地方商城网站上海搜索优化推广
论文笔记 |【AAAI2022】SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
周更博主没有鸽,周更博主回来了(泪
总体而言,这篇文章的理解部分对我有难度,个人认为难点在于超分分支的网络,尽管可以从输入维度入手,推理和考虑网络中的行为和作用,但能感觉到自己总体上对各个网络组成部分的理解还是不够深入。
除此之外,本文符号比较多,出于便捷没有详细标注上标下标,见谅。
你会在很多地方看到fai,这是因为我对于不会读的希腊字母统一读fai(第四声)。

目录
- 论文笔记 |【AAAI2022】SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
- 1 Motivation
- 2 Method
- 着色分支:
- 超分辨率分支:
- 2.1 Pyramid Valve Cross Attention
- VCAttn阀门交叉注意力模块:
- PVCAttn金字塔阀门交叉注意力模块
- 2.2 Continuous Pixel Mapping(CPM)
- 2.3 Objective Functions
- 3 Experiment
- 4 Ablation study
- 5 Conclusion
- Reference
1 Motivation
在一些实际场景(老照片的恢复、灰度手稿的艺术创作)任务中,往往只能获得低分辨率灰度图像(LR)。我们希望得到更具吸引力的高分辨率彩色图像(HR)。
当前解决方法通常需要以下三个步骤:
- 图像着色(自动or参考着色,对灰度图像进行上色)
- 超分辨率(用SISR单图像超分辨率方法,学习非线性映射)
- 下采样(超分的放大倍数是固定的,要让图像达到适当的分辨率,适应不同的设备)
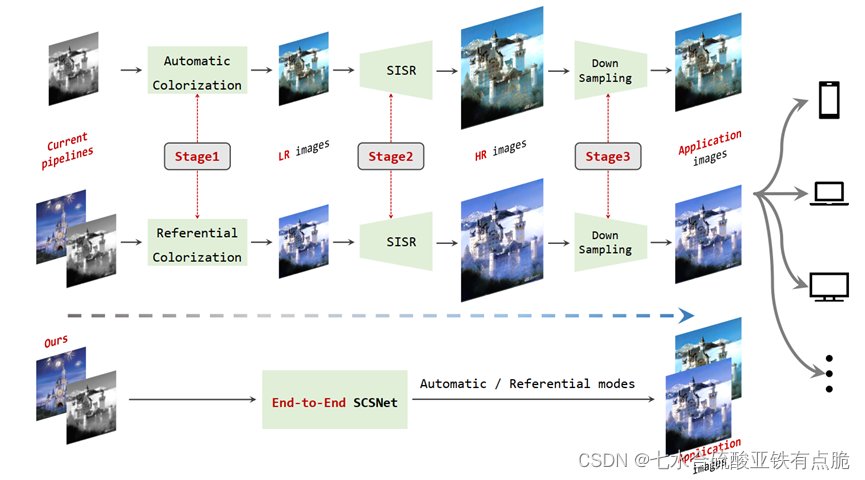
