的构造方法
| 方法名 | 说明 |
|---|---|
| File(File parent, String child) | 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 |
| File(String pathname) | 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 |
| File(String parent, String child) | 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。 |
| File(URI uri) | 通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例。 |
File类的常用方法
| 方法 | 说明 |
|---|---|
| createNewFile() | 当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。 |
| delete() | 删除此抽象路径名表示的文件或目录。 |
| exists() | 测试此抽象路径名表示的文件或目录是否存在。 |
| getAbsoluteFile() | 返回此抽象路径名的绝对路径名形式。 |
| getAbsolutePath() | 返回此抽象路径名的绝对路径名字符串。 |
| length() | 返回由此抽象路径名表示的文件的长度。 |
| mkdir() | 创建此抽象路径名指定的目录。 |
File类使用实例
public class FileTest {public static void main(String[] args) throws IOException {File file = new File("C:/Mu/fileTest.txt");// 判断文件是否存在if (!file.exists()) {// 不存在则创建file.createNewFile();}System.out.println("文件的绝对路径:" + file.getAbsolutePath());System.out.println("文件的大小:" + file.length());// 刪除文件file.delete();}
}字节流
InputStream与OutputStream是两个抽象类,是字节流的基类,所有具体的字节流实现类都是分别继承了这两个类。
以InputStream为例,它继承了Object,实现了Closeable
public abstract class InputStream
extends Object
implements Closeable
InputStream类有很多的实现子类,下面列举了一些比较常用的:
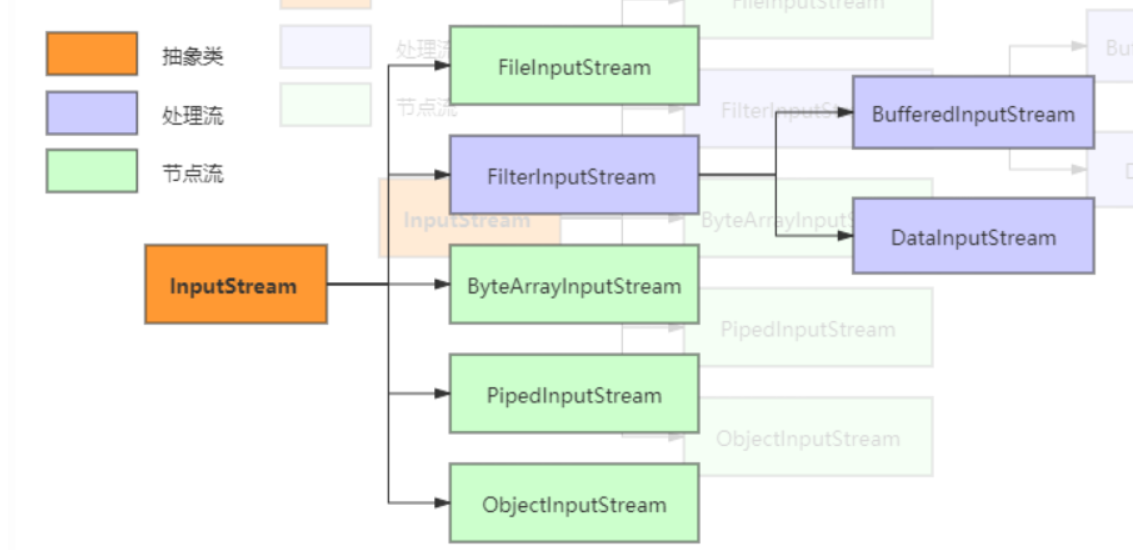
详细说明一下上图中的类:
-
InputStream:InputStream是所有字节输入流的抽象基类,前面说过抽象类不能被实例化,实际上是作为模板而存在的,为所有实现类定义了处理输入流的方法。
-
FileInputSream:文件输入流,一个非常重要的字节输入流,用于对文件进行读取操作。
-
PipedInputStream:管道字节输入流,能实现多线程间的管道通信
-
ByteArrayInputStream:字节数组输入流,从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去。
-
FilterInputStream:装饰者类,具体的装饰者继承该类,这些类都是处理类,作用是对节点类进行封装,实现一些特殊功能。
-
DataInputStream:数据输入流,它是用来装饰其它输入流,作用是“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
-
BufferedInputStream:缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。
-
ObjectInputStream:对象输入流,用来提供对基本数据或对象的持久存储。通俗点说,也就是能直接传输对象,通常应用在反序列化中。它也是一种处理流,构造器的入参是一个InputStream的实例对象。
OutputStream类继承关系图:
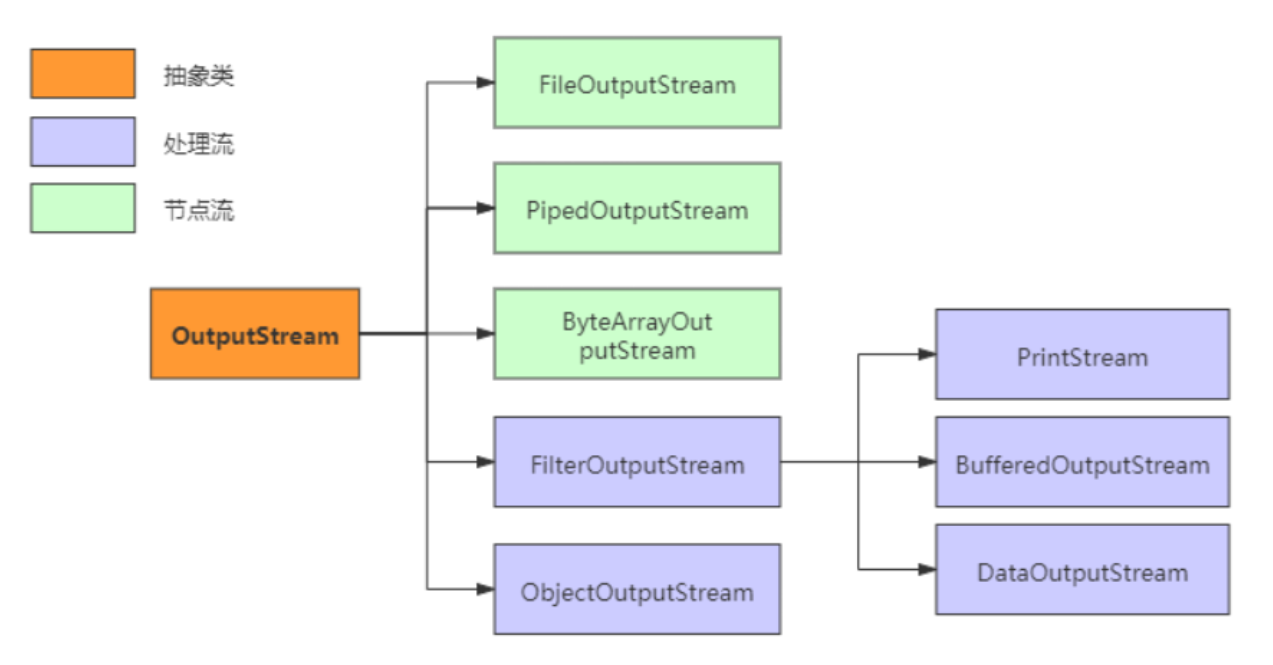
OutputStream类继承关系与InputStream类似,需要注意的是PrintStream.
字符流
与字节流类似,字符流也有两个抽象基类,分别是Reader和Writer。其他的字符流实现类都是继承了这两个类。
以Reader为例,它的主要实现子类如下图:
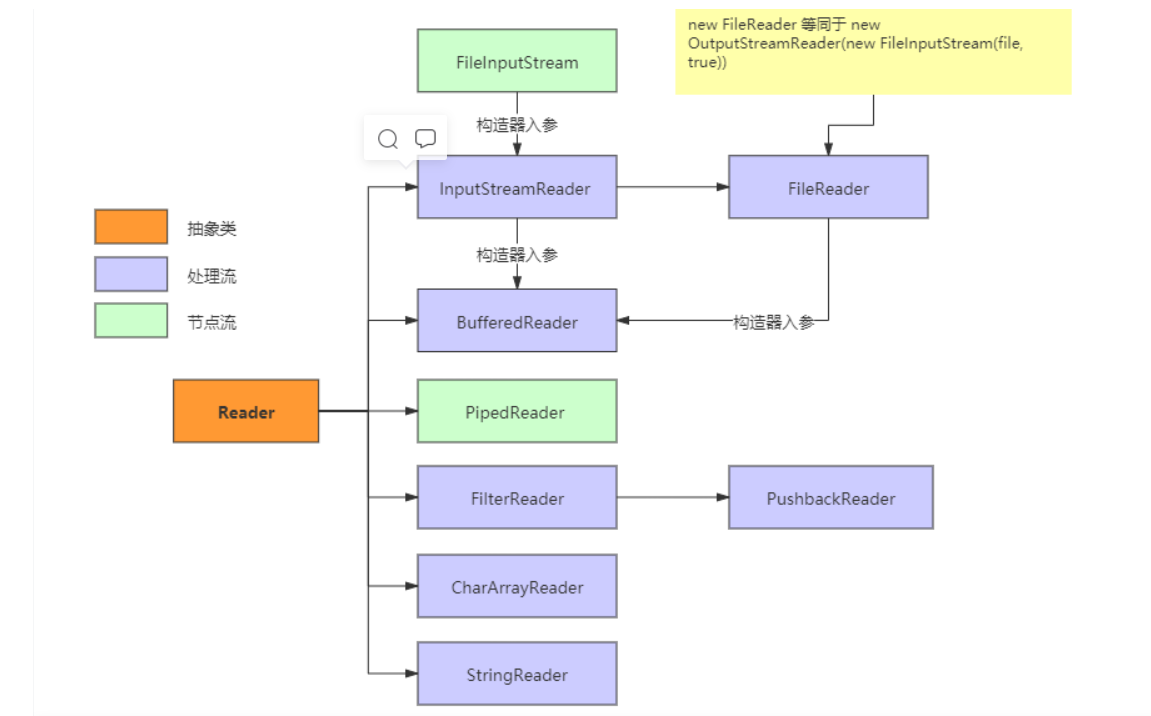
各个类的详细说明:
-
InputStreamReader:从字节流到字符流的桥梁(InputStreamReader构造器入参是FileInputStream的实例对象),它读取字节并使用指定的字符集将其解码为字符。它使用的字符集可以通过名称指定,也可以显式给定,或者可以接受平台的默认字符集。
-
BufferedReader:从字符输入流中读取文本,设置一个缓冲区来提高效率。BufferedReader是对InputStreamReader的封装,前者构造器的入参就是后者的一个实例对象。
-
FileReader:用于读取字符文件的便利类,new FileReader(File file)等同于new InputStreamReader(new FileInputStream(file, true),“UTF-8”),但FileReader不能指定字符编码和默认字节缓冲区大小。
-
PipedReader :管道字符输入流。实现多线程间的管道通信。
-
CharArrayReader:从Char数组中读取数据的介质流。
-
StringReader :从String中读取数据的介质流。
Writer与Reader结构类似,方向相反,不再赘述。唯一有区别的是,Writer的子类PrintWriter。
序列化
待续
IO流方法
字节流方法
字节输入流InputStream主要方法:
-
read() :从此输入流中读取一个数据字节。
-
read(byte[] b) :从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。
-
read(byte[] b, int off, int len) :从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
-
close():关闭此输入流并释放与该流关联的所有系统资源。
字节输出流OutputStream主要方法:
-
write(byte[] b) :将 b.length 个字节从指定 byte 数组写入此文件输出流中。
-
write(byte[] b, int off, int len) :将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此文件输出流。
-
write(int b) :将指定字节写入此文件输出流。
-
close() :关闭此输入流并释放与该流关联的所有系统资源。
字符流方法
字符输入流Reader主要方法:
-
read():读取单个字符。
-
read(char[] cbuf) :将字符读入数组。
-
read(char[] cbuf, int off, int len) : 将字符读入数组的某一部分。
-
read(CharBuffer target) :试图将字符读入指定的字符缓冲区。
-
flush() :刷新该流的缓冲。
-
close() :关闭此流,但要先刷新它。
字符输出流Writer主要方法:
-
write(char[] cbuf) :写入字符数组。
-
write(char[] cbuf, int off, int len) :写入字符数组的某一部分。
-
write(int c) :写入单个字符。
-
write(String str) :写入字符串。
-
write(String str, int off, int len) :写入字符串的某一部分。
-
flush() :刷新该流的缓冲。
-
close() :关闭此流,但要先刷新它。
另外,字符缓冲流还有两个独特的方法:
BufferedWriter类newLine():写入一个行分隔符。这个方法会自动适配所在系统的行分隔符。BufferedReader类readLine():读取一个文本行。
附加内容
位、字节、字符
字节(Byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位。
字符(Character)计算机中使用的字母、数字、字和符号,比如’A’、‘B’、’$’、’&'等。
一般在英文状态下一个字母或字符占用一个字节,一个汉字用两个字节表示。
字节与字符:
-
ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
-
UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。
-
Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
-
符号:英文标点为一个字节,中文标点为两个字节。例如:英文句号 . 占1个字节的大小,中文句号 。占2个字节的大小。
-
UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)。
-
UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。
IO流效率相比
public class MyTest {public static void main(String[] args) throws IOException {File file = new File("C:/Mu/test.txt");StringBuilder sb = new StringBuilder();for (int i = 0; i < 3000000; i++) {sb.append("abcdefghigklmnopqrstuvwsyz");}byte[] bytes = sb.toString().getBytes();long start = System.currentTimeMillis();write(file, bytes);long end = System.currentTimeMillis();long start2 = System.currentTimeMillis();bufferedWrite(file, bytes);long end2 = System.currentTimeMillis();System.out.println("普通字节流耗时:" + (end - start) + " ms");System.out.println("缓冲字节流耗时:" + (end2 - start2) + " ms");}// 普通字节流public static void write(File file, byte[] bytes) throws IOException {OutputStream os = new FileOutputStream(file);os.write(bytes);os.close();}// 缓冲字节流public static void bufferedWrite(File file, byte[] bytes) throws IOException {BufferedOutputStream bo = new BufferedOutputStream(new FileOutputStream(file));bo.write(bytes);bo.close();} }运行结果:
普通字节流耗时:250 ms 缓冲字节流耗时:268 ms这个结果让我大跌眼镜,不是说好缓冲流效率很高么?要知道为什么,只能去源码里找答案了。翻看字节缓冲流的