缺点: 冗余、不高效
理由: - 图像着色和超分辨率能够使用一个统一的网络共享一些共同特征
- 超分过程中的放大倍数是固定的,为了适应具体设备需要下采样,在这个过程中存在冗余计算。
因此提出SCSNet,能够通过一个统一的网络同时实现图像着色和超分任务。
主要分为2个分支。
- 着色分支
分为自动模式和参考模式,学习如何从给定的灰度图像中预测2个缺失的通道信息。
参考模式需要额外的参考图像,提供可控的参考语义信息。关键点:如何将参考图像中的颜色信息合并到源图像中。
作者设计了PVCAttn模块(一个即插即用的【阀门金字塔交叉注意力模块】),用来聚合源图像和参考图像之间的颜色特征信息。 - 超分分支
学习从LR图像重建出HR图像。
作者提出了CPM(连续像素映射)模块,实现对图片的连续放大。

重点:SCSNet、PVCAttn模块(聚合源图像到参考图像的颜色特征信息)、CMP模块(实现图片连续放大)
2 Method
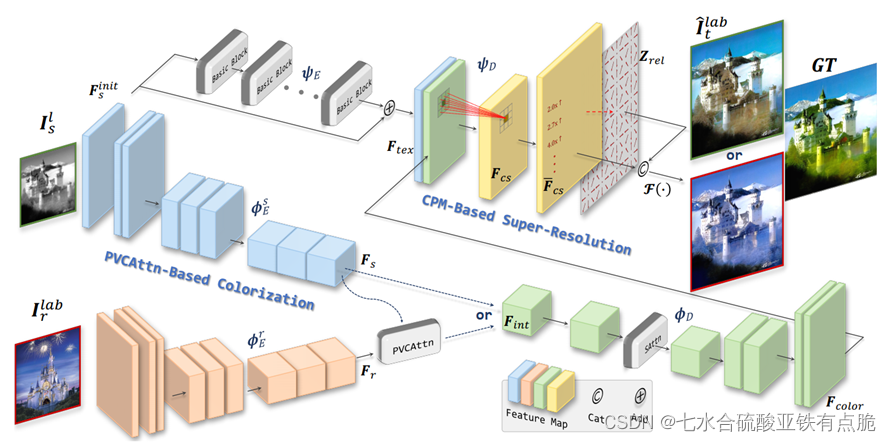
初始卷积,增加灰度图像的通道维数1->64
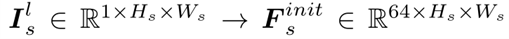
着色分支:
- 提取深度特征(参考图像、原始图像):
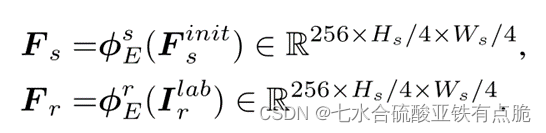
- PVCAttn模块:聚合源图像和参考图像的色彩特征
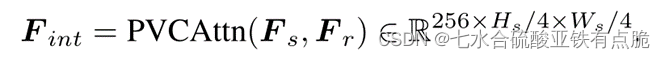
- faiD:通过自注意力+卷积,恢复原始分辨率。
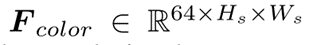
超分辨率分支:
FaiE:从Finit提取纹理特征,加上残差图像得到Ftex。通过几个basic block(2卷积层+一个跳跃操作)
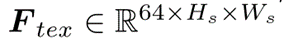