write方法:public synchronized void write(byte b[], int off, int len) throws IOException {if (len >= buf.length) {/* If the request length exceeds the size of the output buffer,flush the output buffer and then write the data directly.In this way buffered streams will cascade harmlessly. */flushBuffer();out.write(b, off, len);return;}if (len > buf.length - count) {flushBuffer();}System.arraycopy(b, off, buf, count, len);count += len; }注释里说得很明白:如果请求长度超过输出缓冲区的大小,刷新输出缓冲区,然后直接写入数据。这样,缓冲流将无害地级联。
但是,至于为什么这么设计,我没有想明白,有哪位明白的大佬可以留言指点一下。
基于上面的情形,要想对比普通字节流和缓冲字节流的效率差距,就要避免直接读写较长的字符串,于是,设计了下面这个对比案例:用字节流和缓冲字节流分别复制文件。
public class MyTest {public static void main(String[] args) throws IOException {File data = new File("C:/Mu/data.zip");File a = new File("C:/Mu/a.zip");File b = new File("C:/Mu/b.zip");StringBuilder sb = new StringBuilder();long start = System.currentTimeMillis();copy(data, a);long end = System.currentTimeMillis();long start2 = System.currentTimeMillis();bufferedCopy(data, b);long end2 = System.currentTimeMillis();System.out.println("普通字节流耗时:" + (end - start) + " ms");System.out.println("缓冲字节流耗时:" + (end2 - start2) + " ms");}// 普通字节流public static void copy(File in, File out) throws IOException {// 封装数据源InputStream is = new FileInputStream(in);// 封装目的地OutputStream os = new FileOutputStream(out);int by = 0;while ((by = is.read()) != -1) {os.write(by);}is.close();os.close();}// 缓冲字节流public static void bufferedCopy(File in, File out) throws IOException {// 封装数据源BufferedInputStream bi = new BufferedInputStream(new FileInputStream(in));// 封装目的地BufferedOutputStream bo = new BufferedOutputStream(new FileOutputStream(out));int by = 0;while ((by = bi.read()) != -1) {bo.write(by);}bo.close();bi.close();}
}
运行结果:
普通字节流耗时:184867 ms
缓冲字节流耗时:752 ms
这次,普通字节流和缓冲字节流的效率差异就很明显了,达到了245倍。
再看看字符流和缓冲字符流的效率对比:
public class IOTest {public static void main(String[] args) throws IOException {// 数据准备dataReady();File data = new File("C:/Mu/data.txt");File a = new File("C:/Mu/a.txt");File b = new File("C:/Mu/b.txt");File c = new File("C:/Mu/c.txt");long start = System.currentTimeMillis();copy(data, a);long end = System.currentTimeMillis();long start2 = System.currentTimeMillis();copyChars(data, b);long end2 = System.currentTimeMillis();long start3 = System.currentTimeMillis();bufferedCopy(data, c);long end3 = System.currentTimeMillis();System.out.println("普通字节流1耗时:" + (end - start) + " ms,文件大小:" + a.length() / 1024 + " kb");System.out.println("普通字节流2耗时:" + (end2 - start2) + " ms,文件大小:" + b.length() / 1024 + " kb");System.out.println("缓冲字节流耗时:" + (end3 - start3) + " ms,文件大小:" + c.length() / 1024 + " kb");}// 普通字符流不使用数组public static void copy(File in, File out) throws IOException {Reader reader = new FileReader(in);Writer writer = new FileWriter(out);int ch = 0;while ((ch = reader.read()) != -1) {writer.write((char) ch);}reader.close();writer.close();}// 普通字符流使用字符流public static void copyChars(File in, File out) throws IOException {Reader reader = new FileReader(in);Writer writer = new FileWriter(out);char[] chs = new char[1024];while ((reader.read(chs)) != -1) {writer.write(chs);}reader.close();writer.close();}// 缓冲字符流public static void bufferedCopy(File in, File out) throws IOException {BufferedReader br = new BufferedReader(new FileReader(in));BufferedWriter bw = new BufferedWriter(new FileWriter(out));String line = null;while ((line = br.readLine()) != null) {bw.write(line);bw.newLine();bw.flush();}// 释放资源bw.close();br.close();}// 数据准备public static void dataReady() throws IOException {StringBuilder sb = new StringBuilder();for (int i = 0; i < 600000; i++) {sb.append("abcdefghijklmnopqrstuvwxyz");}OutputStream os = new FileOutputStream(new File("C:/Mu/data.txt"));os.write(sb.toString().getBytes());os.close();System.out.println("完毕");}
}
运行结果:
普通字符流1耗时:1337 ms,文件大小:15234 kb
普通字符流2耗时:82 ms,文件大小:15235 kb
缓冲字符流耗时:205 ms,文件大小:15234 kb
测试多次,结果差不多,可见字符缓冲流效率上并没有明显提高,我们更多的是要使用它的readLine()和newLine()方法。
Java多线程
引言
什么是进程,线程?
进程:
资源分配最小的单位,cpu从磁盘中读取一段程序到内存中,该执行程序的实例就叫做进程。一个程序如果被cpu多次读取到内存中,则变成多个独立的进程。
线程 :
线程是程序执行的最小单位,在一个进程中可以有多个不同的线程。
线程的应用实例:
同一个应用程序中(进程),更好的并行处理。
例子:手写一个文本编辑器需要多少个线程?
为什么需要使用多线程?
采用多线程的形式执行代码,目的是为了提高程序开发的效率。
串行、并行的区别
CPU分时间片交替执行,宏观并行,微观串行,由OS负责调度。如今的CPU已经发展到了多核CPU,真正存在并行。
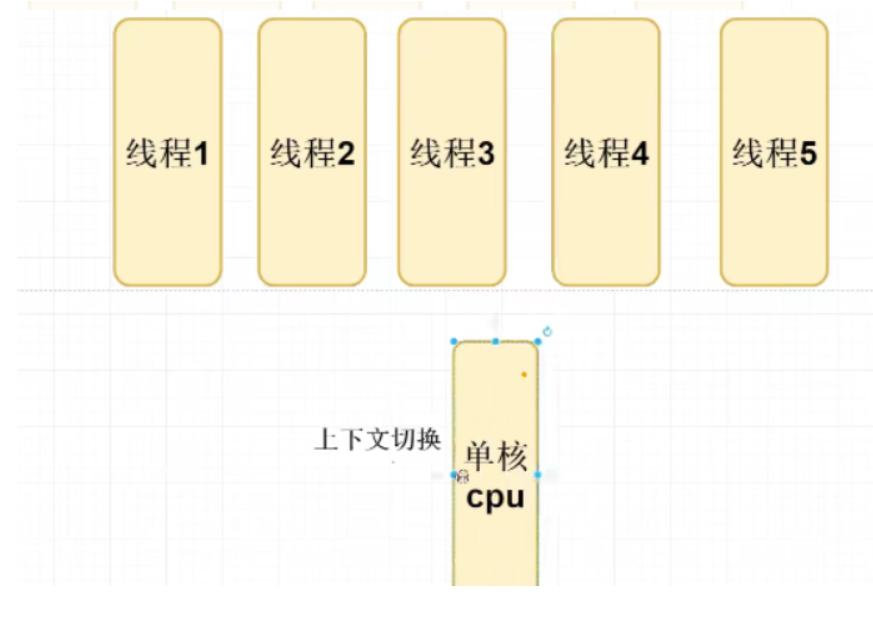
CPU调度算法
多线程是不是一定提高效率? 不一定,需要了解cpu调度的算法。
CPU调度算法:
如果在生产环境中,开启很多线程,但是我们的服务器核数很低,我们这么多线程会在cpu上做上下文切换,反而会降低效率。
使用线程池来限制线程数和cpu数相同会比较好。
一、Java多线程基础
创建线程的方式
- 继承
Thread类创建线程 - 实现
Runnable接口创建线程 - 使用匿名内部类形式创建线程
- 使用
Lambda表达式创建 - 使用
Callable和Future创建线程 - 使用线程池创建
- Spring中的
@Async创建
下面我们一一举例:
1.继承Thread类创建线程
public class ThreadTest extends Thread{@Overridepublic void run() {for (int i = 0; i < 10; i++) {System.out.println("子线程,线程一");}}/* 创建对象进入初始状态,调用start()进入就绪状态。直接调用run()方法,相当于在main中执行run。并不是新线程*/public static void main(String[] args) {ThreadTest t = new ThreadTest();//这里调用start方法启动线程t.start();}
}
2.实现Runnable接口创建线程
public class ThreadTest02 {public static void main(String[] args) {
// 创建线程对象Thread t = new Thread(new Thread01());// 开启线程t.start();}
}
class Thread01 implements Runnable{/*** 这里实现父接口Runnable的run方法*/@Overridepublic void run() {
// 获取当前线程的名字System.out.println(Thread.currentThread().getName() + "我是一个分支线程");}
}3.使用匿名内部类形式创建线程
public class ThreadTest03 {public static void main(String[] args) {
// 这里使用匿名对象去实现Rnnable接口Thread t = new Thread(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName() +"我是一个分支接口");}});t.start();}
}
4.使用Lambda表达式创建
public class Thread02 {public static void main(String[] args) {new Thread(() -> System.out.println(Thread.currentThread().getName()+"我是子线程")).start();}
}
5.使用Callable和 Future创建线程
Runnable的缺点:
1. run没有返回值
2. 不能抛异常Callable接口允许线程有返回值,也允许线程抛出异常
Future接口用来接受返回值
public class Thread03 implements Callable<Integer> {/*** 当前线程需要执行的代码,返回结果* @return 1* @throws Exception*/@Overridepublic Integer call() throws Exception {System.out.println(Thread.currentThread().getName()+"返回1");return 1;}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {Thread03 callable = new Thread03();FutureTask<Integer> integerFutureTask = new FutureTask<Integer>(callable);new Thread(integerFutureTask).start();//通过api获取返回结果,主线程需要等待子线程返回结果Integer result = integerFutureTask.get();System.out.println(Thread.currentThread().getName()+","+result); // main,1
}
6.使用线程池创建
public class ThreadExecutor {public static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();executorService.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"我是子线程1");}});executorService.submit(new Thread03()); //submit一个线程到线程池}
}
7.Spring中的@Async创建
第一步:在入口类中开启异步注解
@SpringBootApplication
@EnableAsync
第二步:在当前方法上加上@Async
@Component
@Slf4j
public class Thread01 {@Asyncpublic void asyncLog(){try {Thread.sleep(3000);log.info("<2>");} catch (InterruptedException e) {e.printStackTrace();}}}
第三步:验证测试
@RestController
@Slf4j
public class Service {@Autowiredprivate Thread01 thread01;@RequestMapping("test")public String Test(){log.info("<1>");thread01.asyncLog();log.info("<3>");return "test";}
}
访问localhost:8080/test查看日志为:

Thread中的常用的方法
1.Thread.currentThread() 方法可以获得当前线程
java中的任何一段代码都是执行在某个线程当中的,执行当前代码的线程就是当前线程。
2.setName()/getName
thread.setName(线程名称) //设置线程名称
thread.getName() //返回线程名称
通过设置线程名称,有助于调试程序,提高程序的可读性,建议为每一个线程设置一个能够体现该线程功能的名称。
3.isAlive()
thread.isAlive() //判断当前线程是否处于活动状态
4.sleep()
Thread.sleep(millis); //让当前线程休眠指定的毫秒数
实例:计时器(一分钟倒计时)
/*** @author 满满* createDate 2022/2/28 13:21* 关于线程的sleep方法:* static void Sleep(long millis)* 1. 静态方法 : Thread.sleep(1000 * 5);* 2. 参数是毫秒* 3. 作用 :让当前线程进入休眠,进入阻塞状态,放弃占有CPU时间片,让其他线程去使用。* 如果这行代码出现在A线程中 A线程就会进入休眠状态* 如果这行代码出现在B线程中 B线程就会进入休眠状态*/public class ThreadTest05 {public static void main(String[] args) {//让当前线程进入休眠状态 睡眠5秒
// 当前线程是主线程/**try {* Thread.sleep(1000 * 5);* } catch (InterruptedException e) {* e.printStackTrace();* }* System.out.println("hell0,world");*/for (int i = 0; i <=20 ; i++) {System.out.println(Thread.currentThread().getName() +" ---->>" + i );try {Thread.sleep( 1000 * 1);} catch (InterruptedException e) {e.printStackTrace();}}}
}
5.getId() java中的线程都有一个唯一编号
6.yield() 放弃当前的cpu资源
Thread.yield(); //可以让线程由运行转为就绪状态
7.setPriority() 设置线程的优先级
thread.setPriority(num); 设置线程的优先级,取值为1-10,如果超过范围会抛出异常 IllegalArugumentExption;优先级越高的线程,获得cpu资源的概率越大。(抢夺的CPU时间片就越多即概率越大)
优先级本质上只是给线程调度器一个提示信息,以便于线程调度器决定先调度哪些线程。不能保证优先级高的线程先运行。
java优先级设置不当,可能导致某些线程永远无法得到运行,产生了线程饥饿。
线程的优先级并不是设置的越高越好,在开发时不必设置线程的优先级。
8.interrupt()中断线程 (Thread中的方法。)
因为interrupt()方法只能中断阻塞过程中的线程而不能中断正在运行过程中的线程。在运行中的线程使用:
注意调用此方法仅仅是在当前线程打一个停止标志,并不是真正的停止线程。
例如在线程1中调用线程b的interrupt(),在b线程中监听b线程的中断标志,来处理结束。
package se.high.thread;/*** @author gaoziman*/public class YieldTest extends Thread {@Overridepublic void run() {for (int i = 1; i < 1000; i++) {// 判断中断标志if (this.isInterrupted()){//如果为true,结束线程//break;return;}System.out.println("thread 1 --->"+i);}}
}
package se.high.thread;/*** @author gaoziman*/public class Test {public static void main(String[] args) {YieldTest t1 = new YieldTest();t1.start(); //开启子线程//当前线程main线程for (int i = 1; i < 100; i++) {System.out.println("main --->" + i);}//打印完main线程中100个后,中断子线程,仅仅是个标记,必须在线程中处理t1.interrupt();}}
9.setDaemon() 守护线程
//线程启动前
thread.setDaemon(true);
thread.start();
Java中的线程分为用户线程与守护线程
守护线程是为其他线程提供服务的线程,如垃圾回收(GC)就是一个典型的守护线程。
守护线程不能单独运行,当jvm中没有其他用户线程,只有守护线程时,守护线程会自动销毁,jvm会自动退出。
线程的状态(线程的生命周期)
**线程的状态: ** getState()
二、线程安全原理篇
多线程的好处:
- 提高了系统的
吞吐量,多线程编程可以使一个进程有多个并发(concurrent)。 - 提高
响应性,服务器会采用一些专门的线程负责用户的请求处理,缩短了用户的等待时间。 充分利用多核处理器资源,通过多线程可以充分的利用CPU资源。
多线程的问题:
线程安全问题,多线程共享数据时,如果没有采取正确的并发访问控制措施,就可能产生数据一致性问题,如读取脏数据(过期的数据),如丢失数据更新。
线程活性(thread liveness)问题。由于程序自身的缺陷或者由资源稀缺性导致的线程一直处于非RUNNABLE状态,这就是线程活性问题。
常见的线程活性问题:
1.死锁 (DeadLock) 鹬蚌相争
2.锁死 (Lockout) 睡美人故事中王子挂啦
3.活锁 (LiveLock) 类似小猫一直咬自己的尾巴,但是咬不到
4.饥饿 (Starvation)类似于健壮的雏鸟总是从母鸟嘴中抢食物。
上下文切换(Context Switch)处理器从执行一个线程切换到执行另外一个线程。
可靠性可能会由一个线程导致JVM意外终止,其他线程也无法执行。线程安全问题
什么是线程安全问题?
当多个线程对同一个对象的实例变量,做写(修改)的操作时,可能会受到其他线程的干扰,发生线程安全的问题。
原子性(Atomic):
不可分割,访问(读,写)某个共享变量的时候,从其他线程来看,该操作要么已经执行完毕,要么尚未发生。其他线程看不到当前操作的中间结果。 访问同一组共享变量的原子操作是不能够交错的,如现实生活中从ATM取款。
java中有两种方式实现原子性:1.锁 :锁具有排他性,可以保证共享变量某一时刻只能被一个线程访问。2.CAS指令 :直接在硬件层次上实现,看做是一个硬件锁。
可见性(visbility):
在多线程环境中,一个线程对某个共享变量更新之后,后续其他的线程可能无法立即读到这个更新的结果。
如果一个线程对共享变量更新之后,后续访问该变量的其他线程可以读到更新的结果,称这个线程对共享变量的更新对其他线程可见。否则称这个线程对共享变量的更新对其他线程不可见。
多线程程序因为可见性问题可能会导致其他线程读取到旧数据(脏数据)。
有序性(Ordering):
是指在什么情况下一个处理器上运行的一个线程所执行的 内存访问操作在另外一个处理器运行的其他线程来看是乱序的(Out of Order)
乱序: 是指内存访问操作的顺序看起来发生了变化。
JVM与JMM
JVM运行时数据区
先谈一下运行时数据区,下面这张图相信大家一点都不陌生:
对于每一个线程来说,栈都是私有的,而堆是共有的。
也就是说在栈中的变量(局部变量、方法定义参数、异常处理器参数)不会在线程之间共享,也就不会有内存可见性(下文会说到)的问题,也不受内存模型的影响。而在堆中的变量是共享的,本文称为共享变量。
所以,内存可见性是针对的共享变量。
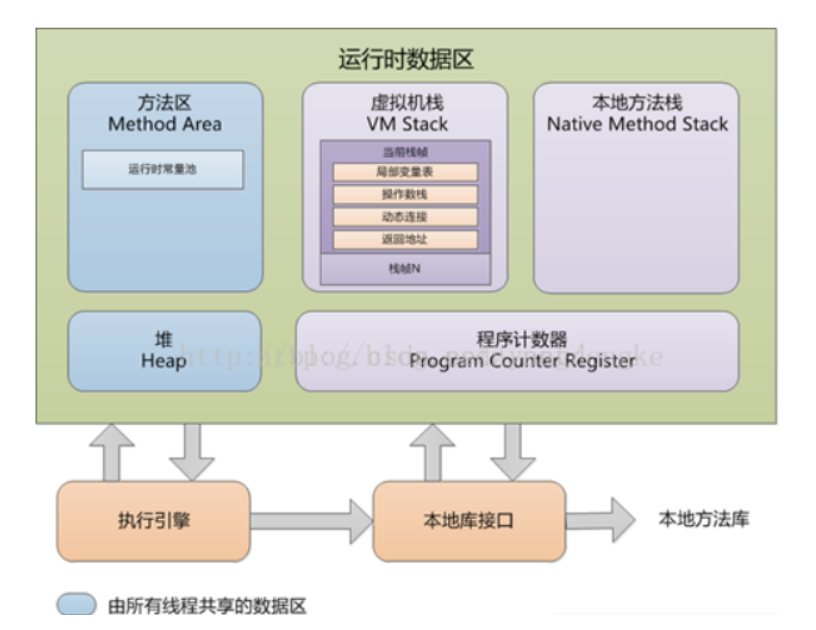
出现线程不安全的例子
public class ThreadCount implements Runnable{private int count =100;@Overridepublic void run() {while(true){if (count>0){count--;System.out.println(Thread.currentThread().getName()+"---->"+count);}}}public static void main(String[] args) {ThreadCount threadCount = new ThreadCount();new Thread(threadCount).start();new Thread(threadCount).start();}
}
如何解决线程安全的问题?
核心思想:上锁
在同一个JVM中,多个线程需要竞争锁的资源,最终只能够有一个线程能够获取到锁,多个线程同时抢一把锁,哪个线程能够获得到锁,谁就可以执行该代码,如果没有获取锁成功,中间需要经历锁的升级过程,如果一直没有获取到锁则会一直阻塞等待。
例如上述情况下如何上锁呢??