3×3卷积聚合Ftex和Fcolor,生成Fcs:
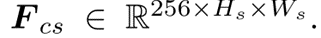
Fcs进入CMP模块,生成放大后的特征Fcs-
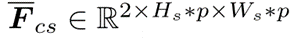
通过映射函数F,生成着色、超分的目标图像
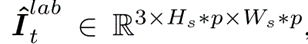
经过标注后的图,仅供参考:
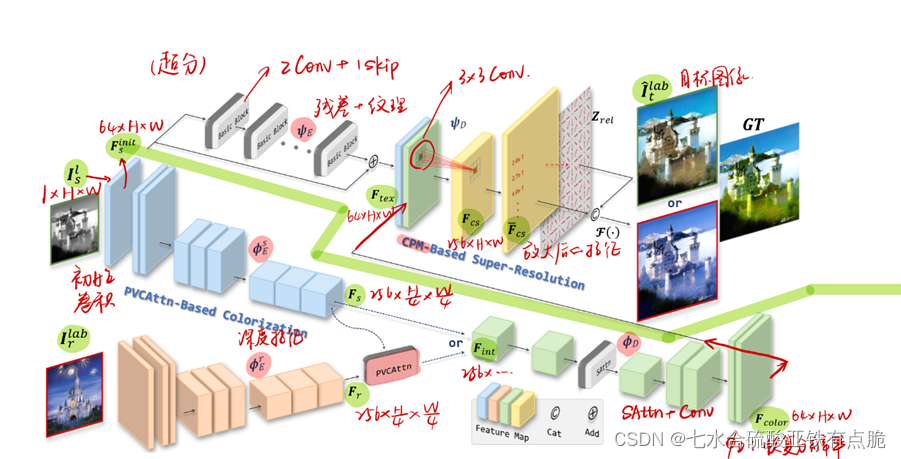
2.1 Pyramid Valve Cross Attention
VCAttn阀门交叉注意力模块:
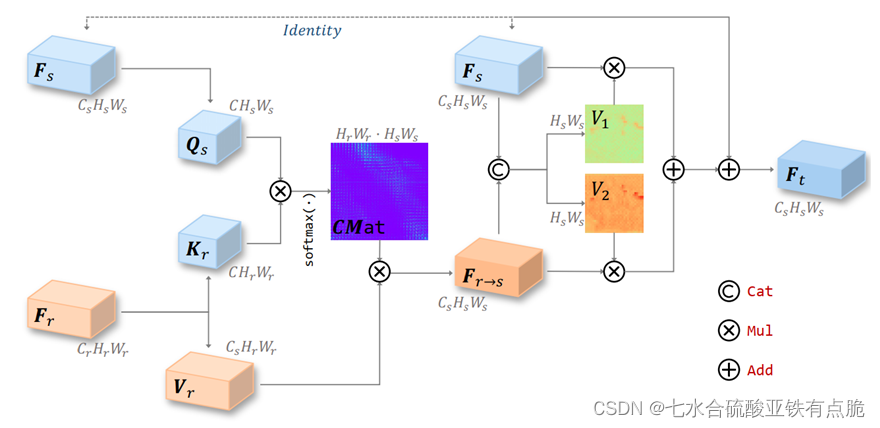
目的: 聚合参考特征Fr到源图像特征Fs上。
从Fs卷积提取Qs,Fr提取Kr和Vr,QK计算相关矩阵(矩阵相乘+softmax)得到CMat。
CMat和Vr相乘得到Fr-s,和Fs做连接,通过1×1卷积和sigmoid函数获得两个阀门映射V1和V2,用于控制Fs和Fr-s的信息流量。之后相乘,相加,加上Fs得到输出。
PVCAttn金字塔阀门交叉注意力模块
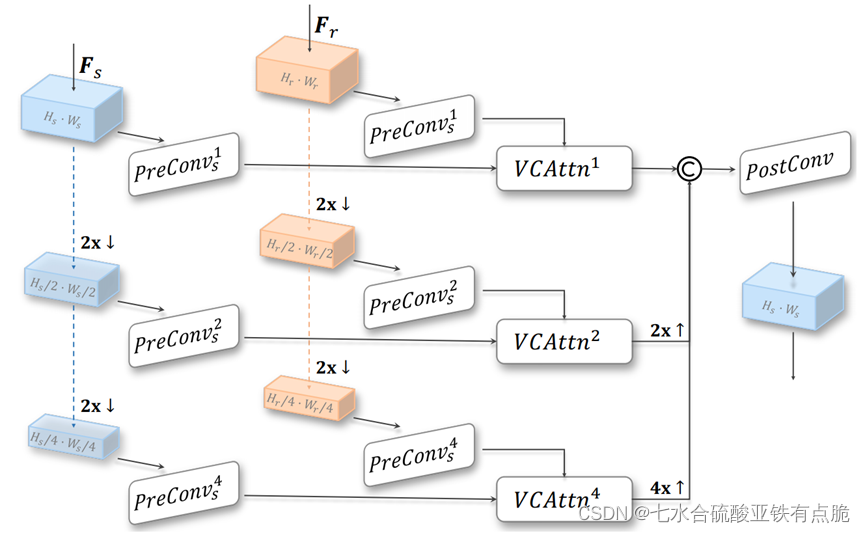
是对VCAttn的改进。
Fs和Fr分别做两次下采样,进入预卷积,然后送入相应的VCAttn模块。
VCAttn模块的输入输出的大小一致,所以对于下采样过的,还需要上采样,最后连接,通过后卷积得到最终输出Fint。
2.2 Continuous Pixel Mapping(CPM)
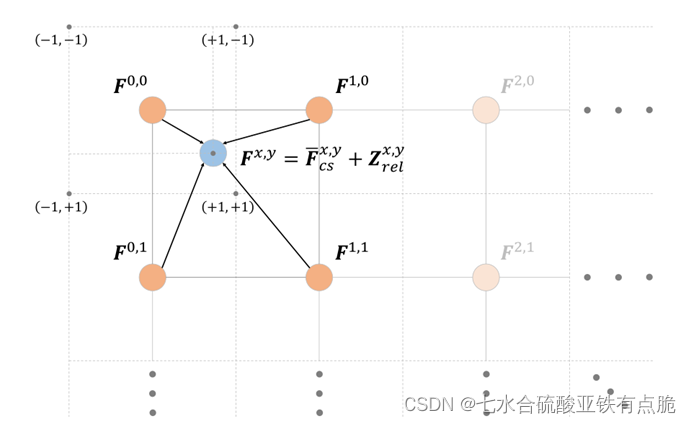
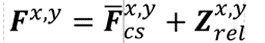
对一个点的特征,分为2部分。
- 一部分是:
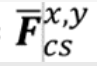