public class ThreadCount implements Runnable{private int count =100;@Overridepublic void run() {while(true){synchronized (this){if (count>0){/*线程0 线程1 同时获取this锁,假设线程0 获取到this锁,意味着线程1没有获取到锁则会等待。等线程0执行完count-- 释放锁资源后,就会唤醒线程1 从新进入到获取锁的资源。 获取锁与释放锁全部由虚拟机实现*/count--;System.out.println(Thread.currentThread().getName()+"----"+count);}}}}public static void main(String[] args) {ThreadCount threadCount = new ThreadCount();new Thread(threadCount).start();new Thread(threadCount).start();}
}
三、线程同步
线程同步可以理解为线程之间按照一定的顺序执行。
在我们的线程之间,有一个同步的概念。什么是同步呢,假如我们现在有2位正在抄暑假作业答案的同学:线程A和线程B。当他们正在抄的时候,老师突然来修改了一些答案,可能A和B最后写出的暑假作业就不一样。我们为了A,B能写出2本相同的暑假作业,我们就需要让老师先修改答案,然后A,B同学再抄。或者A,B同学先抄完,老师再修改答案。这就是线程A,线程B的线程同步。
线程安全的产生就是因为多线程之间没有同步,线程同步机制是一套用于协调线程之间的数据访问机制,该机制可以保证线程安全。
Java平台提供的线程机制包括锁,volatile关键字,final关键字,static关键字,以 及相关的API,Objet.wait(); Object.notify()等。
锁的概念
线程安全的问题的产生前提是多个线程并发访问共享数据,将多个线程对共享数据的并发转换为串行访问,即一个共享数据一次只能被一个线程所访问。锁就是通过这种方式来保证线程安全的。
JVM把锁分为内部锁和显示锁两种。内部所通过synchronized关键字实现;显示锁通过java.concurrent.locks.lock接口实现类实现的。
**锁的作用:**锁可以实现对共享数据的安全访问,保障线程的原子性,可见性,与有序性。
- 锁是通过互斥保障原子性,一个锁只能被一个线程所持有的,这就保证临界区代码一次只能被一个线程执行,使得操作不可分割,保证原子性。
- 可见性的保障是通过写线程冲刷处理器的缓存和读线程刷新处理缓存这两个动作实现的。在Java中。锁的获得隐含着刷新处理器缓存的动作,锁的释放隐含着刷新处理器缓存的动作。保证写线程对数据的修改,第一时间推送到刷新处理器的高速缓存中,保证读线程的第一时间可见。
- 锁能够保证有序性,写线程在临界区所执行的临界区看来像是完全按照源码顺序执行的。
注意:使用锁来保证线程的安全性必须满足以下条件:
- 这些线程在访问共享数据时,必须使用同一个锁。
- 这些线程即使仅仅是读共享数据,也需要使用锁。
内部锁:synchronized
java中的每个对象都有一个与之关联的内部锁(这种锁也被称为监视器Monitor),这种锁是一种排他锁,可以保证原子性,可见性,有序性。
所谓``“临界区”,指的是某一块代码区域,它同一时刻只能由一个线程执行。如果synchronized`关键字在方法上,那临界区就是整个方法内部。而如果是使用 synchronized代码块,那临界区就指的是代码块内部的区域。
synchronized的几种使用场景:
1、synchronized修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
synchronized(对象锁){同步代码块,可以在同步代码块中访问共享数据
}
-------------------------------------------------------------------------------
package se.high.thread.intrinsiclock;/*** @author gaoziman* 同步代码块*/public class Test01 {public static void main(String[] args) {//创建两个线程,分别调用mm()方法//先创建Test01对象,通过对象名调用mm()方法Test01 obj = new Test01();new Thread(new Runnable() {@Overridepublic void run() {obj.mm(); //使用的锁对象this就是obj对象}}).start();new Thread(new Runnable() {@Overridepublic void run() {obj.mm(); // 使用的锁对象this就是obj对象}}).start();}//定义一个方法,打印100行字符串public void mm(){//使用this当前对象作为锁对象synchronized (this){for (int i = 0; i <100; i++) {System.out.println(Thread.currentThread().getName()+"---->"+i);}}}
}
2、synchronized修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
package se.high.thread.intrinsiclock;/*** @author 王泽* 同步实例方法,把整个方法体作为同步代码块。* 默认的锁对象是this锁对象。*/public class Test02 {public static void main(String[] args) {//创建两个线程,分别调用mm()方法 mm2Test02 obj = new Test02();new Thread(new Runnable() {@Overridepublic void run() {obj.mm(); //使用的锁对象this就是obj对象}}).start();new Thread(new Runnable() {@Overridepublic void run() {obj.mm2(); // 使用的锁对象this就是obj对象}}).start();}public void mm(){//使用this当前对象作为锁对象synchronized (this){for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName()+"---->"+i);}}}/*** 同步实例方法,同步实例方法,默认this作为锁对象。*/public synchronized void mm2(){for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName()+"--->"+i);}}
}
3、synchronized修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
// 关键字在静态方法上,锁为当前Class对象
public static synchronized void classLock() {// code
}
等价于===
// 关键字在代码块上,锁为括号里面的对象
public void blockLock() {synchronized (this.getClass()) {// code}
}
4、synchronized修饰一个类,其作用的范围是synchronized后面括号括起来的部分,作用的对象是这个类的所有对象。
总结:
同步代码块比同步方法效率更高。
脏读出现的原因是对共享数据的修改与对共享数据的读取不同步。需要对读取数据的代码块同步。
线程出现异常会自动释放锁。
多线程访问同步方法的7种情况
1、两个线程同时访问一个对象的同步方法
答:串行执行
2、两个线程访问的是两个对象的同步方法
答:并行执行,因为两个线程持有的是各自的对象锁,互补影响。
3、两个线程访问的是synchronized的static方法
答:串行执行,持有一个类锁
4、同时访问同步方法和非同步方法
答:并行执行,无论是同一对象还是不同对象,普通方法都不会受到影响
5、访问同一对象的不同的普通同步方法
答:串行执行,持有相同的锁对象
6、同时访问静态的synchronized方法和非静态的synchronized方法
答:并行执行,因为一个是持有的class类锁,一个是持有的是this对象锁,不同的锁,互补干扰。
7、方法抛出异常后,会释放锁
答:synchronized无论是正常结束还是抛出异常后,都会释放锁,而lock必须手动释放锁才可以。
死锁的问题
死锁是这样一种情形:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
java 死锁产生的四个必要条件:
1、互斥使用,即当资源被一个线程使用(占有)时,别的线程不能使用
2、不可抢占,资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占有者主动释放。
3、请求和保持,即当资源请求者在请求其他的资源的同时保持对原有资源的占有。
4、循环等待,即存在一个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就形成了一个等待环路。
当上述四个条件都成立的时候,便形成死锁。当然,死锁的情况下如果打破上述任何一个条件,便可让死锁消失。下面用java代码来模拟一下死锁的产生:
package se.high.thread.intrinsiclock;import javax.security.auth.Subject;/*** @author gaoziman* 演示死锁问题。* 在多线程程序中,同步时可能需要使用多个锁,如果获得锁的顺序不一致,可能会导致死锁。*/public class DeadLock {public static void main(String[] args) {SubThread t1 =new SubThread();t1.setName("a");t1.start();SubThread t2 = new SubThread();t2.setName("b");t2.start();}static class SubThread extends Thread{private static final Object yitian = new Object();private static final Object tulong = new Object();@Overridepublic void run() {if ("a".equals(Thread.currentThread().getName())){synchronized (yitian){System.out.println("a线程获得了倚天剑,爽翻了,再来个屠龙刀就好了...");synchronized (tulong){System.out.println("a线程获得了倚天剑和屠龙刀,直接称霸武林...");}}}if ("b".equals(Thread.currentThread().getName())){synchronized (tulong){System.out.println("b线程获得了屠龙宝刀,得劲,谁也不给....");synchronized (yitian){System.out.println("b线程获得了屠龙后又来把倚天剑....b称霸武林");}}}}}
}
解决死锁:
当需要获得多个锁时,所有线程获得锁的顺序保持一致。
四、线程之间的通信
众所周知线程都有自己的线程栈,那么线程之间是如何保证通信的呢?下面来分析:
等待/通知机制
什么是等待通知机制?
举例:吃自助的时候吃现做的一些饭,放到台子上才能拿。
在单线程编程中,要执行的操作需要满足一定的条件才能执行,可以把这个操作放在if语句块中。
在多线程编程中,可能A线程条件没有满足只是暂时的,稍后其他的线程B可能会更新条件使得A线程的条件得到满足,可以将A线程暂停,直到他的条件得到满足后再将A线程唤醒。
伪代码:
atomic{while(条件不成立){等待}条件满足后当前线程被唤醒,继续执行下面的操作
}
等待通知机制的实现:
Object类中的wait()方法,可以使当前执行代码的线程等待。暂停执行,知道接受到通知或被中断为止。
注意:
- wait()方法只能在同步代码块中由锁对象调用。
- 调用wait()方法后,当前线程会释放锁。
伪代码:
//在调用wait()方法前获得对象的内部锁
synchronized(锁对象){while(条件不成立){//通过锁对象调用wait()方法暂停线程,释放锁对象锁对象.wait();}//线程的条件满足了继续向下执行
}
Object类的 notify()可以唤醒线程,该方法也必须在同步代码块中由锁对象调用。没有使用锁对象调用wait()/notify()会抛出异常。
如果有多个等待的线程,**notify()方法只能唤醒其中的一个,并不会立即释放锁对象。**一般将notify方法放在同步代码块的最后。
伪代码:
synchronized(锁对象){执行修改保护条件的代码唤醒其他线程锁对象.notify();
}
下面我们来看一个了例子:
package se.high.thread.wait;/*** @author 结构化思维wz* 用notify唤醒等待的线程*/public class Test01 {public static void main(String[] args) {String lock = "wzjiayou"; //定义一个字符串作为锁对象Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {synchronized (lock){System.out.println("线程1开始等待-->"+System.currentTimeMillis());try {lock.wait(); //线程等待} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程1结束等待-->"+System.currentTimeMillis());}}});/*** 定义线程2,用来唤醒线程1*/Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {//notify需要在同步代码块中由锁对象调用synchronized (lock){System.out.println("线程2开始唤醒"+System.currentTimeMillis());lock.notify();System.out.println("线程2结束唤醒"+System.currentTimeMillis());}}});t1.start(); //开启t1线程,main线程谁3秒,确保t1等待try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}t2.start();}}
执行结果:
线程1开始等待-->1633345984896
线程2开始唤醒1633345987897
线程2结束唤醒1633345987897
线程1结束等待-->1633345987897进程已结束,退出代码为 0
interrupt()方法会中断wait()
当线程处于wait()等待状态时,调用线程对象的interrupt()方法会中断线程等待状态,会产生InterruptedExceptiont异常。
notify()与notifyAll()
notify()一次只能唤醒一个线程,如果有多个等待的线程,只能随机唤醒其中的某一个;想要唤醒所有的线程,需要调用notifyAll();
wait(long)
如果在参数指定的时间内没有被唤醒,超时后会自动唤醒。
通知过早
线程wait()等待后,可以调用notify()唤醒线程,如果notify()唤醒过早,在等待之前就调用了notify()可能会打乱程序正常的执行逻辑。
在应用中,我们为了保证t1等待后才让t2唤醒。如果t2线程先唤醒,就不让t1等待了。
可以设置一个Boolean变量,通知后设为false,如果为true再等待。
wait() 等待条件发生了变化
在使用wait(),notify(),注意wait条件发生的了变化,也可能导致逻辑的混乱。
*生产者消费者模式
生产者消费者问题(Producer-consumer problem),也称有限缓冲问题(Bounded-buffer problem),是一个多线程同步问题的经典案例。生产者生成一定量的数据放到缓冲区中,然后重复此过程;与此同时,消费者也在缓冲区消耗这些数据。生产者和消费者之间必须保持同步,要保证生产者不会在缓冲区满时放入数据,消费者也不会在缓冲区空时消耗数据。不够完善的解决方法容易出现死锁的情况,此时进程都在等待唤醒。
示意图:
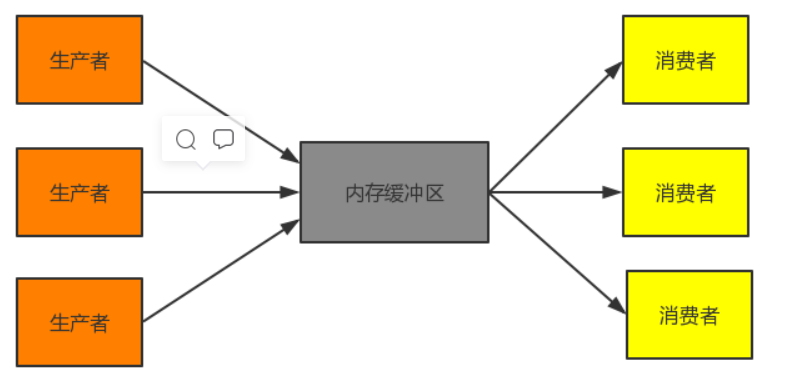
解决思路:
-
采用某种机制保护生产者和消费者之间的同步。有较高的效率,并且易于实现,代码的可控制性较好,属于常用的模式。
-
在生产者和消费者之间建立一个管道。管道缓冲区不易控制,被传输数据对象不易于封装等,实用性不强。
解决问题的核心:
保证同一资源被多个线程并发访问时的完整性。常用的同步方法是采用信号或加锁机制,保证资源在任意时刻至多被一个线程访问。
wait() / notify()方法
当缓冲区已满时,生产者线程停止执行,放弃锁,使自己处于等待状态,让其他线程执行;
当缓冲区已空时,消费者线程停止执行,放弃锁,使自己处于等待状态,让其他线程执行。
当生产者向缓冲区放入一个产品时,向其他等待的线程发出可执行的通知,同时放弃锁,使自己处于等待状态;
当消费者从缓冲区取出一个产品时,向其他等待的线程发出可执行的通知,同时放弃锁,使自己处于等待状态。
仓库Storage.java
import java.util.LinkedList;public class Storage {
// 仓库容量
private final int MAX_SIZE = 10;
// 仓库存储的载体
private LinkedList<Object> list = new LinkedList<>();public void produce() {synchronized (list) {/*仓库满的情况*/while (list.size() + 1 > MAX_SIZE) {System.out.println("【生产者" + Thread.currentThread().getName()+ "】仓库已满");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}/*生产者生产*/list.add(new Object());System.out.println("【生产者" + Thread.currentThread().getName()+ "】生产一个产品,现库存" + list.size());list.notifyAll();}
}public void consume() {synchronized (list) {/*仓库空了*/while (list.size() == 0) {System.out.println("【消费者" + Thread.currentThread().getName() + "】仓库为空");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}/*消费者消费*/list.remove();System.out.println("【消费者" + Thread.currentThread().getName()+ "】消费一个产品,现库存" + list.size());list.notifyAll();}
}}
生产者:
public class Producer implements Runnable{
private Storage storage;
public Producer(){}
public Producer(Storage storage){this.storage = storage;
}@Override
public void run(){while(true){try{Thread.sleep(1000);storage.produce();}catch (InterruptedException e){e.printStackTrace();}}
}}
消费者
public class Consumer implements Runnable{
private Storage storage;
public Consumer(){}public Consumer(Storage storage){this.storage = storage;
}@Override
public void run(){while(true){try{Thread.sleep(3000);storage.consume();}catch (InterruptedException e){e.printStackTrace();}}
}}
Main:
public class Main {
public static void main(String[] args) {Storage storage = new Storage();Thread p1 = new Thread(new Producer(storage));Thread p2 = new Thread(new Producer(storage));Thread p3 = new Thread(new Producer(storage));Thread c1 = new Thread(new Consumer(storage));Thread c2 = new Thread(new Consumer(storage));Thread c3 = new Thread(new Consumer(storage));p1.start();p2.start();p3.start();c1.start();c2.start();c3.start();
}}
运行结果【生产者p1】生产一个产品,现库存1
【生产者p2】生产一个产品,现库存2
【生产者p3】生产一个产品,现库存3
【生产者p1】生产一个产品,现库存4
【生产者p2】生产一个产品,现库存5
【生产者p3】生产一个产品,现库存6
【生产者p1】生产一个产品,现库存7
【生产者p2】生产一个产品,现库存8
【消费者c1】消费一个产品,现库存7
【生产者p3】生产一个产品,现库存8
【消费者c2】消费一个产品,现库存7
【消费者c3】消费一个产品,现库存6
【生产者p1】生产一个产品,现库存7
【生产者p2】生产一个产品,现库存8
【生产者p3】生产一个产品,现库存9
【生产者p1】生产一个产品,现库存10
【生产者p2】仓库已满
【生产者p3】仓库已满
【生产者p1】仓库已满
【消费者c1】消费一个产品,现库存9
【生产者p1】生产一个产品,现库存10
【生产者p3】仓库已满
。。。。。。以下省略
一个生产者线程运行produce方法,睡眠1s;一个消费者运行一次consume方法,睡眠3s。此次实验过程中,有3个生产者和3个消费者,也就是我们说的多对多的情况。仓库的容量为10,可以看出消费的速度明显慢于生产的速度,符合设定。
注意:
notifyAll()方法可使所有正在等待队列中等待同一共享资源的“全部”线程从等待状态退出,进入可运行状态。此时,优先级最高的哪个线程最先执行,但也有可能是随机执行的,这要取决于JVM虚拟机的实现。即最终也只有一个线程能被运行,上述线程优先级都相同,每次运行的线程都不确定是哪个,后来给线程设置优先级后也跟预期不一样,还是要看JVM的具体实现吧。
join()
join()方法是Thread类的一个实例方法。它的作用是让当前线程陷入“等待”状态,等join的这个线程执行完成后,再继续执行当前线程。
有时候,主线程创建并启动了子线程,如果子线程中需要进行大量的耗时运算,主线程往往将早于子线程结束之前结束。
如果主线程想等待子线程执行完毕后,获得子线程中的处理完的某个数据,就要用到join方法了。(插队)
public class Join {static class ThreadA implements Runnable {@Overridepublic void run() {try {System.out.println("我是子线程,我先睡一秒");Thread.sleep(1000);System.out.println("我是子线程,我睡完了一秒");} catch (InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(new ThreadA());thread.start();thread.join();System.out.println("如果不加join方法,我会先被打出来,加了就不一样了");}
}
注意join()方法有两个重载方法,一个是join(long), 一个是join(long, int)。
实际上,通过源码你会发现,join()方法及其重载方法底层都是利用了wait(long)这个方法。
对于join(long, int),通过查看源码(JDK 1.8)发现,底层并没有精确到纳秒,而是对第二个参数做了简单的判断和处理。
五、Callable与Future
通常来说,我们使用Runnable和Thread来创建一个新的线程。但是它们有一个弊端,就是run方法是没有返回值的。而有时候我们希望开启一个线程去执行一个任务,并且这个任务执行完成后有一个返回值。
JDK提供了Callable接口与Future接口为我们解决这个问题,这也是所谓的“异步”模型。
Callable接口
Callable与Runnable类似,同样是只有一个抽象方法的函数式接口。不同的是,Callable提供的方法是有返回值的,而且支持泛型。
@FunctionalInterface
public interface Callable<V> {V call() throws Exception;
}
那一般是怎么使用Callable的呢?Callable一般是配合线程池工具ExecutorService来使用的。我们会在后续章节解释线程池的使用。这里只介绍ExecutorService可以使用submit方法来让一个Callable接口执行。它会返回一个Future,我们后续的程序可以通过这个Future的get方法得到结果。
这里可以看一个简单的使用demo:
// 自定义Callable
class Task implements Callable<Integer>{@Overridepublic Integer call() throws Exception {// 模拟计算需要一秒Thread.sleep(1000);return 2;}public static void main(String args[]) throws Exception {// 使用ExecutorService executor = Executors.newCachedThreadPool();Task task = new Task();Future<Integer> result = executor.submit(task);// 注意调用get方法会阻塞当前线程,直到得到结果。// 所以实际编码中建议使用可以设置超时时间的重载get方法。System.out.println(result.get()); }
}
输出结果:
2
Future接口
Future接口只有几个比较简单的方法:
public abstract interface Future<V> {public abstract boolean cancel(boolean paramBoolean);public abstract boolean isCancelled();public abstract boolean isDone();public abstract V get() throws InterruptedException, ExecutionException;public abstract V get(long paramLong, TimeUnit paramTimeUnit)throws InterruptedException, ExecutionException, TimeoutException;
}
cancel方法是试图取消一个线程的执行。
注意是试图取消,并不一定能取消成功。因为任务可能已完成、已取消、或者一些其它因素不能取消,存在取消失败的可能。boolean类型的返回值是“是否取消成功”的意思。参数paramBoolean表示是否采用中断的方式取消线程执行。
所以有时候,为了让任务有能够取消的功能,就使用Callable来代替Runnable。如果为了可取消性而使用 Future但又不提供可用的结果,则可以声明 Future<?>形式类型、并返回 null作为底层任务的结果。
FutureTask类
上面介绍了Future接口。这个接口有一个实现类叫FutureTask。FutureTask是实现的RunnableFuture接口的,而RunnableFuture接口同时继承了Runnable接口和Future接口:
public interface RunnableFuture<V> extends Runnable, Future<V> {/*** Sets this Future to the result of its computation* unless it has been cancelled.*/void run();
}
那FutureTask类有什么用?为什么要有一个FutureTask类?前面说到了Future只是一个接口,而它里面的cancel,get,isDone等方法要自己实现起来都是非常复杂的。所以JDK提供了一个FutureTask类来供我们使用。
实例代码:
// 自定义Callable,与上面一样
class Task implements Callable<Integer>{@Overridepublic Integer call() throws Exception {// 模拟计算需要一秒Thread.sleep(1000);return 2;}public static void main(String args[]) throws Exception {// 使用ExecutorService executor = Executors.newCachedThreadPool();FutureTask<Integer> futureTask = new FutureTask<>(new Task());executor.submit(futureTask);System.out.println(futureTask.get());}
}
使用上与第一个Demo有一点小的区别。首先,调用submit方法是没有返回值的。这里实际上是调用的submit(Runnable task)方法,而上面的Demo,调用的是submit(Callable task)方法。
然后,这里是使用FutureTask直接取get取值,而上面的Demo是通过submit方法返回的Future去取值。
在很多高并发的环境下,有可能Callable和FutureTask会创建多次。FutureTask能够在高并发环境下确保任务只执行一次。
反射
一、反射的概述
Java反射机制是实在运行状态中,对于任意一个类,都能够知道这个类的属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取信息以及动态调用对象的方法的功能我们称之为Java反射机制。
想要剖析一个类,必须要获取该类的的字节码文件对象。而剖析使用的就是Class类的方法,所以要先获取一个字节码文件对应的Class类型的对象。
以上的总结就是什么是反射
反射就是把java类中的各种成分映射成一个个的Java对象
例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。
(其实:一个类中这些成员方法、构造方法、在加入类中都有一个类来描述)
如图是类的正常加载过程:反射的原理在与class对象。
熟悉一下加载的时候:Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
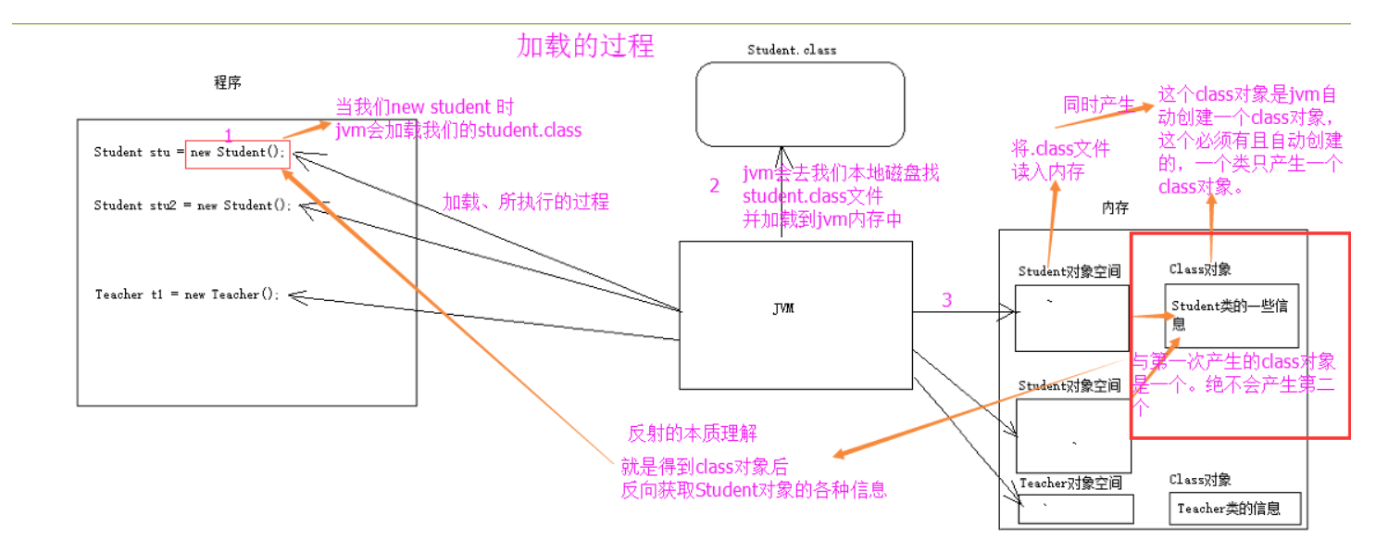
其中这个Class对象很特殊。我们先了解一下这个C lass类
二、查看Class类在Java中api详解(查阅文档)
Class 类的实例表示正在运行的 Java 应用程序中的类和接口。也就是jvm中有N多的实例每个类都有该Class对象。(包括基本数据类型)
Class 没有公共构造方法。Class 对象是在加载类时由 Java 虚拟机以及通过调用类加载器中的defineClass 方法自动构造的。也就是这不需要我们自己去处理创建,JVM已经帮我们创建好了。
没有公共的构造方法,方法共有64个太多了。咱们只需要了解一些常用的即可

三、反射的使用
下面我们来举一个例子:
先写一个Student类。
1、获取Class对象的三种方式
- Object ——> getClass();
- 任何数据类型(包括基本数据类型)都有一个“静态”的class属性
- 通过Class的静态方法:forName(String className)(常用)
其中1.1是因为Object类中的getClass方法、因为所有类都继承Object类。从而调用Object类来获取

package fanshe;
/*** 获取Class对象的三种方式* 1 Object ——> getClass();* 2 任何数据类型(包括基本数据类型)都有一个“静态”的class属性* 3 通过Class类的静态方法:forName(String className)(常用)*/
public class Fanshe {public static void main(String[] args) {//第一种方式获取Class对象 Student stu1 = new Student();//这一new 产生一个Student对象,一个Class对象。Class stuClass = stu1.getClass();//获取Class对象System.out.println(stuClass.getName());//第二种方式获取Class对象Class stuClass2 = Student.class;System.out.println(stuClass == stuClass2);//判断第一种方式获取的Class对象和第二种方式获取的是否是同一个//第三种方式获取Class对象try {Class stuClass3 = Class.forName("fanshe.Student");//注意此字符串必须是真实路径,就是带包名的类路径,包名.类名System.out.println(stuClass3 == stuClass2);//判断三种方式是否获取的是同一个Class对象} catch (ClassNotFoundException e) {e.printStackTrace();}}
}
注意:在运行期间,一个类,只有一个Class对象产生。
三种方式常用第三种,第一种对象都有了还要反射干什么。第二种需要导入类的包,依赖太强,不导包就抛编译错误。一般都第三种,一个字符串可以传入也可写在配置文件中等多种方法。
2、通过反射获取构造方法并使用:
student类:
package fanshe;public class Student {//---------------构造方法-------------------//(默认的构造方法)Student(String str){System.out.println("(默认)的构造方法 s = " + str);}//无参构造方法public Student(){System.out.println("调用了公有、无参构造方法执行了。。。");}//有一个参数的构造方法public Student(char name){System.out.println("姓名:" + name);}//有多个参数的构造方法public Student(String name ,int age){System.out.println("姓名:"+name+"年龄:"+ age);//这的执行效率有问题,以后解决。}//受保护的构造方法protected Student(boolean n){System.out.println("受保护的构造方法 n = " + n);}//私有构造方法private Student(int age){System.out.println("私有的构造方法 年龄:"+ age);}