把目标图像中的这个点,放到原始分辨率图像中,离他最近的四个像素块(的中心点),做双线性插值,获得主要特征Fcsxy- - 另一部分
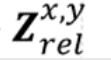
局部坐标特征Z,描述连续局部空间信息。

Z的正负,标识相对位置(左上,右下) - 最后,使用连续像素映射函数:
把特征映射到目标图像Ilab。
【补充理解】
以上部分,是第一次阅读的理解。词不达意,想来是没理解清楚,自己也没说服自己。
下面补充部分来自大佬理解,本人加入自己的理解后整理成文字得到。这部分仍存在争议,如有不同意见想法欢迎讨论。
-
Fcs:高分图像中,所求点的像素值。
由原低分辨率图像中的,四个点(橘色),即所求点(蓝色)的周围四个点,进行双线性插值,由已知x,y和像素值的四个点,求出蓝色点(已知x,y)的像素值。 -
Zrel:相对位置信息。是要求出,蓝色点(所求的高分图像中的某个已知x,y的特定点),与跟它最近的橘色点(原LR图像中的点,此处例子中离蓝色点最近的是F0,0),的相对位置信息。
mod操作是为了让x固定到某一个方块(像素块)中,/x(unit)是做一个归一化,此时也可以表征相对位置,但是表征的相对位置,是相对于一个像素块中的左上角,的位置(-1,-1)。
此时的计算结果,范围是(0,1)。
*2-1是对整个结果区间做一个拉伸+偏移,使最后的结果区间落在(-1,-1)。几何上的角度理解,就是此时表征的相对位置信息,是相对于像素块的中心点,也就是左上角的方块中的F0,0这个点。
这样一来,Zrel就可以表征蓝色点相对于F0.0这个点的相对位置(符号表示方向,绝对值表示大小) -
Fxy=Fcs+Zrel=像素信息+相对位置信息
此外,因为高分图像中的坐标,可以通过LR图像进行无限的线性插值得到,所以理论上可以进行无限倍数的放大,所以可以实现文中提到的“连续放大”,即Continuous Pixel Mapping。
另外,p(放大倍数)只在CPM模块出现。也就是,对于要放大不同倍数p1/p2的两个任务,我的理解是网络不需要重新从头训练。因为前面提取的特征都是一样的,只需要重新进CPM模块,进行不同次数的插值就可以,假设p1<p2,已经生成了p1的图像的情况下,可以在p1倍数的基础上再增加插值精度,就可以生成p2放大倍数的HR图像,不需要从头开始训练网络。
2.3 Objective Functions

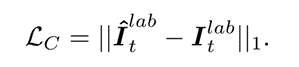
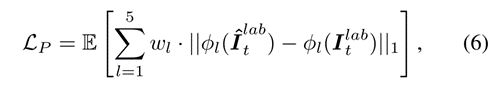
fai:在第一层卷积中提取的激活映射;
w是第一层的权重(把生成图像和原图扔卷积,加权求和最后期望)
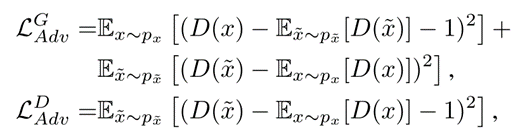
其中G和D是GAN中的generator和discriminator对应的损失。
3 Experiment
数据集: ImageNet、CelebA-HQ、 Flowers、 Bird、 COCO
处理: 删除数据集中,小于80K且颜色变化较小的图像。ImageNet-C
评价指标: PSNR峰值信噪比、SSIM结构相似性
FID: 衡量两个图象的特征向量之间的距离,能够表示生成图像的多样性和质量。FID越小,生成图像与真实图像越接近,则图像多样性越好,质量也越好。
Image ColorfulNess: 色彩丰富度。越大说明色彩越丰富。
定性效果:

对ColTran,将输入的灰度HR图像降低到与其他方法相同的分辨率,记为ColTran-LR。
-LR之后的图像较模糊。
定量分析:
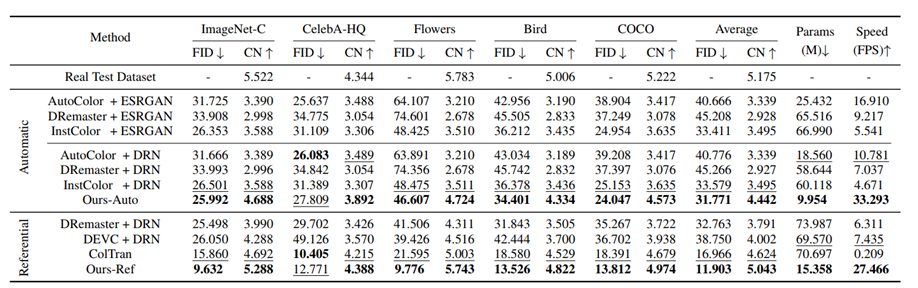
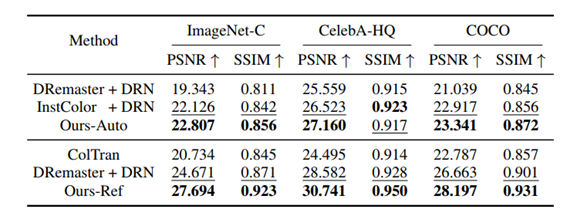