}
共有6个构造方法;
测试类:
package fanshe;import java.lang.reflect.Constructor;/** 通过Class对象可以获取某个类中的:构造方法、成员变量、成员方法;并访问成员;* * 1.获取构造方法:* 1).批量的方法:* public Constructor[] getConstructors():所有"公有的"构造方法public Constructor[] getDeclaredConstructors():获取所有的构造方法(包括私有、受保护、默认、公有)* 2).获取单个的方法,并调用:* public Constructor getConstructor(Class... parameterTypes):获取单个的"公有的"构造方法:* public Constructor getDeclaredConstructor(Class... parameterTypes):获取"某个构造方法"可以是私有的,或受保护、默认、公有;* * 调用构造方法:* Constructor-->newInstance(Object... initargs)*/
public class Constructors {public static void main(String[] args) throws Exception {//1.加载Class对象Class clazz = Class.forName("fanshe.Student");//2.获取所有公有构造方法System.out.println("**********************所有公有构造方法*********************************");Constructor[] conArray = clazz.getConstructors();for(Constructor c : conArray){System.out.println(c);}System.out.println("************所有的构造方法(包括:私有、受保护、默认、公有)***************");conArray = clazz.getDeclaredConstructors();for(Constructor c : conArray){System.out.println(c);}System.out.println("*****************获取公有、无参的构造方法*******************************");Constructor con = clazz.getConstructor(null);//1>、因为是无参的构造方法所以类型是一个null,不写也可以:这里需要的是一个参数的类型,切记是类型//2>、返回的是描述这个无参构造函数的类对象。System.out.println("con = " + con);//调用构造方法Object obj = con.newInstance();// System.out.println("obj = " + obj);// Student stu = (Student)obj;System.out.println("******************获取私有构造方法,并调用*******************************");con = clazz.getDeclaredConstructor(char.class);System.out.println(con);//调用构造方法con.setAccessible(true);//暴力访问(忽略掉访问修饰符)obj = con.newInstance('男');}}
执行结果:
**********************所有公有构造方法*********************************
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
************所有的构造方法(包括:私有、受保护、默认、公有)***************
private fanshe.Student(int)
protected fanshe.Student(boolean)
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
fanshe.Student(java.lang.String)
*****************获取公有、无参的构造方法*******************************
con = public fanshe.Student()
调用了公有、无参构造方法执行了。。。
******************获取私有构造方法,并调用*******************************
public fanshe.Student(char)
姓名:男
调用方法:
1.获取构造方法:
1).批量的方法:
public Constructor[] getConstructors():所有"公有的"构造方法
public Constructor[] getDeclaredConstructors():获取所有的构造方法(包括私有、受保护、默认、公有)
2).获取单个的方法,并调用:
public Constructor getConstructor(Class… parameterTypes):获取单个的"公有的"构造方法:
public Constructor getDeclaredConstructor(Class… parameterTypes):获取"某个构造方法"可以是私有的,或受保护、默认、公有;
调用构造方法:
Constructor–>newInstance(Object… initargs)
2、 newInstance是 Constructor类的方法(管理构造函数的类)
api的解释为:
newInstance(Object… initargs)
使用此 Constructor 对象表示的构造方法来创建该构造方法的声明类的新实例,并用指定的初始化参数初始化该实例。
它的返回值是T类型,所以newInstance是创建了一个构造方法的声明类的新实例对象。并为之调用
3、获取成员变量并调用
student类:
package fanshe.field;public class Student {public Student(){}//**********字段*************//public String name;protected int age;char sex;private String phoneNum;@Overridepublic String toString() {return "Student [name=" + name + ", age=" + age + ", sex=" + sex+ ", phoneNum=" + phoneNum + "]";}}
测试类:
package fanshe.field;
import java.lang.reflect.Field;
/** 获取成员变量并调用:* * 1.批量的* 1).Field[] getFields():获取所有的"公有字段"* 2).Field[] getDeclaredFields():获取所有字段,包括:私有、受保护、默认、公有;* 2.获取单个的:* 1).public Field getField(String fieldName):获取某个"公有的"字段;* 2).public Field getDeclaredField(String fieldName):获取某个字段(可以是私有的)* * 设置字段的值:* Field --> public void set(Object obj,Object value):* 参数说明:* 1.obj:要设置的字段所在的对象;* 2.value:要为字段设置的值;* */
public class Fields {public static void main(String[] args) throws Exception {//1.获取Class对象Class stuClass = Class.forName("fanshe.field.Student");//2.获取字段System.out.println("************获取所有公有的字段********************");Field[] fieldArray = stuClass.getFields();for(Field f : fieldArray){System.out.println(f);}System.out.println("************获取所有的字段(包括私有、受保护、默认的)********************");fieldArray = stuClass.getDeclaredFields();for(Field f : fieldArray){System.out.println(f);}System.out.println("*************获取公有字段**并调用***********************************");Field f = stuClass.getField("name");System.out.println(f);//获取一个对象Object obj = stuClass.getConstructor().newInstance();//产生Student对象--》Student stu = new Student();//为字段设置值f.set(obj, "刘德华");//为Student对象中的name属性赋值--》stu.name = "刘德华"//验证Student stu = (Student)obj;System.out.println("验证姓名:" + stu.name);System.out.println("**************获取私有字段****并调用********************************");f = stuClass.getDeclaredField("phoneNum");System.out.println(f);f.setAccessible(true);//暴力反射,解除私有限定f.set(obj, "18888889999");System.out.println("验证电话:" + stu);}}
执行结果:
************获取所有公有的字段********************
public java.lang.String fanshe.field.Student.name
************获取所有的字段(包括私有、受保护、默认的)********************
public java.lang.String fanshe.field.Student.name
protected int fanshe.field.Student.age
char fanshe.field.Student.sex
private java.lang.String fanshe.field.Student.phoneNum
*************获取公有字段**并调用***********************************
public java.lang.String fanshe.field.Student.name
验证姓名:刘德华
**************获取私有字段****并调用********************************
private java.lang.String fanshe.field.Student.phoneNum
验证电话:Student [name=刘德华, age=0, sex=
由此可见
调用字段时:需要传递两个参数:
Object obj = stuClass.getConstructor().newInstance();//产生Student对象–》Student stu = new Student();
//为字段设置值
f.set(obj, “刘德华”);//为Student对象中的name属性赋值–》stu.name = “刘德华”
第一个参数:要传入设置的对象,第二个参数:要传入实参
4、获取成员方法并调用
student类:
package fanshe.method;public class Student {//**************成员方法***************//public void show1(String s){System.out.println("调用了:公有的,String参数的show1(): s = " + s);}protected void show2(){System.out.println("调用了:受保护的,无参的show2()");}void show3(){System.out.println("调用了:默认的,无参的show3()");}private String show4(int age){System.out.println("调用了,私有的,并且有返回值的,int参数的show4(): age = " + age);return "abcd";}
}
测试类:
package fanshe.method;import java.lang.reflect.Method;/** 获取成员方法并调用:* * 1.批量的:* public Method[] getMethods():获取所有"公有方法";(包含了父类的方法也包含Object类)* public Method[] getDeclaredMethods():获取所有的成员方法,包括私有的(不包括继承的)* 2.获取单个的:* public Method getMethod(String name,Class<?>... parameterTypes):* 参数:* name : 方法名;* Class ... : 形参的Class类型对象* public Method getDeclaredMethod(String name,Class<?>... parameterTypes)* * 调用方法:* Method --> public Object invoke(Object obj,Object... args):* 参数说明:* obj : 要调用方法的对象;* args:调用方式时所传递的实参;
):*/
public class MethodClass {public static void main(String[] args) throws Exception {//1.获取Class对象Class stuClass = Class.forName("fanshe.method.Student");//2.获取所有公有方法System.out.println("***************获取所有的”公有“方法*******************");stuClass.getMethods();Method[] methodArray = stuClass.getMethods();for(Method m : methodArray){System.out.println(m);}System.out.println("***************获取所有的方法,包括私有的*******************");methodArray = stuClass.getDeclaredMethods();for(Method m : methodArray){System.out.println(m);}System.out.println("***************获取公有的show1()方法*******************");Method m = stuClass.getMethod("show1", String.class);System.out.println(m);//实例化一个Student对象Object obj = stuClass.getConstructor().newInstance();m.invoke(obj, "刘德华");System.out.println("***************获取私有的show4()方法******************");m = stuClass.getDeclaredMethod("show4", int.class);System.out.println(m);m.setAccessible(true);//解除私有限定Object result = m.invoke(obj, 20);//需要两个参数,一个是要调用的对象(获取有反射),一个是实参System.out.println("返回值:" + result);}
}
执行结果:
***************获取所有的”公有“方法*******************
public void fanshe.method.Student.show1(java.lang.String)
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
***************获取所有的方法,包括私有的*******************
public void fanshe.method.Student.show1(java.lang.String)
private java.lang.String fanshe.method.Student.show4(int)
protected void fanshe.method.Student.show2()
void fanshe.method.Student.show3()
***************获取公有的show1()方法*******************
public void fanshe.method.Student.show1(java.lang.String)
调用了:公有的,String参数的show1(): s = 刘德华
***************获取私有的show4()方法******************
private java.lang.String fanshe.method.Student.show4(int)
调用了,私有的,并且有返回值的,int参数的show4(): age = 20
返回值:abcd
由此可见:
m = stuClass.getDeclaredMethod(“show4”, int.class);//调用制定方法(所有包括私有的),需要传入两个参数,第一个是调用的方法名称,第二个是方法的形参类型,切记是类型。
System.out.println(m);
m.setAccessible(true);//解除私有限定
Object result = m.invoke(obj, 20);//需要两个参数,一个是要调用的对象(获取有反射),一个是实参
System.out.println(“返回值:” + result);
执行结果:
***************获取所有的”公有“方法*******************
public void fanshe.method.Student.show1(java.lang.String)
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
***************获取所有的方法,包括私有的*******************
public void fanshe.method.Student.show1(java.lang.String)
private java.lang.String fanshe.method.Student.show4(int)
protected void fanshe.method.Student.show2()
void fanshe.method.Student.show3()
***************获取公有的show1()方法*******************
public void fanshe.method.Student.show1(java.lang.String)
调用了:公有的,String参数的show1(): s = 刘德华
***************获取私有的show4()方法******************
private java.lang.String fanshe.method.Student.show4(int)
调用了,私有的,并且有返回值的,int参数的show4(): age = 20
返回值:abcd
其实这里的成员方法:在模型中有属性一词,就是那些setter()方法和getter()方法。还有字段组成,这些内容在内省中详解
5、反射main方法
student类:
package fanshe.main;public class Student {public static void main(String[] args) {System.out.println("main方法执行了。。。");}
}
测试类:
package fanshe.main;import java.lang.reflect.Method;/*** 获取Student类的main方法、不要与当前的main方法搞混了*/
public class Main {public static void main(String[] args) {try {//1、获取Student对象的字节码Class clazz = Class.forName("fanshe.main.Student");//2、获取main方法Method methodMain = clazz.getMethod("main", String[].class);//第一个参数:方法名称,第二个参数:方法形参的类型,//3、调用main方法// methodMain.invoke(null, new String[]{"a","b","c"});//第一个参数,对象类型,因为方法是static静态的,所以为null可以,第二个参数是String数组,这里要注意在jdk1.4时是数组,jdk1.5之后是可变参数//这里拆的时候将 new String[]{"a","b","c"} 拆成3个对象。。。所以需要将它强转。methodMain.invoke(null, (Object)new String[]{"a","b","c"});//方式一// methodMain.invoke(null, new Object[]{new String[]{"a","b","c"}});//方式二} catch (Exception e) {e.printStackTrace();}}
}
执行结果:
main方法执行了。。。
6、反射方法的其它使用之—通过反射运行配置文件内容
student类:
public class Student {public void show(){System.out.println("is show()");}
}
配置文件以txt文件为例子(pro.txt):
className = cn.fanshe.Student
methodName = show
测试类:
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.Properties;/** 我们利用反射和配置文件,可以使:应用程序更新时,对源码无需进行任何修改* 我们只需要将新类发送给客户端,并修改配置文件即可*/
public class Demo {public static void main(String[] args) throws Exception {//通过反射获取Class对象Class stuClass = Class.forName(getValue("className"));//"cn.fanshe.Student"//2获取show()方法Method m = stuClass.getMethod(getValue("methodName"));//show//3.调用show()方法m.invoke(stuClass.getConstructor().newInstance());}//此方法接收一个key,在配置文件中获取相应的valuepublic static String getValue(String key) throws IOException{Properties pro = new Properties();//获取配置文件的对象FileReader in = new FileReader("pro.txt");//获取输入流pro.load(in);//将流加载到配置文件对象中in.close();return pro.getProperty(key);//返回根据key获取的value值}
}
执行结果:
is show()
需求:
当我们升级这个系统时,不要Student类,而需要新写一个Student2的类时,这时只需要更改pro.txt的文件内容就可以了。代码就一点不用改动
要替换的student2类:
public class Student2 {public void show2(){System.out.println("is show2()");}
}
配置文件更改为:
className = cn.fanshe.Student2
methodName = show2
执行结果:
is show2();
7、反射方法的其它使用之—通过反射越过泛型检查
泛型用在编译期,编译过后泛型擦除(消失掉)。所以是可以通过反射越过泛型检查的
测试类:
import java.lang.reflect.Method;
import java.util.ArrayList;/** 通过反射越过泛型检查* * 例如:有一个String泛型的集合,怎样能向这个集合中添加一个Integer类型的值?*/
public class Demo {public static void main(String[] args) throws Exception{ArrayList<String> strList = new ArrayList<>();strList.add("aaa");strList.add("bbb");// strList.add(100);//获取ArrayList的Class对象,反向的调用add()方法,添加数据Class listClass = strList.getClass(); //得到 strList 对象的字节码 对象//获取add()方法Method m = listClass.getMethod("add", Object.class);//调用add()方法m.invoke(strList, 100);//遍历集合for(Object obj : strList){System.out.println(obj);}}
}
执行结果:
aaa
bbb
100
注解
注解的概述
Annotation 中文译过来就是注解、标释的意思,在 Java 中注解是一个很重要的知识点,但经常还是有点让新手不容易理解。
我个人认为,比较糟糕的技术文档主要特征之一就是:用专业名词来介绍专业名词。
比如:
Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。Java 注解是从 Java5 开始添加到 Java 的。
这是大多数网站上对于 Java 注解,解释确实正确,但是说实在话,我第一次学习的时候,头脑一片空白。这什么跟什么啊?听了像没有听一样。因为概念太过于抽象,所以初学者实在是比较吃力才能够理解,然后随着自己开发过程中不断地强化练习,才会慢慢对它形成正确的认识。
我在写这篇文章的时候,我就在思考。如何让自己或者让读者能够比较直观地认识注解这个概念?是要去官方文档上翻译说明吗?我马上否定了这个答案。
后来,我想到了一样东西————墨水,墨水可以挥发、可以有不同的颜色,用来解释注解正好。
不过,我继续发散思维后,想到了一样东西能够更好地代替墨水,那就是印章。印章可以沾上不同的墨水或者印泥,可以定制印章的文字或者图案,如果愿意它也可以被戳到你任何想戳的物体表面。
但是,我再继续发散思维后,又想到一样东西能够更好地代替印章,那就是标签。标签是一张便利纸,标签上的内容可以自由定义。常见的如货架上的商品价格标签、图书馆中的书本编码标签、实验室中化学材料的名称类别标签等等。
并且,往抽象地说,标签并不一定是一张纸,它可以是对人和事物的属性评价。也就是说,标签具备对于抽象事物的解释。

所以,基于如此,我完成了自我的知识认知升级,我决定用标签来解释注解。
注解如同标签
之前某新闻客户端的评论有盖楼的习惯,于是 “乔布斯重新定义了手机、罗永浩重新定义了傻X” 就经常极为工整地出现在了评论楼层中,并且广大网友在相当长的一段时间内对于这种行为乐此不疲。这其实就是等同于贴标签的行为。
在某些网友眼中,罗永浩就成了傻X的代名词。
广大网友给罗永浩贴了一个名为“傻x”的标签,他们并不真正了解罗永浩,不知道他当教师、砸冰箱、办博客的壮举,但是因为“傻x”这样的标签存在,这有助于他们直接快速地对罗永浩这个人做出评价,然后基于此,罗永浩就可以成为茶余饭后的谈资,这就是标签的力量。
而在网络的另一边,老罗靠他的人格魅力自然收获一大批忠实的拥泵,他们对于老罗贴的又是另一种标签。

我无意于评价这两种行为,我再引个例子。
《奇葩说》是近年网络上非常火热的辩论节目,其中辩手陈铭被另外一个辩手马薇薇攻击说是————“站在宇宙中心呼唤爱”,然后贴上了一个大大的标签————“鸡汤男”,自此以后,观众再看到陈铭的时候,首先映入脑海中便是“鸡汤男”三个大字,其实本身而言陈铭非常优秀,为人师表、作风正派、谈吐举止得体,但是在网络中,因为娱乐至上的环境所致,人们更愿意以娱乐的心态来认知一切,于是“鸡汤男”就如陈铭自己所说成了一个撕不了的标签。
我们可以抽象概括一下,标签是对事物行为的某些角度的评价与解释。
到这里,终于可以引出本文的主角注解了。
初学者可以这样理解注解:想像代码具有生命,注解就是对于代码中某些鲜活个体的贴上去的一张标签。简化来讲,注解如同一张标签。
在未开始学习任何注解具体语法而言,你可以把注解看成一张标签。这有助于你快速地理解它的大致作用。如果初学者在学习过程有大脑放空的时候,请不要慌张,对自己说:
注解,标签。注解,标签。
注解的语法
因为平常开发少见,相信有不少的人员会认为注解的地位不高。其实同 classs 和 interface 一样,注解也属于一种类型。它是在 Java SE 5.0 版本中开始引入的概念。
注解的定义
注解通过 @interface 关键字进行定义。
public @interface TestAnnotation {
}
它的形式跟接口很类似,不过前面多了一个 @ 符号。上面的代码就创建了一个名字为 TestAnnotaion 的注解。
你可以简单理解为创建了一张名字为 TestAnnotation 的标签。
注解的应用
上面创建了一个注解,那么注解的的使用方法是什么呢。
@TestAnnotation
public class Test {
}
创建一个类 Test,然后在类定义的地方加上 @TestAnnotation 就可以用 TestAnnotation 注解这个类了。
你可以简单理解为将 TestAnnotation 这张标签贴到 Test 这个类上面。
不过,要想注解能够正常工作,还需要介绍一下一个新的概念那就是元注解。
元注解
元注解是什么意思呢?
元注解是可以注解到注解上的注解,或者说元注解是一种基本注解,但是它能够应用到其它的注解上面。
如果难于理解的话,你可以这样理解。元注解也是一张标签,但是它是一张特殊的标签,它的作用和目的就是给其他普通的标签进行解释说明的。
元标签有 @Retention、@Documented、@Target、@Inherited、@Repeatable 5 种。
@Retention
Retention 的英文意为保留期的意思。当 @Retention 应用到一个注解上的时候,它解释说明了这个注解的的存活时间。
它的取值如下:
- RetentionPolicy.SOURCE 注解只在源码阶段保留,在编译器进行编译时它将被丢弃忽视。
- RetentionPolicy.CLASS 注解只被保留到编译进行的时候,它并不会被加载到 JVM 中。
- RetentionPolicy.RUNTIME 注解可以保留到程序运行的时候,它会被加载进入到 JVM 中,所以在程序运行时可以获取到它们。
我们可以这样的方式来加深理解,@Retention 去给一张标签解释的时候,它指定了这张标签张贴的时间。@Retention 相当于给一张标签上面盖了一张时间戳,时间戳指明了标签张贴的时间周期。
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {
}
@Documented
顾名思义,这个元注解肯定是和文档有关。它的作用是能够将注解中的元素包含到 Javadoc 中去。
@Target
Target 是目标的意思,@Target 指定了注解运用的地方。
你可以这样理解,当一个注解被 @Target 注解时,这个注解就被限定了运用的场景。
类比到标签,原本标签是你想张贴到哪个地方就到哪个地方,但是因为 @Target 的存在,它张贴的地方就非常具体了,比如只能张贴到方法上、类上、方法参数上等等。@Target 有下面的取值
- ElementType.ANNOTATION_TYPE 可以给一个注解进行注解
- ElementType.CONSTRUCTOR 可以给构造方法进行注解
- ElementType.FIELD 可以给属性进行注解
- ElementType.LOCAL_VARIABLE 可以给局部变量进行注解
- ElementType.METHOD 可以给方法进行注解
- ElementType.PACKAGE 可以给一个包进行注解
- ElementType.PARAMETER 可以给一个方法内的参数进行注解
- ElementType.TYPE 可以给一个类型进行注解,比如类、接口、枚举
@Inherited
Inherited 是继承的意思,但是它并不是说注解本身可以继承,而是说如果一个超类被 @Inherited 注解过的注解进行注解的话,那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解。
说的比较抽象。代码来解释。
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@interface Test {}
@Test
public class A {}
public class B extends A {}
解 Test 被 @Inherited 修饰,之后类 A 被 Test 注解,类 B 继承 A,类 B 也拥有 Test 这个注解。
可以这样理解:
老子非常有钱,所以人们给他贴了一张标签叫做富豪。
老子的儿子长大后,只要没有和老子断绝父子关系,虽然别人没有给他贴标签,但是他自然也是富豪。
老子的孙子长大了,自然也是富豪。
这就是人们口中戏称的富一代,富二代,富三代。虽然叫法不同,好像好多个标签,但其实事情的本质也就是他们有一张共同的标签,也就是老子身上的那张富豪的标签。
@Repeatable
Repeatable 自然是可重复的意思。@Repeatable 是 Java 1.8 才加进来的,所以算是一个新的特性。
什么样的注解会多次应用呢?通常是注解的值可以同时取多个。
举个例子,一个人他既是程序员又是产品经理,同时他还是个画家。
@interface Persons {Person[] value();
}
@Repeatable(Persons.class)
@interface Person{String role default "";
}
@Person(role="artist")
@Person(role="coder")
@Person(role="PM")
public class SuperMan{
}
注意上面的代码,@Repeatable 注解了 Person。而 @Repeatable 后面括号中的类相当于一个容器注解。
什么是容器注解呢?