- 自动模式:ESRGAN vs DRN,说明不同超分方法差别不大,故选择了SOTA的DRN实验。
- 参考模式效果比自动模式更好。
- 本文中方法CN最大,说明色彩丰富度高,说明本文的方法可以更好的捕捉颜色信息。
- FID最小,说明生成的图像和真实图像分布更一致。
- 参数最少、运行速度最快。
(圆圈大小表示参数量)
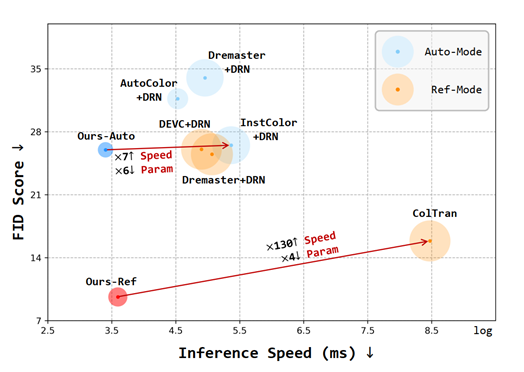
人类感受实验:
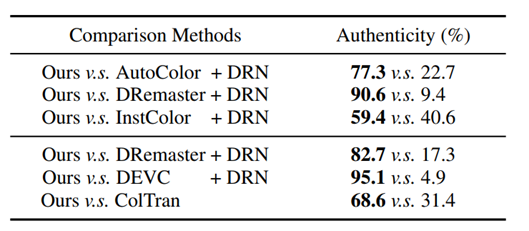
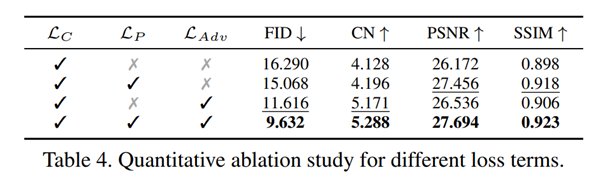
4 Ablation study
损失函数: 应用所有损失项,效果最好。
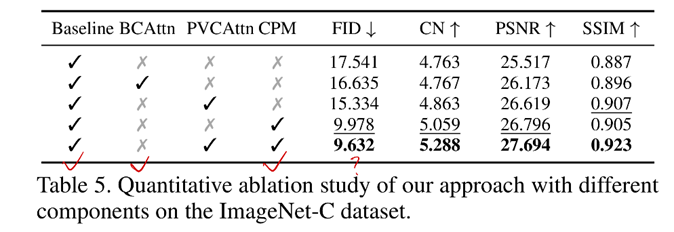
网络结构:
BCAttn是基础交叉注意力模块,去掉了阀门和金字塔。
BCAttn效果不如PVCAttn,所以BCAttn和CPM的组合意义不大,没做?
CPM的效果很好。
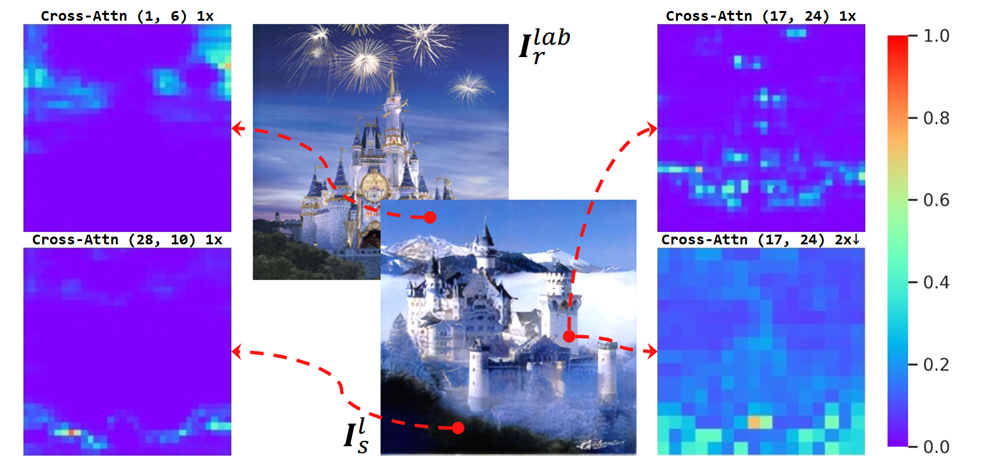
PVCAttn的可解释性:
PVCAttn的作用:匹配相似的语义信息。
左边:不同位置的注意力;右边:同一个位置的金字塔注意力。
可视化的注意力图表明,用PVCAttn处理后的图像各个位置更关注语义相似的区域;
原来的低分辨率特征图中的位置更关注平均区域。
连续放大生成目标图像可视化:
不同分辨率都具有一致的颜色稳定性;
相邻图像具有平滑的过渡;

5 Conclusion
- SCSNet(端到端)完成同时着色和超分的任务。
- 设计了PVCAttn模块(有效聚集源图像和参考图像之间的颜色特征信息)+CPM(生成任意放大率的目标图像)
Reference
【深度理解】如何评价GAN网络的好坏?IS(inception score)和FID(Fréchet Inception Distance)