就是用来存放其它注解的地方。它本身也是一个注解。
我们再看看代码中的相关容器注解。
@interface Persons {Person[] value();
}
按照规定,它里面必须要有一个 value 的属性,属性类型是一个被 @Repeatable 注解过的注解数组,注意它是数组。
如果不好理解的话,可以这样理解。Persons 是一张总的标签,上面贴满了 Person 这种同类型但内容不一样的标签。把 Persons 给一个 SuperMan 贴上,相当于同时给他贴了程序员、产品经理、画家的标签。
我们可能对于 @Person(role=”PM”) 括号里面的内容感兴趣,它其实就是给 Person 这个注解的 role 属性赋值为 PM ,大家不明白正常,马上就讲到注解的属性这一块。
注解的属性
注解的属性也叫做成员变量。注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {int id();String msg();
}
上面代码定义了 TestAnnotation 这个注解中拥有 id 和 msg 两个属性。在使用的时候,我们应该给它们进行赋值。
赋值的方式是在注解的括号内以 value=”” 形式,多个属性之前用 ,隔开。
@TestAnnotation(id=3,msg="hello annotation")
public class Test {
}
需要注意的是,在注解中定义属性时它的类型必须是 8 种基本数据类型外加 类、接口、注解及它们的数组。
注解中属性可以有默认值,默认值需要用 default 关键值指定。比如:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {public int id() default -1;public String msg() default "Hi";
}
TestAnnotation 中 id 属性默认值为 -1,msg 属性默认值为 Hi。
它可以这样应用。
@TestAnnotation()
public class Test {}
因为有默认值,所以无需要再在 @TestAnnotation 后面的括号里面进行赋值了,这一步可以省略。
另外,还有一种情况。如果一个注解内仅仅只有一个名字为 value 的属性时,应用这个注解时可以直接接属性值填写到括号内。
public @interface Check {String value();
}
上面代码中,Check 这个注解只有 value 这个属性。所以可以这样应用。
@Check("hi")
int a;
和这下面的效果是一样的
@Check(value="hi")
int a;
最后,还需要注意的一种情况是一个注解没有任何属性。比如
public @interface Perform {}
那么在应用这个注解的时候,括号都可以省略。
@Perform
public void testMethod(){}
Java 预置的注解
学习了上面相关的知识,我们已经可以自己定义一个注解了。其实 Java 语言本身已经提供了几个现成的注解。
@Deprecated
这个元素是用来标记过时的元素,想必大家在日常开发中经常碰到。编译器在编译阶段遇到这个注解时会发出提醒警告,告诉开发者正在调用一个过时的元素比如过时的方法、过时的类、过时的成员变量。
public class Hero {@Deprecatedpublic void say(){System.out.println("Noting has to say!");}public void speak(){System.out.println("I have a dream!");}
}
定义了一个 Hero 类,它有两个方法 say() 和 speak() ,其中 say() 被 @Deprecated 注解。然后我们在 IDE 中分别调用它们。
可以看到,say() 方法上面被一条直线划了一条,这其实就是编译器识别后的提醒效果。
@Override
这个大家应该很熟悉了,提示子类要复写父类中被 @Override 修饰的方法
@SuppressWarnings
阻止警告的意思。之前说过调用被 @Deprecated 注解的方法后,编译器会警告提醒,而有时候开发者会忽略这种警告,他们可以在调用的地方通过 @SuppressWarnings 达到目的。
@SuppressWarnings("deprecation")
public void test1(){Hero hero = new Hero();hero.say();hero.speak();
}
@SafeVarargs
参数安全类型注解。它的目的是提醒开发者不要用参数做一些不安全的操作,它的存在会阻止编译器产生 unchecked 这样的警告。它是在 Java 1.7 的版本中加入的。
@SafeVarargs // Not actually safe!static void m(List<String>... stringLists) {Object[] array = stringLists;List<Integer> tmpList = Arrays.asList(42);array[0] = tmpList; // Semantically invalid, but compiles without warningsString s = stringLists[0].get(0); // Oh no, ClassCastException at runtime!
}
上面的代码中,编译阶段不会报错,但是运行时会抛出 ClassCastException 这个异常,所以它虽然告诉开发者要妥善处理,但是开发者自己还是搞砸了。
Java 官方文档说,未来的版本会授权编译器对这种不安全的操作产生错误警告。
@FunctionalInterface
函数式接口注解,这个是 Java 1.8 版本引入的新特性。函数式编程很火,所以 Java 8 也及时添加了这个特性。
函数式接口 (Functional Interface) 就是一个具有一个方法的普通接口。
比如
@FunctionalInterface
public interface Runnable {/*** When an object implementing interface <code>Runnable</code> is used* to create a thread, starting the thread causes the object's* <code>run</code> method to be called in that separately executing* thread.* <p>* The general contract of the method <code>run</code> is that it may* take any action whatsoever.** @see java.lang.Thread#run()*/public abstract void run();
}
我们进行线程开发中常用的 Runnable 就是一个典型的函数式接口,上面源码可以看到它就被 @FunctionalInterface 注解。
可能有人会疑惑,函数式接口标记有什么用,这个原因是函数式接口可以很容易转换为 Lambda 表达式。这是另外的主题了,有兴趣的同学请自己搜索相关知识点学习。
注解的提取
博文前面的部分讲了注解的基本语法,现在是时候检测我们所学的内容了。
我通过用标签来比作注解,前面的内容是讲怎么写注解,然后贴到哪个地方去,而现在我们要做的工作就是检阅这些标签内容。 形象的比喻就是你把这些注解标签在合适的时候撕下来,然后检阅上面的内容信息。
要想正确检阅注解,离不开一个手段,那就是反射。
注解与反射
注解通过反射获取。首先可以通过 Class 对象的 isAnnotationPresent() 方法判断它是否应用了某个注解
public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass) {}
然后通过 getAnnotation() 方法来获取 Annotation 对象。
public <A extends Annotation> A getAnnotation(Class<A> annotationClass) {}
或者是 getAnnotations() 方法。
public Annotation[] getAnnotations() {}
前一种方法返回指定类型的注解,后一种方法返回注解到这个元素上的所有注解。
如果获取到的 Annotation 如果不为 null,则就可以调用它们的属性方法了。比如
@TestAnnotation()
public class Test {public static void main(String[] args) {boolean hasAnnotation = Test.class.isAnnotationPresent(TestAnnotation.class);if ( hasAnnotation ) {TestAnnotation testAnnotation = Test.class.getAnnotation(TestAnnotation.class);System.out.println("id:"+testAnnotation.id());System.out.println("msg:"+testAnnotation.msg());}}
}
执行结果:
id:-1
msg:
这个正是 TestAnnotation 中 id 和 msg 的默认值。
上面的例子中,只是检阅出了注解在类上的注解,其实属性、方法上的注解照样是可以的。同样还是要假手于反射。
@TestAnnotation(msg="hello")
public class Test {@Check(value="hi")int a;@Performpublic void testMethod(){}@SuppressWarnings("deprecation")public void test1(){Hero hero = new Hero();hero.say();hero.speak();}public static void main(String[] args) {boolean hasAnnotation = Test.class.isAnnotationPresent(TestAnnotation.class);if ( hasAnnotation ) {TestAnnotation testAnnotation = Test.class.getAnnotation(TestAnnotation.class);//获取类的注解System.out.println("id:"+testAnnotation.id());System.out.println("msg:"+testAnnotation.msg());}try {Field a = Test.class.getDeclaredField("a");a.setAccessible(true);//获取一个成员变量上的注解Check check = a.getAnnotation(Check.class);if ( check != null ) {System.out.println("check value:"+check.value());}Method testMethod = Test.class.getDeclaredMethod("testMethod");if ( testMethod != null ) {// 获取方法中的注解Annotation[] ans = testMethod.getAnnotations();for( int i = 0;i < ans.length;i++) {System.out.println("method testMethod annotation:"+ans[i].annotationType().getSimpleName());}}} catch (NoSuchFieldException e) {// TODO Auto-generated catch blocke.printStackTrace();System.out.println(e.getMessage());} catch (SecurityException e) {// TODO Auto-generated catch blocke.printStackTrace();System.out.println(e.getMessage());} catch (NoSuchMethodException e) {// TODO Auto-generated catch blocke.printStackTrace();System.out.println(e.getMessage());}}
}
执行结果:
id:-1
msg:hello
check value:hi
method testMethod annotation:Perform
需要注意的是,如果一个注解要在运行时被成功提取,那么 @Retention(RetentionPolicy.RUNTIME) 是必须的。
注解的使用场景
我相信博文讲到这里大家都很熟悉了注解,但是有不少同学肯定会问,注解到底有什么用呢?
对啊注解到底有什么用?
我们不妨将目光放到 Java 官方文档上来。
文章开始的时候,我用标签来类比注解。但标签比喻只是我的手段,而不是目的。为的是让大家在初次学习注解时能够不被那些抽象的新概念搞懵。既然现在,我们已经对注解有所了解,我们不妨再仔细阅读官方最严谨的文档。
注解是一系列元数据,它提供数据用来解释程序代码,但是注解并非是所解释的代码本身的一部分。注解对于代码的运行效果没有直接影响。
注解有许多用处,主要如下:
- 提供信息给编译器: 编译器可以利用注解来探测错误和警告信息
- 编译阶段时的处理: 软件工具可以用来利用注解信息来生成代码、Html文档或者做其它相应处理。
- 运行时的处理: 某些注解可以在程序运行的时候接受代码的提取
值得注意的是,注解不是代码本身的一部分。
如果难于理解,可以这样看。罗永浩还是罗永浩,不会因为某些人对于他“傻x”的评价而改变,标签只是某些人对于其他事物的评价,但是标签不会改变事物本身,标签只是特定人群的手段。所以,注解同样无法改变代码本身,注解只是某些工具的的工具。
还是回到官方文档的解释上,注解主要针对的是编译器和其它工具软件(SoftWare tool)。
当开发者使用了Annotation 修饰了类、方法、Field 等成员之后,这些 Annotation 不会自己生效,必须由开发者提供相应的代码来提取并处理 Annotation 信息。这些处理提取和处理 Annotation 的代码统称为 APT(Annotation Processing Tool)。
现在,我们可以给自己答案了,注解有什么用?给谁用?给 编译器或者 APT 用的。
如果,你还是没有搞清楚的话,我亲自写一个好了。
亲手自定义注解完成某个目的
我要写一个测试框架,测试程序员的代码有无明显的异常。
—— 程序员 A : 我写了一个类,它的名字叫做 NoBug,因为它所有的方法都没有错误。
—— 我:自信是好事,不过为了防止意外,让我测试一下如何?
—— 程序员 A: 怎么测试?
—— 我:把你写的代码的方法都加上 @Jiecha 这个注解就好了。
—— 程序员 A: 好的。
package ceshi;
import ceshi.Jiecha;
public class NoBug {@Jiechapublic void suanShu(){System.out.println("1234567890");}@Jiechapublic void jiafa(){System.out.println("1+1="+1+1);}@Jiechapublic void jiefa(){System.out.println("1-1="+(1-1));}@Jiechapublic void chengfa(){System.out.println("3 x 5="+ 3*5);}@Jiechapublic void chufa(){System.out.println("6 / 0="+ 6 / 0);}public void ziwojieshao(){System.out.println("我写的程序没有 bug!");}
}
上面的代码,有些方法上面运用了 @Jiecha 注解。
这个注解是我写的测试软件框架中定义的注解。
package ceshi;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
@Retention(RetentionPolicy.RUNTIME)
public @interface Jiecha {
}
然后,我再编写一个测试类 TestTool 就可以测试 NoBug 相应的方法了。
package ceshi;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class TestTool {public static void main(String[] args) {// TODO Auto-generated method stubNoBug testobj = new NoBug();Class clazz = testobj.getClass();Method[] method = clazz.getDeclaredMethods();//用来记录测试产生的 log 信息StringBuilder log = new StringBuilder();// 记录异常的次数int errornum = 0;for ( Method m: method ) {// 只有被 @Jiecha 标注过的方法才进行测试if ( m.isAnnotationPresent( Jiecha.class )) {try {m.setAccessible(true);m.invoke(testobj, null);} catch (Exception e) {// TODO Auto-generated catch block//e.printStackTrace();errornum++;log.append(m.getName());log.append(" ");log.append("has error:");log.append("\n\r caused by ");//记录测试过程中,发生的异常的名称log.append(e.getCause().getClass().getSimpleName());log.append("\n\r");//记录测试过程中,发生的异常的具体信息log.append(e.getCause().getMessage());log.append("\n\r");} }}log.append(clazz.getSimpleName());log.append(" has ");log.append(errornum);log.append(" error.");// 生成测试报告System.out.println(log.toString());}
}
执行结果:
1234567890
1+1=11
1-1=0
3 x 5=15
chufa has error:caused by ArithmeticException
/ by zero
NoBug has 1 error.
提示 NoBug 类中的 chufa() 这个方法有异常,这个异常名称叫做 ArithmeticException,原因是运算过程中进行了除 0 的操作。
所以,NoBug 这个类有 Bug。
这样,通过注解我完成了我自己的目的,那就是对别人的代码进行测试。
所以,再问我注解什么时候用?我只能告诉你,这取决于你想利用它干什么用。
注解应用实例
注解运用的地方太多了,如:
JUnit 这个是一个测试框架,典型使用方法如下:
public class ExampleUnitTest {@Testpublic void addition_isCorrect() throws Exception {assertEquals(4, 2 + 2);}
}
@Test 标记了要进行测试的方法 addition_isCorrect().
还有例如ssm框架等运用了大量的注解。